如何實作 MySQL 的讀寫分離?
其實很簡單,就是基于主從複制架構,簡單來說,就搞一個主庫,挂多個從庫,然後我們就單單隻是寫主庫,然後主庫會自動把資料給同步到從庫上去。
MySQL 主從複制原理的是啥?
主庫将變更寫入 binlog 日志,然後從庫連接配接到主庫之後,從庫有一個 IO 線程,将主庫的 binlog 日志拷貝到自己本地,寫入一個 relay 中繼日志中。接着從庫中有一個 SQL 線程會從中繼日志讀取 binlog,然後執行 binlog 日志中的内容,也就是在自己本地再次執行一遍 SQL,這樣就可以保證自己跟主庫的資料是一樣的。
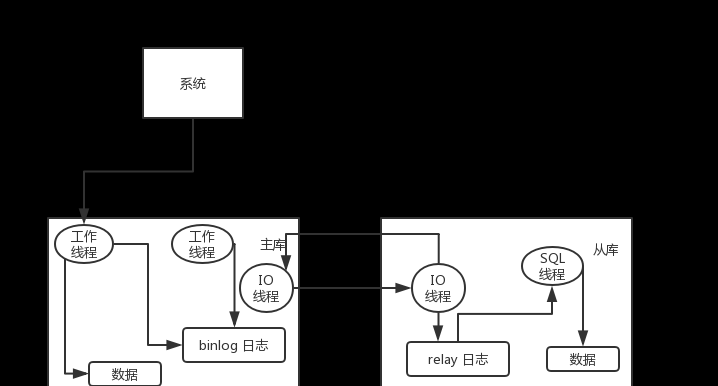
這裡有一個非常重要的一點,就是從庫同步主庫資料的過程是串行化的,也就是說主庫上并行的操作,在從庫上會串行執行。是以這就是一個非常重要的點了,由于從庫從主庫拷貝日志以及串行執行 SQL 的特點,在高并發場景下,從庫的資料一定會比主庫慢一些,是有延時的。是以經常出現,剛寫入主庫的資料可能是讀不到的,要過幾十毫秒,甚至幾百毫秒才能讀取到。
而且這裡還有另外一個問題,就是如果主庫突然當機,然後恰好資料還沒同步到從庫,那麼有些資料可能在從庫上是沒有的,有些資料可能就丢失了。
是以 MySQL 實際上在這一塊有兩個機制,一個是半同步複制,用來解決主庫資料丢失問題;一個是并行複制,用來解決主從同步延時問題。
這個所謂半同步複制,也叫
semi-sync
複制,指的就是主庫寫入 binlog 日志之後,就會将強制此時立即将資料同步到從庫,從庫将日志寫入自己本地的 relay log 之後,接着會傳回一個 ack 給主庫,主庫接收到至少一個從庫的 ack 之後才會認為寫操作完成了。
所謂并行複制,指的是從庫開啟多個線程,并行讀取 relay log 中不同庫的日志,然後并行重放不同庫的日志,這是庫級别的并行。
MySQL 主從同步延時問題(精華)
以前線上确實處理過因為主從同步延時問題而導緻的線上的 bug,屬于小型的生産事故。
是這個麼場景。有個同學是這樣寫代碼邏輯的。先插入一條資料,再把它查出來,然後更新這條資料。在生産環境高峰期,寫并發達到了 2000/s,這個時候,主從複制延時大概是在小幾十毫秒。線上會發現,每天總有那麼一些資料,我們期望更新一些重要的資料狀态,但在高峰期時候卻沒更新。使用者跟客服回報,而客服就會回報給我們。
我們通過 MySQL 指令:
show status 複制
檢視
Seconds_Behind_Master
,可以看到從庫複制主庫的資料落後了幾 ms。
一般來說,如果主從延遲較為嚴重,有以下解決方案:
- 分庫,将一個主庫拆分為多個主庫,每個主庫的寫并發就減少了幾倍,此時主從延遲可以忽略不計。
- 打開 MySQL 支援的并行複制,多個庫并行複制。如果說某個庫的寫入并發就是特别高,單庫寫并發達到了 2000/s,并行複制還是沒意義。
- 重寫代碼,寫代碼的同學,要慎重,插入資料時立馬查詢可能查不到。
- 如果确實是存在必須先插入,立馬要求就查詢到,然後立馬就要反過來執行一些操作,對這個查詢設定直連主庫。不推薦這種方法,你要是這麼搞,讀寫分離的意義就喪失了。