1 Storm介紹
Storm是由Twitter開源的分布式、高容錯的實時處理系統,它的出現令持續不斷的流計算變得容易,彌補了Hadoop批處理所不能滿足的實時要求。Storm常用于在實時分析、線上機器學習、持續計算、分布式遠端調用和ETL等領域。
在Storm的叢集裡面有兩種節點:控制節點(Master Node)和工作節點(Worker Node)。控制節點上面運作一個名為Nimbus的程序,它用于資源配置設定和狀态監控;每個工作節點上面運作一個Supervisor的程序,它會監聽配置設定給它所在機器的工作,根據需要啟動/關閉工作程序。Storm叢集架構如下圖所示:
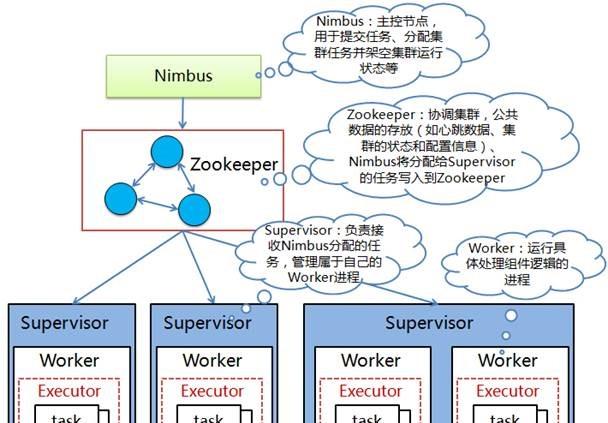
圖 1 Storm叢集架構
Storm叢集中每個元件具體描述如下:
l Nimbus:負責在叢集裡面發送代碼,配置設定工作給機器并且監控狀态,在叢集中隻有一個,作用類似Hadoop裡面的JobTracker。
l ZooKeeper:Storm重點依賴的外部資源,Nimbus、Supervisor和Worker等都是把心跳資料儲存在ZooKeeper上,Nimbus也是根據ZooKeeper上的心跳和任務運作狀況進行排程和任務配置設定的。
l Supervisor:在運作節點上,監聽配置設定的任務,根據需要啟動或關閉工作程序Worker。每一個要運作Storm的機器上都運作一個Supervisor,并且按照機器的配置設定上面配置設定的槽位數。
l Worker:在Supervisor上建立的一個JVM執行個體,Worker中運作Executor,而Executor作為Task運作的容器。
l Executor:運作時Task所在的直接容器,在Executor中執行Task的處理邏輯。一個或多個Executor執行個體可以運作在同一個Worker程序中,一個或多個Task可以運作于同一個Executor中;在Worker程序并行的基礎上,Executor可以并行,進而Task也能夠基于Executor實作并行計算
l Task:Spout/Bolt在運作時所表現出來的實體,都稱為Task,一個Spout/Bolt在運作時可能對應一個或多個Spout Task或Bolt Task,與實際在編寫Topology時進行配置有關。在Storm0.8之後,Task不再與實體線程對應,同一個Spout Task或Bolt Task可能會共享一個實體線程,該線程稱為Executor。
Storm送出運作的程式稱為Topology,它處理的最小的消息機關是一個Tuple,也就是一個任意對象的數組。Topology由Spout和Bolt構成,Spout是發出Tuple的結點,Bolt可以随意訂閱某個Spout或者Bolt發出的Tuple。下圖是一個Topology設計的邏輯圖的例子:

圖 2 Topology設計的邏輯圖
l Topology: Topology概念類似于Hadoop中的MapReduce作業,是一個用來編排、容納一組計算邏輯元件(Spout、Bolt)的對象(Hadoop MapReduce中一個作業包含一組Map任務、Reduce任務),這一組計算元件可以按照DAG圖的方式編排起來(通過選擇Stream Groupings來控制資料流分發流向),進而組合成一個計算邏輯更加負責的對象,那就是Topology。一個Topology運作以後就不能停止,它會無限地運作下去,除非手動幹預(顯式執行bin/storm kill)或意外故障(如停機、整個Storm叢集挂掉)讓它終止。
l Spout: Spout是一個Topology的消息生産的源頭,Spout是一個持續不斷生産消息的元件,例如,它可以是一個Socket Server在監聽外部Client連接配接并發送消息、可以是一個消息隊列(MQ)的消費者、可以是用來接收Flume Agent的Sink所發送消息的服務,等等。Spout生産的消息在Storm中被抽象為Tuple,在整個Topology的多個計算元件之間都是根據需要抽象建構的Tuple消息來進行連接配接,進而形成流。
l Bolt:Storm中消息的處理邏輯被封裝到Bolt元件中,任何處理邏輯都可以在Bolt裡面執行,處理過程和普通計算應用程式沒什麼差別,隻是需要根據Storm的計算語義來合理設定一下元件之間消息流的聲明、分發和連接配接即可。Bolt可以接收來自一個或多個Spout的Tuple消息,也可以來自多個其它Bolt的Tuple消息,也可能是Spout和其它Bolt組合發送的Tuple消息。
l Stream Grouping:Storm中用來定義各個計算元件(Spout和Bolt)之間流的連接配接、分組和分發關系。Storm定義了如下7種分發政策:Shuffle Grouping(随機分組)、Fields Grouping(按字段分組)、All Grouping(廣播分組)、Global Grouping(全局分組)、Non Grouping(不分組)、Direct Grouping(直接分組)、Local or Shuffle Grouping(本地/随機分組),各種政策的具體含義可以參考Storm官方文檔、比較容易了解。
在Storm中可以通過元件簡單串行或者組合多種流操作處理資料:
l Storm元件簡單串行
這種方式是最簡單最直覺的,隻要我們将Storm的元件(Spout或Bolt)串行起來即可實作,隻需要了解編寫這些元件的基本方法即可。在實際應用中,如果我們需要從某一個資料源連續地接收消息,然後順序地處理每一個請求,就可以使用這種串行方式來處理。如果說處理單元的邏輯非常複雜,那麼就需要處理邏輯進行分離,屬于同一類操作的邏輯封裝到一個處理元件中,做到各個元件之間弱耦合。
