一、VGG
研究目的:論文主要研究卷積網絡的深度(Depth)對于圖像識别任務的準确度影響。
論文主要貢獻:
- 一定的資料規模下,增加網絡深度能夠有效提升網絡的性能;
- 兩個3x3Conv的感受野等效于1個5x5Conv,并且參數更少,性能更好;
- VGG引入了卷積子產品的設計模式(Figure 1),其特點是:一個卷積塊内的特征圖尺寸通常不變,子產品之間特征圖尺寸降低時,特征圖的數量會增加(後續的分類網絡基本都是基于子產品的設計,比如Inception,ResNet,DenseNet);
- LRN對于分類性能無明顯增益;
- VGG結構簡潔,網絡由3x3Conv+2x2MaxPooling 構成(Figure 1),便于作為基礎網絡遷移到其它應用場景;
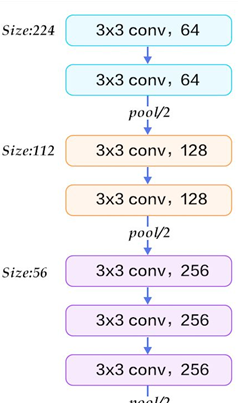
Figure 1
論文不足:總共140M的參數量,參數量太大,主要集中在3層全連接配接層;
網絡結構:論文總共訓練和測試了5種結構(A-B-C-D-E),其中,D, E分别為VGG-16和VGG-19

訓練設定:
- 優化器:帶有動量的SGD,momentum = 0.9,L2=5*0.0001;
- 學習率:初始學習率為0.01,當驗證集誤差不降低的時候,除以10;
- 隻在前兩層全連接配接添加Dropout,值為0.5;
- 資料增強:随機水準翻轉和随機RGB顔色偏移,以及多尺度随機裁剪;
二、Inception系列
Inception-v1:
論文目的:在提升網絡寬度和深度的同時,保證網絡仍具有較高的計算效率;
論文主要貢獻:
- 設計Inception子產品,通過将1x1Conv、3x3Conv、3x3MaxPooling進行通道次元的Concatate(見下圖a,b),使得網絡更寬,同時可以提取圖像中不同尺度、位置的目标特征;
- 添加輔助分類器,可以監督中層特征,有效避免梯度消失(但是後續Inception論文否定了輔助分類器的作用);
- 添加1x1Conv來降低特征圖的通道數量,降低計算的複雜度;
- 替換掉全連接配接層,使用全局平均池化層代替,極大減低了網絡的參數量,大概5M的參數,相比于VGG(140M),AlexNet(60M),參數量大幅度降低;
網絡不足:
- 網絡設計較為複雜,特别是Inception子產品中每一層的卷積核數量(很難設定,沒有統一的準則),難以順利遷移到其它任務場景,網絡輕微的修改,可能就無法達到預期的效果;
- 雖然參數少,但是訓練過程很慢,沒有VGG訓練快;
網絡結構:Inception子產品如上圖Figure2(b)所示,#3x3reduce和#5x5reduce分别表示在3x3Conv和5x5Conv之前使用1x1Conv,目的是為了降低輸入卷積的通道數量;Table1展示的是GoogLeNet的主幹結構,不包括輔助分支結構;
GoogLeNet 有 9 個線性堆疊的 Inception 子產品。它有 22 層(包括池化層的話是 27 層)。該模型在最後一個 inception 子產品處使用全局平均池化;
訓練設定:
- 優化器:帶有動量的SGD,momentum = 0.9,L2=5*0.0001;
- 學習率:初始學習率為0.01,當驗證集誤差不降低的時候,除以10;
- 隻在前兩層全連接配接添加Dropout,值為0.4;
- 資料增強:随機水準翻轉和随機RGB顔色偏移,以及多尺度随機裁剪;
Inception-v2 and Inception-v3:
論文目的:本篇論文進一步研究如何充分利用有限的計算資源,通過對Inception子產品進一步設計,使得節省計算資源的情況下,提高其計算效率和分類準确度;
論文貢獻:主要的貢獻是進一步提出三種Inception子產品;
1、将大的卷積核分解為多個小的卷積核,比如将5x5Conv分解為兩個3x3Conv, 5×5 的卷積在計算成本上是一個 3×3 卷積的 2.78 倍;
