近期在不同群裡有小夥伴們提出了一些在面試和筆試中遇到的Hive SQL問題,Hive作為算法工程師的一項必備技能,在面試中也是極有可能被問到的,是以有備無患,本文将對這四道題進行詳細的解析,還是有一定難度的,希望你看完本文能夠有所收獲。
1、多列轉多行
第一道題目是這樣的:
假設現有一張Hive表,
中繼資料格式為:
字段:
id stirng
tim string
資料格式如下:
a,b,c,d 2:00,3:00,4:00,5:00
f,b,c,d 1:10,2:20,3:30,4:40
需要變成:
a 2:00
b 3:00
c 4:00
d 5:00
複制
這道題目是需要把多行轉換成多行,有點類似python裡面的zip操作。大夥應該都知道hive裡有一個常用的一行轉多行的函數叫explode,假設有如下的資料:
a,b,c,d 2:00,3:00,4:00,5:00
f,b,c,d 1:10,2:20,3:30,4:40
複制
按照第二列explode的話,使用下面的SQL:
select
id,tim,single_tim
from
default.a1
lateral view explode(split(tim,',')) t as single_tim
複制
效果如下:
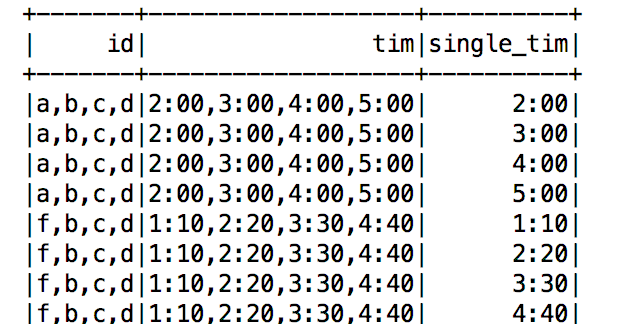
但這道題目裡,需要對兩列同時進行explode,如果隻進行簡單的explode,效果如下:

這樣一行變成了16行,而我們僅僅需要的是其中能夠對齊下标的四行。是以在進行explode的時候,我們期望不僅僅能夠能夠獲得數組裡的每個值,還希望能夠得到其對應的下标,這樣在對兩列同時進行explode的時候,保留數組下标相同的四行就可以了。這裡我們會用到posexplode函數。
posexplode函數跟explode函數的使用方法類似,看下面的例子:
select
id,tim,single_id_index,single_id
from
default.a1
lateral view posexplode(split(id,',')) t as single_id_index,single_id
複制
傳回的結果為:
應用到本題,隻需要應用兩次posexplode函數,再通過where留下兩個index相等的行就可以了,按照這個思路,sql如下:
select
id,tim,single_id,single_tim
from
default.a1
lateral view posexplode(split(id,',')) t as single_id_index,single_id
lateral view posexplode(split(tim,',')) t as single_tim_index,single_tim
where
single_id_index = single_tim_index
複制
結果正是我們想要的:
2、排序後相鄰兩行均值
第二題的原始資料如下:
要求如下:
分組排序想必大家都知道使用row_number()函數,但要找到同組前一行的值,可能有許多同學不太了解,這裡是用的是lead/lag函數,兩個函數用法如下:
lag(字段名,N) over(partition by 分組字段 order by 排序字段 排序方式)
lead(字段名,N) over(partition by 分組字段 order by 排序字段 排序方式)
複制
簡單解釋一下:
lag括号裡理由兩個參數,第一個是字段名,第二個是數量N,這裡的意思是,取分組排序之後比該條記錄序号小N的對應記錄的指定字段的值,如果字段名為ts,N為1,就是取分組排序之後上一條記錄的ts值。
lead括号裡理由兩個參數,第一個是字段名,第二個是數量N,這裡的意思是,取分組排序之後比該條記錄序号大N的對應記錄的對應字段的值,如果字段名為ts,N為1,就是取分組排序之後下一條記錄的ts值。
如果沒有前一行或者後一行,對應的字段值為null。
是以,這裡我們應該使用的是lag函數,來擷取同組排序後前一行資料對應字段的值,SQL如下:
select
year,chr,if(pre_val is null,val,(val + pre_val) / 2.0) as avg_val
from
(
select
year,chr,val,
lag(val,1) over(partition by year order by chr asc) as pre_val
from
default.a2
) a
複制
注意這裡的一個小細節,如果分組後資料排在第一位,它是沒有前一個數的,此時數仍保持原樣,是以這裡加了一個if判斷,結果符合預期:
3、擷取字元串索引清單
第三題的題目要求如下:
1011
0101
=> 取到每一行中1所對應的索引清單,索引從1開始
0101 2,4
1011 1,3,4
複制
這一行其實也是對posexplode方法的應用,直接上代碼:
select
id,stri,concat_ws(',',collect_list(index)) as indices
