python爬取全網小說
前言:上一篇文章講了怎麼擷取所有小說的唯一編号,然後将編号進行拼接就可以得到小說的所有章節的頁面。這次我們來講講怎麼将所有小說的内容下載下傳下來。上一篇文章位址:爬取全網小說(1)
結果如下:
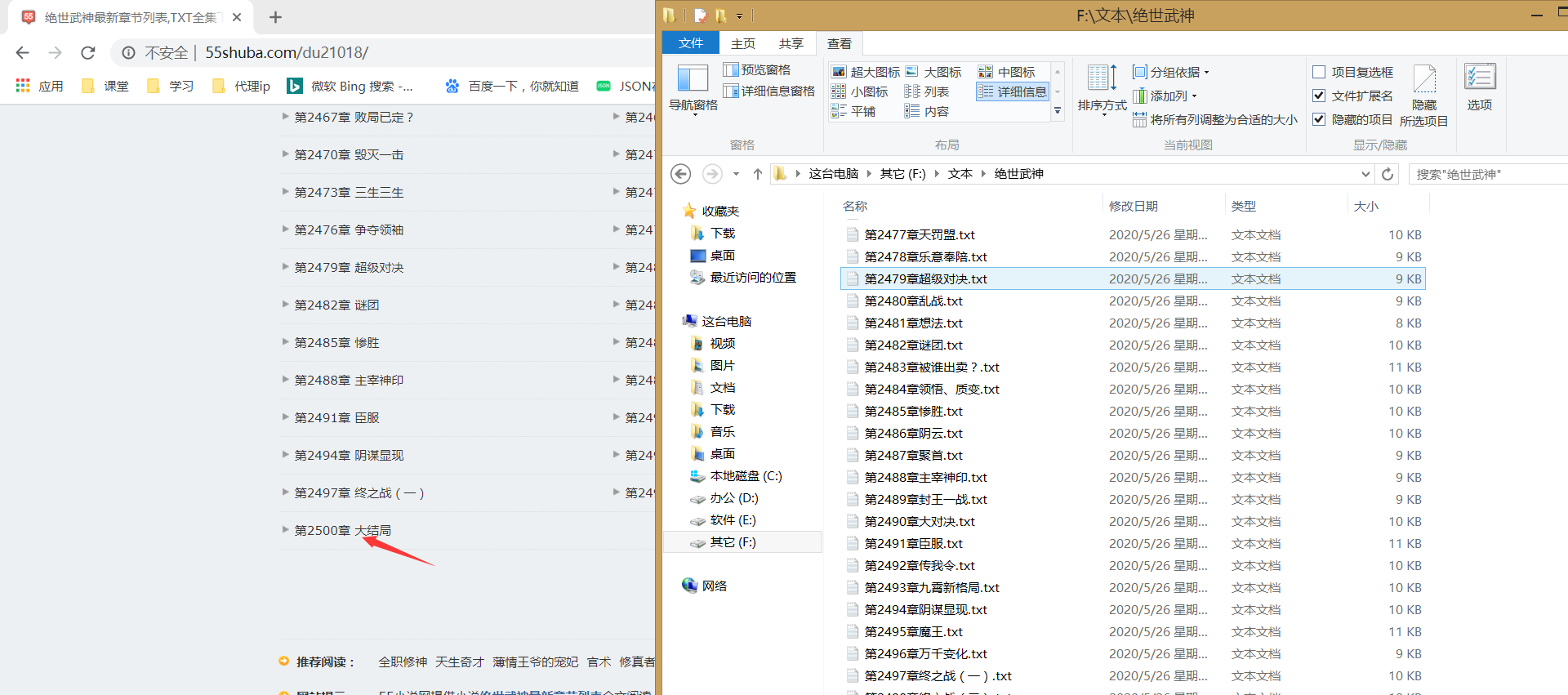
1. 分析整體思路和小說章節頁面
a) 整體思路和實作目标:
- 我們已經擷取到了 {“小說名”: “小說對應的編号”} 的字典了。這樣就可以實作下載下傳使用者指定的小說了。
- 因為小說章節較多,我們就可以考慮将擷取到的小說章節全部放入隊列當中,然後再使用多線程進行下載下傳,但又考慮到多線程下載下傳的最終結果是無序的,是以本文章最後沒有使用多線程
- 對方伺服器肯定有反爬,是以我們可以通過第三方模快fake_useragent随機擷取使用者代理,實作一定的反反爬,關于在fake_useragent的使用過程中遇到的問題可以參考 fake_useragent報錯點我
- 在下載下傳小說的過程中,極有可能出現下載下傳失敗或者阻塞的情況,這時我們就需要設定逾時參數和使用retrying子產品中的retry子產品了。retry子產品的使用可以參考 retrying子產品的使用
- 在下載下傳過程中我們也有可能被迫停止程式的情況,而停止程式後我們又不想再重新下載下傳一遍,這時我們就可以在下載下傳之前周遊一下儲存小說的檔案夾,若已存在某檔案則跳過下載下傳。
b) 我們要提取的目标是小說章節的詳情位址和小說章節名,是以我們的xpath表達式可以這樣寫 //tbody//td/a 擷取到所有的a節點,我們再周遊a節點進而擷取到部分的詳情位址和小說章節名。

2. 完整代碼
a) 代碼中的随機使用者代理我就不使用fake_useragent子產品了,但你們最好是使用它。關于它的使用我在上面也放了連結了。關于代碼的詳解我會放在完整代碼中。
import time
import json
import re
import os
import random
import requests
from lxml import etree
from retrying import retry
class DownNovel(object):
def __init__(self):
self.url = 'http://www.55shuba.com/du{}/' # 小說章節的基礎url
self.HEADERS = ["Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; AcooBrowser; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0; Acoo Browser; SLCC1; .NET CLR 2.0.50727; Media Center PC 5.0; .NET CLR 3.0.04506)",
"Mozilla/4.0 (compatible; MSIE 7.0; AOL 9.5; AOLBuild 4337.35; Windows NT 5.1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US)",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)",
"Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)",
"Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)",
"Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0",
"Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5",
"Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.9.0.8) Gecko Fedora/1.9.0.8-1.fc10 Kazehakase/0.5.6",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/535.20 (KHTML, like Gecko) Chrome/19.0.1036.7 Safari/535.20",
"Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; fr) Presto/2.9.168 Version/11.52",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.11 TaoBrowser/2.0 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; LBBROWSER)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E; LBBROWSER)",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.84 Safari/535.11 LBBROWSER",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E)",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; QQBrowser/7.0.3698.400)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SV1; QQDownload 732; .NET4.0C; .NET4.0E; 360SE)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E)",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.89 Safari/537.1",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.89 Safari/537.1",
