一、purge
- delete和update操作可能并不直接删除原有的資料
例如
delete from t where a=1;
- 前一篇文章示範案例中
- 對表t執行下面的SQL語句。其中a字段為聚集索引,b字段為輔助索引
- 對于上述的delete操作,通過前面關于undo log的介紹已經知道僅是将主鍵列等于1的記錄的delete flag設定為1,記錄并沒有删除,即記錄還是存在于B+樹中
- 其次,對于輔助索引上a=1,b=1的記錄同樣沒有做任何處理,甚至沒有産生undo log
- 而真正删除這樣記錄的操作其實被“延時”了,最終在purge操作中完成
- purge用于最終完成delete和update操作。這樣設計是因為InnoDB存儲引擎支援MVCC,是以記錄不能在事務送出時立即進行處理。這時其他事務可能正在引用這行,故InnoDB需要儲存記錄之前的版本。而是放可以删除該條記錄通過purge來進行判斷。若該行記錄已不被任何其他事務引用,那麼就可以進行真正的delete操作。可見,purge操作時清理之前的delete和update操作,将上述操作“最終”完成。而實際執行的操作為delete操作,清理之前行記錄的版本
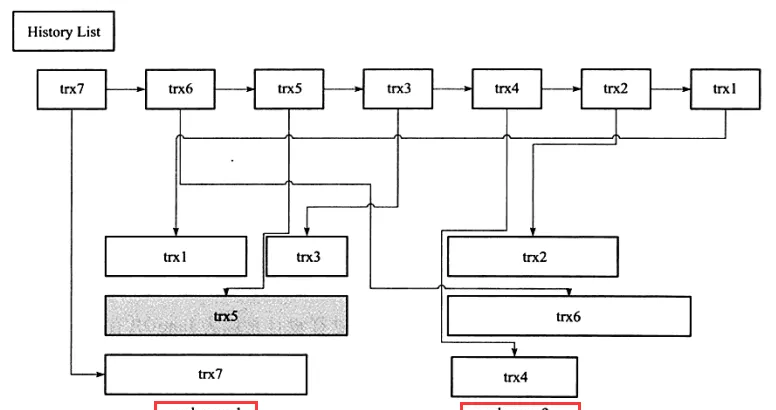
History list
- 在前面介紹了,為了節省空間,InnoDB的undo log設計是這樣的:一個頁上允許多個事務的undo log存在。雖然這不代表事務在全局過程中的送出順序,但是後面的事務産生的undo log總在最後
- 此外,InnoDB還有一個history清單,它根據事務送出的順序,将undo log進行連結。如下面一種情況:
- 在圖中:
- history list表示按照事務送出的順序将undo log進行組織
- 在InnoDB的設計中,先送出的事務總在後端
- undo page存放了undo log,由于可以重用,是以一個undo page中可能存放了多個不同僚務的undo log
- trx5的灰色陰影表示該undo log還被其他事務引用
MySQL(InnoDB剖析):41---事務之(事務的實作:purge、group commit) purge的過程
- 以上圖為例
- 在執行purge的過程中:
- InnoDB存儲引擎首先将history list中找到第一個需要被清理的記錄,這裡為trx1
- 清理之後InnoDB會在trx1的undo log所在的頁(undo page1)中繼續尋找是否存在可以被清理的記錄,這裡會找到事務trx3
- 接着找到trx5,但是發現trx5被其他事務所引用而不能清理,故去再次去history list中查找
- 發現這時最尾端的記錄為trx2,接着找到trx2所在的頁,然後依次再把事務trx6、trx4的記錄進行清理
- 由于undo page2中所有的頁都被清理了,是以該undo page2可以被重用
- InnoDB這種先從history list中找undo log,然後再從undo page中找undo log的設計模式是為了避免大量的随機讀取操作,進而提高purge的效率
innodb_purge_batch_size參數
- 該全局動态參數用來設定每次purge操作需要清理的undo page數量
- 預設值:
- 在InnoDB1.2之前,該參數的預設值為20
- 從InnoDB1.2版本開始,該參數的預設值為30
- 通常來說,該參數設定的越大,每次回收的undo page就越多,這樣可供重用的undo page就越多,減少了磁盤存儲空間與配置設定的開銷
- 不過,若該參數設定的太大,則每次需要purge處理更多的undo page,進而導緻CPU和磁盤IO過于集中于對undo log的處理,使性能下降
- 是以對該參數的調整需要有經驗的DBA來操作,并且需要長期觀察資料庫的運作狀态
- MySQL資料庫手冊說:普通使用者不需要調整該參數
innodb_max_purge_lag參數
- 當InnoDB的壓力非常大時,并不能高效地進行purge操作,那麼history list的長度會變得越來越長
- 該全局動态參數用來控制history list的長度
- 參數的設定:
- 若長度大于該參數,其會“緩慢”DML的操作
- 該參數預設值為0:表示不對history list做任何限制
- 當history list長度大于該參數時,就會延緩DML的操作,其延緩的算法為:
- delay的機關是毫秒

MySQL(InnoDB剖析):41---事務之(事務的實作:purge、group commit)
- 此外,需要注意,delay的對象是行,而不是一個DML操作。例如當一個update操作需要更新5行資料時,每次資料的操作都會被delay,故總的延時時間為5*delay
- 而delay的統計會在每一次purge操作完成後,重新進行計算
innodb_max_purge_lag_delay參數
- InnoDB 1.2版本引入了該全局動态參數,用來控制delay的最大毫秒數
- 就是當上述計算得到的delay值大于該參數時,将delay設定為innodb_max_purge_lag_delay,避免由于purge操作緩慢導緻其他SQL線程出現無限制的等待
二、group commit
為什麼設計group commit?
