1. 說明
之前參加的都是往期賽,新人賽,這是第一人參加正式比賽,先談談感受。 天池精準醫療已開賽一周,排行搒上大家整體的誤差從0.9提升到0.8,也就是說一開始0.88分還名列前茅,一周之後,這個分數早已榜上無名了。比想象中激烈,我也是反複出榜(榜單僅列出前一百名),偶爾僥幸進入前十,時刻準備着再次被踢出排行榜, 也算是體驗了一把逆水行舟的樂趣。 很多時候反複實驗仍然提高不了成績,感覺完全沒有方向,大家都在摸索,和一邊做一邊對照正确答案,确實不一樣。也有一些算法,我知道它,卻不知道什麼時候用它。在此也記錄一下經驗教訓。
2. 特征工程
開始的時候做了一些特征工程,包括填充缺失值,為SVM計算排序特征,還找到化驗單各項名額的正常的範圍值,根據各項名額正常與否做離散特征,根據名額的合格數量計算統計特征等等。但相對于簡單地判斷中值,均值,效果都沒有明顯地提高。後來做了标準化,效果挺明顯的,而且轉換後缺失值就可以直接填0了。 也分析了一下,為什麼正常範圍沒起到作用,化驗之後不都是看這個嗎?後來在肉眼觀察血糖各個檔位特征統計值的時候,發現血糖高者某些生化名額和整體均值有明顯差異,但仍在正常範圍之内,另外在不正常的情況下,內插補點的大小也很重要,是以這種一刀切的方法好像不行。
3. 分析結果分布
本題預測結果是血糖值,大緻分布如下:
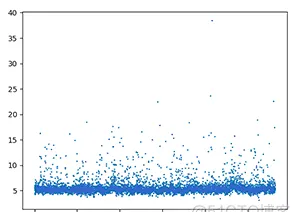
我們把它稱為大地和星空問題,大地指的是5-6之間的區域,80%以上的血糖都分布在這個區域,此區域也是容易被預測的,而上面星星點點的是星空,雖然數量不多,卻起着決定性的作用。這還要從評分公式說起:

由公式可知,評估名額是均方誤差MSE的二分之一,其中m是執行個體個數,y’是預測值,y是實際值,關鍵是右上角的平方,它進一步放大了大的誤內插補點。拿測試集來說,其中有1000個執行個體,即m=1000,如果把某個執行個體5.5預測成5,它對誤差的貢獻是(5-5.5)^2 /2000=0.000125,如果把20預測成5,誤差為(5-20)^2 /2000=0.1125,它是前者的900倍,這個距離可以在排行榜拉開好幾百名的差距了。這麼看來,那些小的差異可以先不管。 再來看看訓練集中血糖的分布:
一般把大于6.1的認為是高血糖,大于11.1的認為是糖尿病。在訓練集提供的5642個執行個體中,大于6.1的個,大于11.1的97個。如果測試集的分布與訓練集一緻,大約有17個執行個體血糖在11.1以上。
但是在讨論群裡面很多人對測試集的預測都沒有超過10的,按測試資料估計,隻占總人數1.7%的糖尿病人的誤差就占了總誤差的将近一半。
再考慮這個題目要解決什麼問題,如果根本測不出誰是糖尿病患者,隻是糾結正常範圍内的小誤差,這算法就沒意義了。
一開始我的計算結果也是這樣的,這可能是源于大家都在使用Boost疊代改進算法,它的原理是不斷疊代,并在每次計算時加大前一次算錯執行個體的權重,可以想見,本題中80%多都是正常血糖值,于是它模型拉向了均值,大量分枝在5附近做細小切分,後來試了等深分箱,也沒什麼用。 基于這個原因,我嘗試修改了算法的損失函數,評價函數,執行個體權重等等,但效果都太好,這也可能因為我個人水準有限。後來直接把回歸問題改成了先分類後回歸,效果還可以。
4. 問題規模
本題是一個小規模資料的問題,因為資料量小,經常引發線上與線下評分不一緻,而且容易造成過拟合,以及和測試集相關的作弊問題。不過即使資料再少,也有20W+的資料,人的大腦也處理不了。下面來看看不同資料量與算法選擇的關系,從另一角度分析一下星空問題的解法。假設下面三種情況:
第一種情況:從5000個執行個體中找到包含5個執行個體的類别。(血糖超20)
第二種情況:從5000個執行個體中找到包含100個執行個體的類别。(血糖超11.1,尿糖病)
第三種情況:從5000個執行個體中找到包含1000個執行個體的類别。(血糖超6.1,不正常)
第一種情況下,類中隻有5個執行個體,執行個體太少,無法取均值,因為隻要其中一值太大或太小,都會嚴重影響均值。此時,每個執行個體都很重要,可以考慮使用距離類的算法,比如K近鄰。另外,可以檢視這些執行個體中各個特征與均值的差異,進而建構規則。
第二種情況下,類中有100個執行個體,占整體的2%,這些執行個體之間可能有一些重合的特點,可以統計的一些共同特征,一般不止一種模式,可嘗試聚類,找到一些規律。也可以用類的統計特征和整體的統計特征相比較,或者考慮貝葉斯類的算法。 第三種情況下,類中有1000個執行個體,占整體20%,這也是最常見的一種情況,它不再是從正常中找異常,而是從正常中找正常,基本屬于大地問題了,有1000個執行個體,量也足夠大,必然涵蓋了很多種情況,可以考慮分類樹比如GBDT類型的算法。
以上三種情況都是從整體中選出少數執行個體,裡面有一個隐含的特征非常重要:整體的均值,它的作用就像是人的常識一樣。
5. 算法
選擇算法上有個誤區:非此即彼。我們希望把每個執行個體都正确分類,但這往往是不可能的。比如在本題的情況下,可以先用GBDT的算法做一個baseline。在改進的過程中,選擇一些規則類的算法。
這裡指的規則,比如說,我們隻關心血糖高于11.1的(正例),就可以從樹分類器上切出一些隻含有正例的分枝,而并不關注樹的其它部分,進而生成一套規則集。預測時,符合規則的按糖尿病處理,不合規則的再用baseline預測。