"Mozilla/5.0 (iPad; U; CPU OS 4_2_1 like Mac OS X; zh-cn) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8C148 Safari/6533.18.5",
"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:2.0b13pre) Gecko/20110307 Firefox/4.0b13pre",
"Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:16.0) Gecko/20100101 Firefox/16.0",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11",
"Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36"] # 定義的使用者代理,存放在清單中
self.headers = {"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"Accept-Encoding": "gzip, deflate",
"Accept-Language": "zh-CN,zh;q=0.9",
"Cache-Control": "max-age=0",
"Connection": "keep-alive",
"Cookie": "bdshare_firstime=1590149393888; UM_distinctid=1724548cc5b35-0819686bf4beda-58143718-144000-1724548cc5c2a7; jieqiVisitId=article_articleviews%3D12532; PHPSESSID=cd437784ae3d3127ceb017e6b62dac56; CNZZDATA1254488625=180465324-1590297470-http%253A%252F%252Fwww.55shuba.com%252F%7C1590374013",
"Host": "www.55shuba.com",
"If-None-Match": "1590377583|",
"Referer": "http://www.55shuba.com/txt/12532.htm",
"Upgrade-Insecure-Requests": "1",
"User-Agent": random.choice(self.HEADERS)} # 請求小說章節的請求頭
self.detail_headers = {"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"Accept-Encoding": "gzip, deflate",
"Accept-Language": "zh-CN,zh;q=0.9",
"Cache-Control": "max-age=0",
"Connection": "keep-alive",
"Cookie": "bdshare_firstime=1590149393888; UM_distinctid=1724548cc5b35-0819686bf4beda-58143718-144000-1724548cc5c2a7; jieqiVisitId=article_articleviews%3D12532; PHPSESSID=cd437784ae3d3127ceb017e6b62dac56; CNZZDATA1254488625=180465324-1590297470-http%253A%252F%252Fwww.55shuba.com%252F%7C1590374013",
"Host": "www.55shuba.com",
"If-None-Match": "1590378781|",
"Upgrade-Insecure-Requests": "1",
"User-Agent": random.choice(self.HEADERS)} # 通路小說詳情頁的請求頭
# 擷取使用者輸入的小說并拼接成小說章節的url
def connect_url(self):
try:
with open('fake_useragent_0.1.11.json', 'r', encoding='utf-8')as f: # 打開目前檔案夾下的novel.json檔案
text = json.load(f) # 将寄送檔案轉為python中的資料類型,在這裡也就是字典
novel_name = input('請輸入小說名:') # 擷取使用者輸入的小說名
num = text[novel_name] # 從字典中擷取小說名對應的小說編号
target_url = self.url.format(num) # 拼接小說編号擷取到小說的章節下載下傳位址
