更多文章歡迎訂閱上方《從實戰學python》專欄
哈喽,大家好,我是一條。
今日逛B站時發現“法外狂徒張三”在B站的熱度相當之高,随随便便一個幾分鐘的視訊就有
100w+
的播放量。
是以一條就來了興趣,B站人是如何看待“法外狂徒張三”的?
我們爬取彈幕并制作詞雲分析一下。
擷取彈幕
分析url
首先要拿到url,B站搜尋
張三
,我們就用第一個視訊:【張三的社會語錄】
https://www.bilibili.com/video/av588303995
F12
分析一下
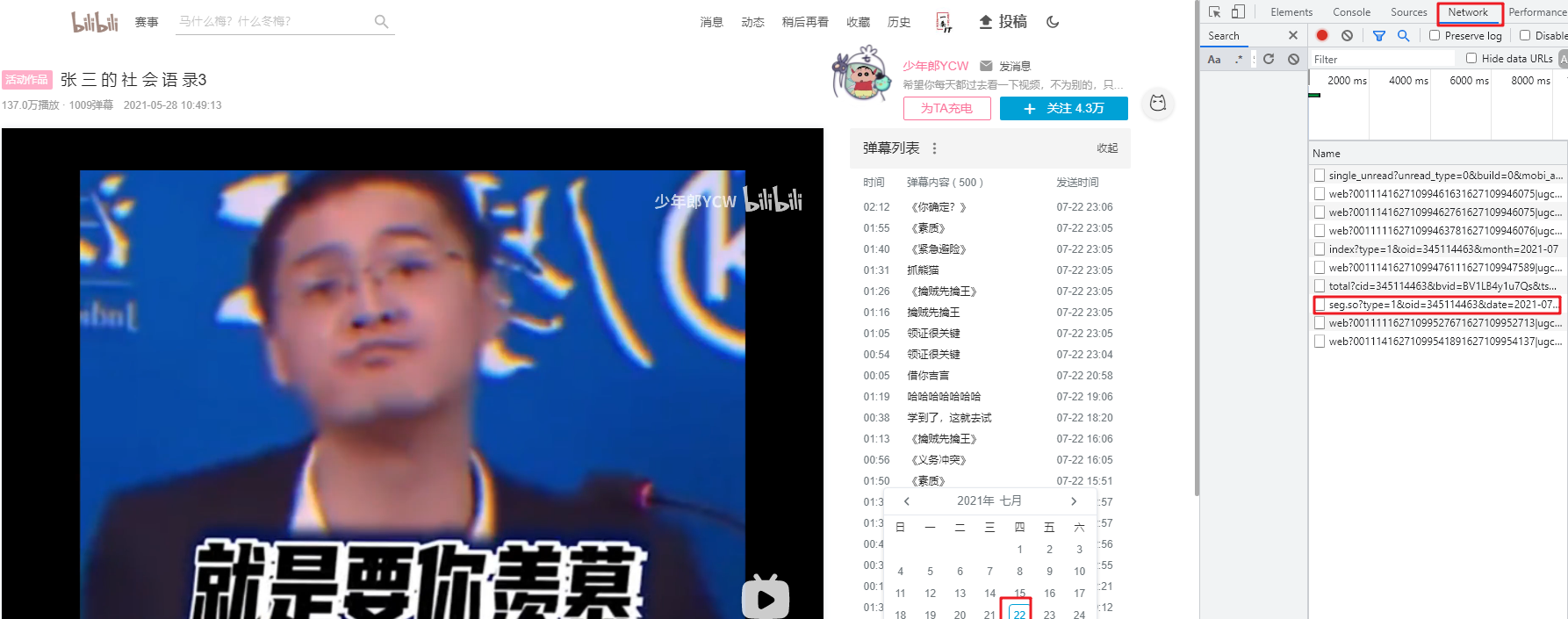
點選
檢視曆史彈幕
——
選擇一個日期
可以看到一個
seg.so
的連結,後面是
oid=
,如此我們就拿到了該視訊彈幕的
oid
拼接到彈幕
API
,得到彈幕的
xml
位址
https://api.bilibili.com/x/v1/dm/list.so?oid=345114463
發送請求
由于沒有登入驗證,我們就簡單的發送一條
get
請求,并用
xpath
解析

import requests
from lxml import etree
def get_text():
url='https://api.bilibili.com/x/v1/dm/list.so?oid=345114463'
res=requests.get(url)
res.encoding='utf-8'
with open("bilibili.xml", 'wb') as f:
f.write(res.content)
html = etree.parse('bilibili.xml',etree.HTMLParser())
b_list=html.xpath('//d//text()')
with open("bilibili.txt",'a+',encoding='utf-8') as f:
for i in b_list:
f.write(i+'\n')
print("彈幕擷取完成")
文本處理
安裝分詞庫
pip install jieba
jieba分詞
jieba
分詞的作用是将彈幕的長句分成單個的詞語,以便進行詞雲的繪制
在分詞前還要去除無效資料,比如标點符号,語氣助詞……
def get_wc():
with open("bilibili.txt", "r",encoding='utf-8') as f:
txt = f.read()
re_move = [",", "。",'\n','\xa0',' ','的','了','嗎','我','你']
for i in re_move:
txt = txt.replace(i, " ")
word = jieba.lcut(txt)
with open("bilibili_wc.txt", 'w',encoding='utf-8') as f:
for i in word:
f.write(str(i) + ' ')
print("文本處理完成")
生成詞雲
安裝wordcloud
pip install wordcloud
wordcloud
當我們手中有一篇文檔,比如書籍、小說、電影劇本,若想快速了解其主要内容是什麼,則可以采用繪制 WordCloud 詞雲圖,顯示主要的
高頻詞
這種方式,非常友善。
使用wordcloud可以指定使用的字型, 在windows中, 字型在以下的檔案夾中:
C:\Windows\Fonts
, 可以将其中的字型檔案拷貝到目前的檔案夾内。
本文基于
bilibili
的logo進行詞雲繪制
def get_img():
bg = numpy.array(image.open('b.png'))
with open("bilibili_wc.txt", "r",encoding='utf-8') as f:
txt = f.read()
word = WordCloud(background_color="white", \
width=500, \
height=500,
font_path='simhei.ttf',
mask=bg,
).generate(txt)
word.to_file('test.png')
print("詞雲圖檔已儲存")
plt.imshow(word) # 使用plt庫顯示圖檔
plt.axis("off")
plt.show()
成果展示
if __name__ == '__main__':
get_text()
get_wc()
get_img()
需要彈幕資料和源碼的同學
評論區評論【張三】擷取
我是一條,一個在網際網路摸爬滾打的程式員。
道阻且長,行則将至。
大家的 【點贊,收藏,關注】 就是一條創作的最大動力,我們下期見!
注:關于本篇部落格有任何問題和建議,歡迎大家留言!