寫在前面
個人覺得 Java 集合類在面試過程中是個超高頻的子產品,是以一定要認真準備每個知識點。那麼我個人學習這塊知識點的方法是:
1、閱讀源碼:這一塊的考點可以說就是看你對有沒有閱讀過集合類的源碼以及對其的掌握程度。因為在平時的開發中幾乎每天都在和集合類打交道,隻有了解清楚它們底層的實作原理,才能在日常業務開發中選擇合适的集合。可能會有人說閱讀源碼比較枯燥,看不下去,但是 Java 集合類的源碼真的還好,并不像 Spring 的 AOP/IOC 那樣複雜;
2、做筆記:因為看完源碼很快就會忘了,是以需要對關鍵的源碼部分加以注釋做成筆記,這裡推薦寫部落格或者寫在 github 倉庫中,友善後面面試時複習;
3、看大佬們的源碼分析文章:因為你看的可是 JDK 的源碼,其中很多設計精妙之處不是“我等菜雞”随便就可以看出來的,是以多看看大佬們的文章,肯定會有意外的收獲;
4、看面經:這個也是少不了的,了解面試官們問問題的方式和頻率,可以有優先級的準備。
1、Java 中常用的容器有哪些?
常見容器主要包括 Collection 和 Map 兩種,Collection 存儲着對象的集合,而 Map 存儲着鍵值對(兩個對象)的映射表。
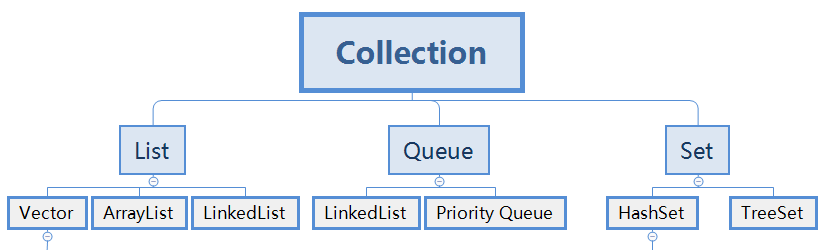

- Collection
- Set
- SetTreeSet:基于紅黑樹實作,支援有序性操作,例如:根據一個範圍查找元素的操作。但是查找效率不如 HashSet,HashSet 查找的時間複雜度為 O(1),TreeSet 則為 O(logN)。
- HashSet:基于哈希表實作,支援快速查找,但不支援有序性操作。并且失去了元素的插入順序資訊,也就是說使用 Iterator 周遊 HashSet 得到的結果是不确定的。
- LinkedHashSet:具有 HashSet 的查找效率,且内部使用雙向連結清單維護元素的插入順序。
- List
- ArrayList:基于動态數組實作,支援随機通路。
- Vector:和 ArrayList 類似,但它是線程安全的。
- LinkedList:基于雙向連結清單實作,隻能順序通路,但是可以快速地在連結清單中間插入和删除元素。不僅如此,LinkedList 還可以用作棧、隊列和雙向隊列。
- Queue
- LinkedList:可以用它來實作雙向隊列。
- PriorityQueue:基于堆結構實作,可以用它來實作優先隊列。
- Map
- TreeMap:基于紅黑樹實作。
- HashMap:基于哈希表實作。
- HashTable:和 HashMap 類似,但它是線程安全的,這意味着同一時刻多個線程可以同時寫入 HashTable 并且不會導緻資料不一緻。它是遺留類,不應該去使用它。現在可以使用 ConcurrentHashMap 來支援線程安全,并且 ConcurrentHashMap 的效率會更高,因為 ConcurrentHashMap 引入了分段鎖。
- LinkedHashMap:使用雙向連結清單來維護元素的順序,順序為插入順序或者最近最少使用(LRU)順序。
2、ArrayList 和 LinkedList 的差別?
ArrayList:底層是基于數組實作的,查找快,增删較慢;
LinkedList:底層是基于連結清單實作的。确切的說是循環雙向連結清單(JDK1.6 之前是雙向循環連結清單、JDK1.7 之後取消了循環),查找慢、增删快。LinkedList 連結清單由一系清單項連接配接而成,一個表項包含 3 個部分:元素内容、前驅表和後驅表。連結清單内部有一個 header 表項,既是連結清單的開始也是連結清單的結尾。header 的後繼表項是連結清單中的第一個元素,header 的前驅表項是連結清單中的最後一個元素。
補充:
ArrayList 的增删未必就是比 LinkedList 要慢:
1. 如果增删都是在末尾來操作【每次調用的都是 remove() 和 add()】,此時 ArrayList 就不需要移動和複制數組來進行操作了。如果資料量有百萬級的時,速度是會比 LinkedList 要快的。
2. 如果删除操作的位置是在中間。由于 LinkedList 的消耗主要是在周遊上,ArrayList 的消耗主要是在移動和複制上(底層調用的是 arrayCopy() 方法,是 native 方法)。LinkedList 的周遊速度是要慢于 ArrayList 的複制移動速度的如果資料量有百萬級的時,還是 ArrayList 要快。
3、ArrayList 實作 RandomAccess 接口有何作用?為何 LinkedList 卻沒實作這個接口?