self.parse_page(target_url, novel_name) # 将小說章節的url和使用者輸入的小說名傳給parse_page方法
except KeyError:
print('書名有誤,請重新輸入')
def parse_page(self, url, novel_name):
res = requests.get(url, headers=self.headers).content.decode('gbk', errors='ignore') # 通路小說章節位址
html = etree.HTML(res)
a_list = html.xpath('//tbody//td/a') # 擷取所有的a節點
for a in a_list: # 周遊a節點提取出詳情位址和小說章節名
detail_url = url + a.xpath('./@href')[0] # 進行拼接擷取章節的完整位址
chapter_name = a.xpath('./text()')[0] # 小說章節名
self.parse_detail_url(chapter_name, detail_url, url, novel_name) # 将章節名,詳情位址,小說名交給parse_detailurl方法
@retry(stop_max_attempt_number=3) # 最大嘗試次數為3次,設定的timeout=5,當5次都逾時就報錯
def parse_detail_url(self, chapter_name, detail_url, url, novel_name):
# 判斷是否已下載下傳某章節的小說,若以下載下傳則跳過重複下載下傳
chapter_name = re.sub(r'[\/\\\:\*\?\\<\>\|#/ \:*]', '', chapter_name) # 将小說章節名中的非法字元替換為空
file_name = './文本/{}/{}.txt'.format(novel_name, chapter_name)
if os.path.exists(file_name): # 判斷是否存在某小說章節
print('已存在 {}'.format(chapter_name))
else:
try:
self.detail_headers['Referer'] = url # 向self.detail_headers中添加鍵值對Referer
res = requests.get(detail_url, headers=self.detail_headers, timeout=5).content.decode('gbk', errors='ignore') # 通路小說章節的詳情内容。并設定逾時參數為5s
html = etree.HTML(res)
content = html.xpath('//dd[@id="contents"]/text()') # 擷取小說的内容,因為br标簽的存在,是以擷取到的是一個清單
content = re.sub(r'[\/\\\:\*\?\\<\>\| # / \ : *]', '', '\n'.join(content)) # 将小說内容中的非法或者不想要的字元替換為空,因為br标簽的作業就是換行,是以我們可以使用\n将字元串連接配接起來
self.save_novel(chapter_name, content, novel_name) # 将小說章節,小說内容,小說名交給save_novel方法
except TimeoutError:
print('請求逾時 {}'.format(detail_url))
@staticmethod
def save_novel(chapter_name, content, novel_name):
# 進行判斷,若不存在小說名的目錄則建立
file_name = './文本/{}'.format(novel_name)
if not os.path.exists(file_name):
os.makedirs(file_name)
# 儲存小說的内容
with open(file_name+'/{}.txt'.format(chapter_name), 'w', encoding='utf-8')as f:
f.write(content)
print('已下載下傳 {}'.format(chapter_name))
def main(self):
self.connect_url()
if __name__ == '__main__':
start_time = time.time()
spider = DownNovel()
spider.main()
# 計算花費的時間
print('總花費 {:.2f}s'.format(time.time()-start_time))
b) 隐藏使用者代理清單
c) 注意事項:
- fake_useragent_0.1.11.json檔案需要與py檔案放在同一個目錄下,該檔案的下載下傳位址 fake_useragent_0.1.11.json下載下傳位址,提取碼為 ak2i
- 本篇文章沒有使用多線程,因為使用多線程後下載下傳結果是無序的,這對最後整理小說時來說是緻命的。
- 小說的下載下傳内容在目前檔案夾下。
結語:爬取全網的小說文章到這裡就結束了,我們實作了根據使用者輸入的小說名下載下傳指定的小說,fake_useragent_0.1.11.json檔案在收集時工作量還是有些大的,如果大家覺得我的文章能夠帶給大家一些知識的話,可以給我點個贊或收藏。 學習必須與實幹相結合。——泰戈爾 。可見自己動手的重要性,希望觀看到這裡的人最後都能夠完成自主對全網小說的爬取。加油!!!