Python 的DataFrame 中,有幾種數值定位/取值方式
1. df.at()
2. df.iloc[]
3. df.loc[]
記憶點如下:
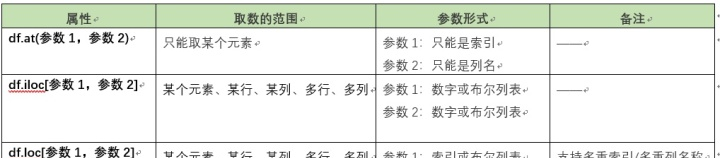
- 用于選取資料 : df2=df.loc[參數1,參數2]
- 用于指派 :df.loc[參數1,參數2]=1
如下一一進行參數解讀及示例
1. df.at(索引,列名)
- 該函數隻能取某一個元素的值
- 該函數采取, 行索引加列名的方式 進行定位
例子:
df.at(‘a’,’A’) 表示取索引為a,列名稱為A所對應的元素的值
2. df.iloc[參數1,參數2]
- 該函數可以取某個元素、某行、某列、多行、多列。
- 該函數采用,行号、列号的方式 或者 布爾清單的方式 進行定位。 參數隻能是數字或者布爾型
- 參數2可以省略, 表示取所有行;或者以“:”形式表示取所有列;
- 參數1不可以省略, 以“:”形式表示取所有列;
- 數字清單: 例如[1,3,5],表示取python行(列)順序上的第1行(列)、第3行(列)、第5行(列)[1]
- 布爾值清單: 例如[True,Flase, True,Flase, True,Flase],表示取為True的行(列), 布爾清單長度一定要跟行(列)的長度一緻。
- 單個數字 :例如5,表示取python行(列)順序上的第5行(列)
- 冒号分隔的開始行号和結束行号 :例如 3:5 ,表示取python行(列)順序上的第3行(列)至第4行(列) 【不包含python順序含義上的第5行(列)】
例子:
###取相應的行,列為所有的列df.iloc[2] 取第3行,取出後格式為Series(python的順序是從0開始的,0表示第1,2表示第3,3表示第4,以此類推)
df.iloc[[2]] 取第3行,取出後格式為DatFrame
df.iloc[2:3] 取第3行,取出後格式為DatFrame
df.iloc[2:4] 取
第3行至第4行,取出後格式為DatFrame
df.iloc[[2,4]] 取
第3行和第5行,取出後格式為DatFrame
df.iloc[[2,4,5]] 取第3行、第5行、第6行,取出後格式為DatFrame
df.iloc[[True,True,Flase,False,False,False]] 取為True所對應的行
###取相應的行,同時取相應的列 [行選取的參數,列選取的參數] 行和列參數形式均可以在4種參數表達形式中選擇,不互斥,也就是有16種組合的取值方式。df.iloc[2,3] 取第3行第4列的值(python的順序,2表示3行,3表示4列)
df.iloc[[0, 2], [1, 3]] 取第1行和第3行,然後再取第2列和第4列
df.iloc[2:5,3] 取第3行至第5行,再取第4列的值
df.iloc[:,3] 取第4列的值
df.iloc[2:5,3:6] 取第3行至第5行,再取第4列至第8列的值
df.iloc[[True,True,Flase,False,False,False],3:6] 取為True的行,再取第4列至第6列的值
df.iloc[[True,True,Flase,False,False,False],[True,True,Flase,False,False,False]] 取為True的行,再取為True的列
3. df.loc[參數1,參數2]
- 該函數可以取某個元素、某行、某列、多行、多列。
- 該函數可用于 查找多重索引或者多重列名 的的資料框。
- 該函數采用, 行索引、列名稱 的方式 或者 布爾清單 的方式 進行定位。
- 參數2可以省略, 表示取所有行;或者以“:”形式表示取所有列;
- 參數1不可以省略, 以“:”形式表示取所有列;
- 索引或者列名稱清單 :例如[1,3,5],表示取索引(列名稱)為1,3,5的行(列)
- 布爾值清單 :[True,Flase, True,Flase, True,Flase],表示取為True的行(列),但是清單長度一定要跟行(列)的長度一緻。
- 單個索引或者列名稱 :5,表示索引(列名稱)為5的行(列)
- 冒号分隔的開始索引(列名稱)和結束索引(列名稱) :3:5 表示取索引(列名稱)為3至5 【包含5】 的行(列),字元串就按照字元串的方式排序
例子:
###取相應的行,列為所有的列df.loc[2] 取索引為2的行,取出後格式為series
df.loc[[2]] 取索引為2的行,取出後格式為DatFrame
df.loc['a':'c'] 取索引為a至c的行,取出後格式為DatFrame,字元串就按照字元串的方式排序
df.loc[['a','b']] 取索引為a,和b的行,取出後格式為DatFrame
df.loc[[False, False, True]] 取值為True的行,(布爾清單的長度必須為dataframe的長度)
###取相應的行,同時取相應的列 [行選取的參數,列選取的參數] 參數有4種形式,行和列的選取參數均可以在4種形式中選擇,不互斥,也就是有16種組合的取值方式。df.loc[[False, False, True],['a','c']] 取值為True的行,再取列名稱為a和c的列(布爾清單的長度必須為dataframe的長度)
df.loc[['A','C'],'a':'c'] 取值索引值為A、C的行,再取列名稱為a至c的列(布爾清單的長度必須為dataframe的長度)
df.loc['A':'C','a'] 取值索引值A至C的行,再取列名稱為a的列(布爾清單的長度必須為dataframe的長度)
另外,df.loc[]支援取多重索引的值或者定位位置 ###取相應的行,列為所有的列 把(第一重索引,第二重索引)當做一個索引值來看,套用上面的同樣的規則; 把(第一重列名,第二重列名)當做一個列名來看,套用上面的同樣的規則;df.loc[(第一重索引,第二重索引)] 取索引為(第一重索引,第二重索引)的行,取出後格式為series
df.loc[[(第一重索引,第二重索引)]] 取索引為(第一重索引,第二重索引)的行,取出後格式為DatFrame
df2.loc[(a,'ii'):(c,'ii')] 取索引(a,'ii')至索引(c,'ii')的行
df2.loc[(a,'ii'):c] 取索引(a,'ii')至索引c的行,索引c的意思為所有第一重索引為c的值。
參考
- ^(python的順序是從0開始的,0表示第1,2表示第3,3表示第4,以此類推)