2、非對稱分解(7x7分解為1x7conv+7x1conv),作者通過測試發現,非對稱卷積用在網絡中靠中間的層級才有較好的效果(特别是feature map的大小在12x12~20x20之間);
3、為了避免pool帶來的表達能力降低,圖9中,左邊的結構(先使用了Pool)會導緻網絡表達能力降低,右邊的結構會導緻計算代價非常高。圖10中,通過并行處理的方式,同時降低計算複雜度,同時避免了網絡表達瓶頸。
網絡結構:
Inception-v2:在下面的表中,三個Inception子產品分别對應上述的圖5,圖6,圖7,不同階段使用不同的Inception子產品;
Inception-v3:在Inception-v2的基礎上,輔助分類器添加BN,使用了新的優化器RMSProp,标簽平滑以及Factorized 7x7Conv;
Inception-v4:參考連結(https://blog.csdn.net/kxh123456/article/details/102828148)
論文目的:在前面Inception基礎上,以及ResNet基礎上,重新設計Inception結構,進一步提升網絡性能,同時保持計算效率最優;
論文優點:
- 提出更優的Inception-v4結構,稍微簡化了網絡的設計準則;
- 結合Inception和ResNet的優點,提出Inception-ResNet-v1和Inception-ResNet-v2網絡結構;
- 丢棄輔助分類器,作者認為其并沒有太大的用處;
網絡結構:參考上述連結,詳細介紹了各種結構;
網絡訓練:使用新的優化器,RMSProp,decay為0.9;
三、ResNet
論文目的:與之前的卷積網絡相比,作者進一步提升網絡的層數(比如50, 101, 152, 1000)。但是,作者發現,網絡變深之後,訓練過程中會出現網絡退化的現象。為此論文中引入殘差子產品,使得深層網絡訓練更加穩定、更容易。
論文優點:
- 提出殘差子產品(Figure 2),解決深層難以訓練的問題;
- 殘差子產品簡潔通用,很容易遷移到其它應用場景;
網絡結構:
CIFAR-10訓練設定:
參考如下連結的Sec.4.2:https://blog.csdn.net/kxh123456/article/details/102775867
四、DenseNet
論文目的:論文借鑒了ResNet網絡的思想:網絡層之間添加短連接配接。為此,本文設計更為密集的跳躍連接配接方式,将前面所有的層作為該層的輸入,而該層是所有後面層的輸入。目的是使得網絡特征可以重複利用,保證網絡的有效訓練。
論文優點:
- 設計新的稠密網絡子產品(dense block),子產品中的每一層結構:BN+ReLU+3x3Conv,跟傳統的卷積層(3x3Conv+BN+ReLU)有所差别;
- 特征重複利用:特征是直接連接配接,而不是直接求和,并傳遞到下一層。是以,每一層的特征都會傳遞到後面的每一層,與最後的損失層直接連接配接,保證網絡被有效的監督;
- 這種特征的重複利用以及密集連接配接的方式,有效的緩解了網絡的梯度消失問題;
網絡結構:
Dense-B:添加了瓶頸特征,降低每一個子產品的特征圖數量,BN-ReLU-1x1Conv-BN-ReLU-3x3Conv;
Dense-C:每兩個dense block之間有一層transition layer,見下面的Table 1。假設前一個子產品特征圖數量為m個,那麼經過該層後,會添加參數a,a小于等于1,大于0,可以降低特征圖數量;
Dense-BC:同時使用瓶頸特征和參數a,并且a<1;
下圖是ImageNet上的網絡結構:
訓練設定:
參考如下連結的:https://blog.csdn.net/kxh123456/article/details/102857035;