圖 3 Storm元件簡單串行
l Storm組合多種流操作
Storm支援流聚合操作,将多個元件的資料彙聚到同一個處理元件來統一處理,可以實作對多個Spout元件通過流聚合到一個Bolt元件(Sout到Bolt的多對一、多對多操作),也可以實作對多個Bolt通過流聚合到另一個Bolt元件(Bolt到Bolt的多對一、多對多操作)。
圖 4 Storm組合多種流操作
下圖是Topology的送出流程圖:
圖 5 Topology的送出流程圖
1. 用戶端通過Nimbus的接口上傳程式jar包到Nimbus的Inbox目錄中,上傳結束後,通過送出方法向Nimbus送出一個Topology。
2. Nimbus接收到送出Topology的指令後,對接收到的程式jar包進行序列化,把序列化的結果放到Nimbus節點的stormdist目錄中,同時把目前Storm運作的配置生成一個stormconf.ser檔案也放到該目錄中。靜态的資訊設定完成後,通過心跳資訊配置設定任務到機器節點。在設定Topology所關聯的Spouts和Bolts時,可以同時設定目前Spout和Bolt的Executor數目和Task數目,預設情況下,一個Topology的Task的總和與Executor的總和一緻。之後,系統根據Worker的數目,盡量平均的配置設定這些Task的執行。其中Worker在哪個Supervisor節點上運作是由Storm本身決定的。
3. 任務配置設定好之後,Nimbus節點會将任務的資訊送出到ZooKeeper叢集,同時在ZooKeeper叢集中會有Worker分派節點,這裡存儲了目前Topology的所有Worker程序的心跳資訊。
4. Supervisor節點會不斷的輪詢ZooKeeper叢集,在ZooKeeper的分派節點中儲存了所有Topology的任務配置設定資訊、代碼存儲目錄和任務之間的關聯關系等,Supervisor通過輪詢此節點的内容,來領取自己的任務,啟動Worker程序運作。
5. 一個Topology運作之後,就會不斷的通過Spout來發送Stream流,通過Bolt來不斷的處理接收到的資料流。
2 Spark Streaming與Storm比較
Storm和Spark Streaming都是分布式流處理的開源架構,但是它們之間還是有一些差別的,這裡将進行比較并指出它們的重要的差別。
1. 處理模型以及延遲
雖然這兩個架構都提供可擴充性(Scalability)和可容錯性(Fault Tolerance),但是它們的處理模型從根本上說是不一樣的。Storm處理的是每次傳入的一個事件,而Spark Streaming是處理某個時間段視窗内的事件流。是以,Storm處理一個事件可以達到亞秒級的延遲,而Spark Streaming則有秒級的延遲。
2. 容錯和資料保證
在容錯資料保證方面的權衡方面,Spark Streaming提供了更好的支援容錯狀态計算。在Storm中,當每條單獨的記錄通過系統時必須被跟蹤,是以Storm能夠至少保證每條記錄将被處理一次,但是在從錯誤中恢複過來時候允許出現重複記錄,這意味着可變狀态可能不正确地被更新兩次。而Spark Streaming隻需要在批處理級别對記錄進行跟蹤處理,是以可以有效地保證每條記錄将完全被處理一次,即便一個節點發生故障。雖然Storm的 Trident library庫也提供了完全一次處理的功能。但是它依賴于事務更新狀态,而這個過程是很慢的,并且通常必須由使用者實作。
簡而言之,如果你需要亞秒級的延遲,Storm是一個不錯的選擇,而且沒有資料丢失。如果你需要有狀态的計算,而且要完全保證每個事件隻被處理一次,Spark Streaming則更好。Spark Streaming程式設計邏輯也可能更容易,因為它類似于批處理程式,特别是在你使用批次(盡管是很小的)時。
3. 實作和程式設計API
Storm主要是由Clojure語言實作,Spark Streaming是由Scala實作。如果你想看看這兩個架構是如何實作的或者你想自定義一些東西你就得記住這一點。Storm是由BackType和 Twitter開發,而Spark Streaming是在UC Berkeley開發的。
Storm提供了Java API,同時也支援其他語言的API。 Spark Streaming支援Scala和Java語言(其實也支援Python)。另外Spark Streaming的一個很棒的特性就是它是在Spark架構上運作的。這樣你就可以想使用其他批處理代碼一樣來寫Spark Streaming程式,或者是在Spark中互動查詢。這就減少了單獨編寫流批量處理程式和曆史資料處理程式。
4. 生産支援
Storm已經出現好多年了,而且自從2011年開始就在Twitter内部生産環境中使用,還有其他一些公司。而Spark Streaming是一個新的項目,并且在2013年僅僅被Sharethrough使用(據作者了解)。
Storm是 Hortonworks Hadoop資料平台中流處理的解決方案,而Spark Streaming出現在 MapR的分布式平台和Cloudera的企業資料平台中。除此之外,Databricks是為Spark提供技術支援的公司,包括了Spark Streaming。
5. 叢集管理內建
盡管兩個系統都運作在它們自己的叢集上,Storm也能運作在Mesos,而Spark Streaming能運作在YARN 和 Mesos上。