在MySQL 查詢 語句中,允許使用 GROUP BY 子句對結果分組。
GROUP BY文法:
select 分組函數, 列(要求在group by 子句後面)from 表名【where 條件】group by 分組的列【order by 子句】
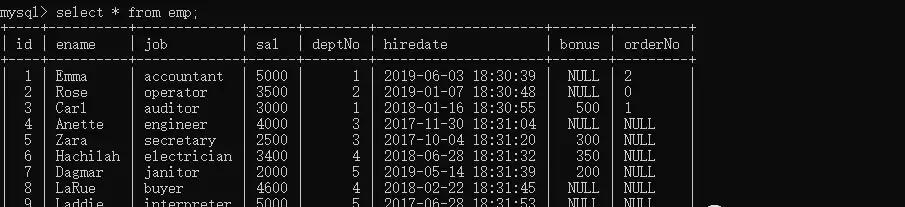
準備一個表,和一些資料。員工表,表名emp,包含姓名(ename)、工作(job)、工資(sal)、 部門編号(deptNo)等字段。
CREATE TABLE `emp` ( `id` int(255) NOT NULL AUTO_INCREMENT, `ename` varchar(255) DEFAULT NULL, `job` varchar(255) DEFAULT NULL, `sal` int(11) DEFAULT NULL, `deptNo` int(11) DEFAULT NULL, `hiredate` datetime NOT NULL, `bonus` int(11) DEFAULT NULL, `orderNo` varchar(255) DEFAULT NULL, PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=11 DEFAULT CHARSET=utf8
準備好的一些測試資料
簡單分組
假設有一個需求:查詢每個部門的員勞工數。
使用count函數可以查詢個數,select count(*) from emp 将整個表看作一組,傳回整個表的行數。此時要求查詢每個部門的員勞工數,意味着要在整個emp表再按部門分組,有幾個部門就分幾個小組,然後再統計部門的人數。
可以這樣寫:
mysql> select count(*),deptNo from emp group by deptNo;+----------+--------+| count(*) | deptNo |+----------+--------+| 2 | 1 || 2 | 2 | | 2 | 3 | | 2 | 4 | | 2 | 5 | +----------+--------+
deptNo是部門編号,是以以此列作為分組的列。前面是員工數量,後面是部門編号。
再如,查詢每個部門的平均工資
mysql> select avg(sal),deptNo from emp group by deptNo;+-----------+--------+| avg(sal) | deptNo |+-----------+--------+| 4000.0000 | 1 || 4100.0000 | 2 || 3250.0000 | 3 || 4000.0000 | 4 || 3500.0000 | 5 |+-----------+--------+
有條件的分組查詢
1、比如第一個問題改一下,查詢每個部門有獎金的員勞工數(即bonus這列,其有兩個值,null和非null)
此時可以這樣查
mysql> select count(*),deptNo from emp where bonus is not null group by deptNo;+----------+--------+| count(*) | deptNo |+----------+--------+| 1 | 1 || 1 | 2 || 1 | 3 || 1 | 4 || 1 | 5 |+----------+--------+
獎金是篩選條件,條件涉及的字段bonus是在emp表中,也就是原始表中,此時就可以在where中使用,并且在group by 之前。
2、再有一個問題,要求查詢員勞工數大于1的部門。
第一步,我們可以先查出每個部門的人數
第二步,根據第一步的結果上進行篩選哪個部門員勞工數大于1
查詢部門員勞工數select count(*),deptNo from emp group by deptNo;
此時我們發現,根據原始表的字段,我們無法找出哪個部門的員勞工數大于1,隻能是根據分組之後的結果集進行篩選,此時添加條件不能在group by之前,否則會報錯。
mysql> select count(*),deptNo from emp where count(*) > 1 group by deptNo;ERROR 1111 (HY000): Invalid use of group function
是group by分組之後再篩選,是以條件也在group by 子句後面,也不能再用where,而是用關鍵詞having
mysql> select count(*),deptNo from emp group by deptNo having count(*) > 1;+----------+--------+| count(*) | deptNo |+----------+--------+| 2 | 1 || 2 | 2 || 2 | 3 || 2 | 4 || 2 | 5 |+----------+--------+
篩選條件在分組前添加還是在分組後添加,可以看它能不能使用原始表中的列來确定。
分組前 原始表字段,在group by前面,用where關鍵詞,分組後 分組的結果集,在group by後面,用having關鍵詞。
如果用分組函數作條件,肯定是在group by後面。
優先使用分組前篩選。
按函數分組或者表達式分組
如按員工姓名的長度進行分組,查詢每個長度的員勞工數。
mysql> select count(*),length(ename) from emp group by length(ename);+----------+---------------+| count(*) | length(ename) |+----------+---------------+| 4 | 4 || 1 | 5 || 3 | 6 || 1 | 7 || 1 | 8 |+----------+---------------+
按多個字段分組
如按部門、工作分組,查詢員工數量
mysql> select count(*),deptNo,job from emp group by deptNo,job;+----------+--------+-------------+| count(*) | deptNo | job |+----------+--------+-------------+| 1 | 1 | accountant || 1 | 1 | auditor || 1 | 2 | cashier || 1 | 2 | operator || 1 | 3 | engineer || 1 | 3 | secretary || 1 | 4 | buyer || 1 | 4 | electrician || 1 | 5 | interpreter || 1 | 5 | janitor |+----------+--------+-------------+
有多個字段,加在group by後面用逗号分隔即可,兩者值相同的字段才會分到一組中。字段在分組的順序随意,沒有要求。
添加排序
如查詢每個部門的平均工資,按照降序排序
mysql> select avg(sal),deptNo from emp group by deptNo order by avg(sal) desc;+-----------+--------+| avg(sal) | deptNo |+-----------+--------+| 4100.0000 | 2 || 4000.0000 | 4 || 4000.0000 | 1 || 3500.0000 | 5 || 3250.0000 | 3 |+-----------+--------+
如果沒有limit,order by 子句一定在查詢語句的最後。
![java8 多個字段分組_SQL多個Join on 和Where間的執行順序(nest loop join機制)[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)