- 若事務為非隻讀事務,則每次事務送出時需要進行一次fsync操作,以此保證重做日志都已經寫入磁盤。當資料庫發生當機時,可以通過重做日志進行恢複。雖然固态硬碟的出現提高了磁盤的性能,然而磁盤的fsync性能是有限的
- 為了提高磁盤fsync的效率,目前資料庫都提供了group commit的功能,即一次fsync可以重新整理確定多個事務日志被寫入檔案
group commit的原理
- 對于InnoDB來說,事務送出時會進行兩個節點的操作:
- ①修改記憶體中事務對應的資訊,并且将日志寫入重做日志緩沖
- ②調用fsync将確定日志都從重做日志緩沖寫入磁盤
- 原理:
- 步驟②相對步驟①是一個較慢的過程,這是因為存儲引擎需要與磁盤打交道
- 但當有事務執行步驟②時,其他事務可以進行步驟①的操作,正在送出的事務完成送出操作後,再次進行步驟②時,可以将多個事務的重做日志通過一次fsync重新整理到磁盤,這樣就大大地減少了磁盤的壓力,進而提高了資料庫的整體性能
- 對于寫入或更新較為頻繁的操作,group commit的效果尤為明顯
group commit的功能會失效(prepare_commit_mutex鎖)
- 然而在InnoDB 1.2版本之前,在開啟二進制日志後,InnoDB存儲引擎的group commit功能會失效,進而導緻性能的下降。并且線上環境多實用replication環境,是以二進制日志的選項基本都為開啟狀态,是以這個問題尤為顯著
- 導緻這個問題的原因是在開啟二進制日志後,為了保證存儲引擎層的事務和二進制日志的一緻性,兩者之間使用了兩階段事務,其步驟如下:
- ①當事務送出時InnoDB存儲引擎進行prepare(準備)操作
- ②MySQL資料庫上層寫入二進制日志
- ③InnoDB存儲引擎層将日志寫入重做日志檔案
- a修改記憶體中事務對應的資訊,并且将日志寫入重做日志緩沖
- b調用fsync将確定日志都從重做日志緩沖寫入磁盤
- 一旦步驟②中的操作完成,就確定了事務的完成,即使在執行步驟③時資料庫發生了當機。
- 此外需要注意的是:
- 每個步驟都需要進行一次fsync操作才能保證上下兩層資料的一緻性
- 步驟②的fsync由參數sync_binlog控制,步驟③的fsync由參數innodb_flush_log_at_trx_commit控制
- 是以,上述整個過程如下圖所示:
MySQL(InnoDB剖析):41---事務之(事務的實作:purge、group commit)
- group commit為什麼失效:
- 為了保證MySQL資料庫上層二進制日志的寫入順序和InnoDB層的事務送出順序一緻,MySQL資料庫内部使用了prepare_commit_mutex這個鎖
- 但是在啟用這個鎖之後,步驟③的步驟a不可以在其他事務執行步驟b時進行,進而導緻了group commit實作
- 然而,為什麼需要保證MySQL資料庫上層二進制日志的寫入順序和InnoDB層的事務送出順序一緻呢?
- 這是因為備份及恢複的需要,例如通過工具xtrabackup或者ibbackup進行備份,并用來建立replication,如下圖所示:
- 可以看到若通過線上備份進行資料庫恢複來重建立立replication,事務T1的資料會産生丢失。因為在InnoDB存儲引擎層會檢測事務T3在上下兩層都完成了送出,不需要再進行恢複。是以通過鎖prepare_commit_mutex以串行的方式保證順序性,然而這會使group commit無法生效,如下圖所示:
解決group commit的失效辦法(BLGC)
- 這個問題最早在2010年的MySQL資料庫大會中提出,Facebook MySQL技術組,Percona公司都提出解決辦法。最後由MariaDB資料庫的開發人員Kristian Nirlsen完成了最紅的“完美”解決方案。在這種情況下,不但MySQL資料庫上層的二進制日志寫入是group commit的,InnoDB存儲引擎層也是group commit的。此外還移除了原先的鎖prepare_commit_mutex,進而大大提高了資料庫的整體性。MySQL 5.6采用了類似的實作方式,并将其稱為Binary Log Group Commit(BLGC)
- BLGC的實作方式是将事務送出的過程分為幾個步驟來完成,如下圖所示:
- Flush階段:将每個事務的二進制日志寫入記憶體中
- Sync階段:将記憶體中的二進制日志重新整理到磁盤。若隊列中有多個事務,那麼僅一次fsync操作就完成了二進制日志的寫入,這就是BLGC
- Commit階段:leader根據順序調用存儲引擎層事務的送出,InnoDB存儲引擎本就支援group commit,是以修複了原先由于鎖prepare_commit_mutex導緻group commit失效的問題
- 當一組事務在進行Commit階段時,其他新事物可以進行Flush階段,進而使group commit不斷生效。當然group commit的效果由隊列中事務的數量決定,若每次隊列中僅有一個事務,那麼可能效果和之前差不多,甚至會更差。但當送出的事務越多時,group commit的效果就越明顯,資料庫性能提升也就越大
binlog_max_flush_queue_time參數
- 該參數控制Flush階段中等待的時間,即使之前的一組事務完成送出,目前一組事務也不馬上進入Sync階段,而是至少需要等待一段時間
- 這樣做的好處是group commit的事務數量越多,然而這也可能會導緻事務的響應時間變慢
- 該參數的預設值為0,且推薦設定依然為0。除非使用者的MySQL資料庫系統中有着大量的連接配接(如100個連接配接),并且不斷地進行事務的寫入或更新操