from
(
select
id,stri,chr,cast(index + 1 as string) as index
from
default.abcg
lateral view posexplode(split(stri,'')) ids as index,chr
where
chr = '1'
) a
group by
id,stri
複制
4、分塊排序
最後一題感覺是比較有難度的一道題目:
2014,1
2015,1
2017,0
2018,0
2019,1
2020,1
2021,1
2022,0
2023,0
=>
2014,1,1
2015,1,2
2017,0,1
2018,0,2
2019,1,1
2020,1,2
2021,1,3
2022,0,1
2023,0,2
複制
簡單描述下題目,col1是有序的,然後按照col2分塊計數,每當col2發生變化,就重新開始計數,計數的結果當作col3傳回。
這道題我想到的方法可能比較笨,先上代碼,然後咱們一步步解析:
select year,
num,
row_number() over(partition by min_year order by year asc) as new_rank
from
(
select year,
base.num as num,
min_year,
row_number() over(partition by base.year order by min_year desc) as rank
from (
select *
from default.a3
) base
inner join (
select min_year,
num,
pre_num
from (
select year as min_year,
num,
lag(num,1) over(order by year) as pre_num
from default.a3
) a
where num!=pre_num
or pre_num is null
) min_year
on base.num = min_year.num
where base.year >= min_year.min_year
) cc
where rank = 1
order by year
複制
輸出結果符合預期:
接下來,一步步解析下上面的過程:
1)使用lag函數,得到其前面一個數:
select year as min_year,
num,
lag(num,1) over(order by year) as pre_num
from default.a3
複制
2)判斷目前數和前面一個數的關系,得到分塊最小值
如果兩個數不相等,說明在此處數發生了變化,是一個新的分塊的開始,除此之外,如果沒有前一個數,說明目前行是第一行,同樣作為一個分塊的開始。這樣,我們可以得到每個分塊的開始:
select min_year,
num,
pre_num
from (
select year as min_year,
num,
lag(num,1) over(order by year) as pre_num
from default.a3
) a
where num!=pre_num
or pre_num is null
複制
這裡的結果如下:
四個分塊的開始分别是2014、2017、2019、2022。
3)判斷每一行屬于哪個分塊
我們需要拿第二步得到的結果與原結果使用第二列進行join,然後判斷每一行屬于哪個分塊。決定每一行的所屬分塊有兩個條件,首先該行第一列的值要大于或等于分塊的最小值;其次,在所有滿足條件的分塊最小值中,選擇最大的一個,便是該行所在分塊的最小值。
是以這裡我們首先進行join操作,然後使用row_number()得到了每一行所在的分塊:
select year,
num,
min_year
from
(
select year,
base.num as num,
min_year,
row_number() over(partition by base.year order by min_year desc) as rank
from (
select *
from default.a3
) base
inner join (
select min_year,
num,
pre_num
from (
select year as min_year,
num,
lag(num,1) over(order by year) as pre_num
from default.a3
) a
where num!=pre_num
or pre_num is null
) min_year
on base.num = min_year.num
where base.year >= min_year.min_year
) cc
where rank = 1
order by year
複制
結果如下:
4)把分塊最小值作為分組鍵,進行分組排序
好了,這四道題就解析完畢了,抓緊時間去練習一下吧~~