用途
有時候需要從圖檔(或文本)中提取出數值型特征,供各種模型使用。深度學習模型不僅可以用于分類回歸,還能用于提取特征。通常使用訓練好的模型,輸入圖檔,輸出為提取到的特征向量。
加入特征之後,結果往往不盡如人意,大緻有以下原因:
-
深度學習模型一般有N層結構,不能确定求取哪一層輸出更合适。
深度學習模型很抽象——幾十層的卷積、池化、資訊被分散在網絡參數之中。提取自然語言的特征時,常常提取詞向量層的輸出作為特征,有時也取最後一層用于描述句意;圖像處理時往往提取最後一層輸出向量;在圖像目辨別别問題中,常提取後兩層子網絡的輸出作為組合向量。如何選擇提取位置,取決于對模型的了解,後文将對圖像處理層進行詳細說明。
-
針對不同問題訓練出的模型,輸出的特征也不同。
通常下載下傳的ResNet,VGG,BERT預訓練模型,雖然通用性高,但解決具體問題的能力比較弱。比如在自然語言進行中,用GPT-2或者BERT訓練的模型隻面對普通文章,如果從中提取特征用于判斷辱罵,有些髒字可能有效,但是更多的“多義詞”會被它的普通含義淹沒。 用自己的資料fine-tune後往往更有針對性,而fine-tune的目标也需仔細斟酌,否則可能起到反作用。比如希望用ResNet識别不同的衣服,就需要考慮到衣服的形狀、質地、顔色等等因素,如果用衣服類型(大衣、褲子)的分類器去fine-tune模型,新模型可能對形狀比較敏感,而對材質、顔色的識别效果反而變差。
原理
圖像模型ResNet-50規模适中,效果也很好,是以被廣泛使用。下面将介紹該模型各層輸出的含義,以及用它提取圖檔特征的方法。
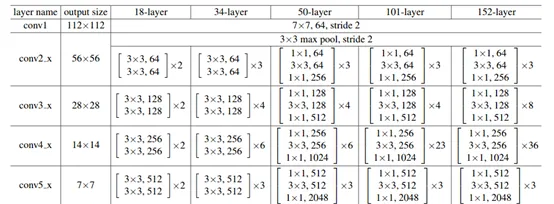
ResNet原理詳見論文:https://arxiv.org/pdf/1512.03385.pdf。常用的ResNet網絡參數如下,
可以看到,它包含四層Bottlenect(子網絡),越往後,擷取的特征越抽象。
以單圖為例,輸入模型的圖像結構為 [1, 3, 224, 224],圖檔大小為224x224(大小根據具體圖檔而定),有紅、綠、藍3個通道。

第一步,經過一個7x7卷積層,步長為2,它的輸出是:(1,64,112,112),可視為64通道的112x112大小的圖檔,處理後效果如下圖所示。
該層共生成64張圖檔,由于步長是2,大小變為112x112,每一種特征提取方法對應一組參數,這些參數對每7x7個像素進行同樣處理,最終生成一個新的像素。換言之,就是構造了64種特征提取方法,分别提取了顔色,形狀,邊緣等特征,也可以看到由于處理以卷積為基礎,圖像位置關系得以保留。
在輸入一張圖檔時,一個224x224的圖通過這一層,提取了64x112x112=802816維特征,該層一般稱為第一組卷積層conv1,由于該層次太過底層,次元過大,很少使用該層特征。
經過第一層之後,又經過歸一化,激活函數,以及步長為2的池化,輸出大小為[1, 64, 56, 56],如下圖所示:
然後依次傳入四個Bottlenext子網絡(原理同上),分别稱為conv2, conv3, conv4, conv5(也有名為layer1,layer2,layer3,layer4),輸出的大小也逐層遞減,最終減緻2048x7x7=100352,長寬分别是原始參數的1/32。Mask-RCNN中就可擷取R-50的第4和第5次作為特征。四層輸出如下:
示例
下例為從指定的層提取ResNet50的特征。
import torch
from torch import nn
import torchvision.models as models
import torchvision.transforms as transforms
import cv2
class FeatureExtractor(nn.Module): # 提取特征工具
def __init__(self, submodule, extracted_layers):
super(FeatureExtractor, self).__init__()
self.submodule = submodule
self.extracted_layers = extracted_layers
def forward(self, x):
outputs = []
for name, module in self.submodule._modules.items():
if name is "fc":
x = x.view(x.size(0), -1)
x = module(x)
if name in self.extracted_layers:
outputs.append(x)
return outputs
model = models.resnet50(pretrained=True) # 加載resnet50工具
model = model.cuda()
model.eval()
img=cv2.imread('test.jpg') # 加載圖檔
img=cv2.resize(img,(224,224));
img=cv2.cvtColor(img,cv2.COLOR_BGR2RGB)
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
img=transform(img).cuda()
img=img.unsqueeze(0)
model2 = FeatureExtractor(model, ['layer3']) # 指定提取 layer3 層特征
with torch.no_grad():
out=model2(img)
print(len(out), out[0].shape)