1. RandomAccess 接口隻是一個标志接口,隻要 List 集合實作這個接口,就能支援快速随機通路。通過檢視 Collections 類中的 binarySearch() 方法,可以看出,判斷 List 是否實作 RandomAccess 接口來實行indexedBinarySerach(list, key) 或 iteratorBinarySerach(list, key)方法。再通過檢視這兩個方法的源碼發現:實作 RandomAccess 接口的 List 集合采用一般的 for 循環周遊,而未實作這接口則采用疊代器,即 ArrayList 一般采用 for 循環周遊,而 LinkedList 一般采用疊代器周遊;
2. ArrayList 用 for 循環周遊比 iterator 疊代器周遊快,LinkedList 用 iterator 疊代器周遊比 for 循環周遊快。是以說,當我們在做項目時,應該考慮到 List 集合的不同子類采用不同的周遊方式,能夠提高性能。
4、ArrayList 的擴容機制?
推薦閱讀:
https://juejin.im/post/5d42ab5e5188255d691bc8d6
- 當使用 add 方法的時候首先調用 ensureCapacityInternal 方法,傳入 size+1 進去,檢查是否需要擴充 elementData 數組的大小;
- newCapacity = 擴充數組為原來的 1.5 倍(不能自定義),如果還不夠,就使用它指定要擴充的大小 minCapacity ,然後判斷 minCapacity 是否大于 MAX_ARRAY_SIZE(Integer.MAX_VALUE - 8) ,如果大于,就取 Integer.MAX_VALUE;
- 擴容的主要方法:grow;
- ArrayList 中 copy 數組的核心就是 System.arraycopy 方法,将 original 數組的所有資料複制到 copy 數組中,這是一個本地方法。
5、Array 和 ArrayList 有何差別?什麼時候更适合用 Array?
- Array 可以容納基本類型和對象,而 ArrayList 隻能容納對象;
- Array 是指定大小的,而 ArrayList 大小是固定的。
什麼時候更适合使用 Array:
- 如果清單的大小已經指定,大部分情況下是存儲和周遊它們;
- 對于周遊基本資料類型,盡管 Collections 使用自動裝箱來減輕編碼任務,在指定大小的基本類型的清單上工作也會變得很慢;
- 如果你要使用多元數組,使用 [ ][ ] 比 List> 更容易。
6、HashMap 的實作原理/底層資料結構?JDK1.7 和 JDK1.8
JDK1.7:Entry數組 + 連結清單
JDK1.8:Node 數組 + 連結清單/紅黑樹,當連結清單上的元素個數超過 8 個并且數組長度 >= 64 時自動轉化成紅黑樹,節點變成樹節點,以提高搜尋效率和插入效率到 O(logN)。Entry 和 Node 都包含 key、value、hash、next 屬性。
7、HashMap 的 put 方法的執行過程?
當我們想往一個 HashMap 中添加一對 key-value 時,系統首先會計算 key 的 hash 值,然後根據 hash 值确認在 table 中存儲的位置。若該位置沒有元素,則直接插入。否則疊代該處元素連結清單并依次比較其 key 的 hash 值。如果兩個 hash 值相等且 key 值相等(e.hash == hash && ((k = e.key) == key || key.equals(k))),則用新的 Entry 的 value 覆寫原來節點的 value。如果兩個 hash 值相等但 key 值不等 ,則将該節點插入該連結清單的鍊頭。
8、HashMap 的 get 方法的執行過程?
通過 key 的 hash 值找到在 table 數組中的索引處的 Entry,然後傳回該 key 對應的 value 即可。
在這裡能夠根據 key 快速的取到 value 除了和 HashMap 的資料結構密不可分外,還和 Entry 有莫大的關系。HashMap 在存儲過程中并沒有将 key,value 分開來存儲,而是當做一個整體 key-value 來處理的,這個整體就是Entry 對象。同時 value 也隻相當于 key 的附屬而已。在存儲的過程中,系統根據 key 的 HashCode 來決定 Entry 在 table 數組中的存儲位置,在取的過程中同樣根據 key 的 HashCode 取出相對應的 Entry 對象(value 就包含在裡面)。
9、HashMap 的 resize 方法的執行過程?
有兩種情況會調用 resize 方法:
1. 第一次調用 HashMap 的 put 方法時,會調用 resize 方法對 table 數組進行初始化,如果不傳入指定值,預設大小為 16。
2. 擴容時會調用 resize,即 size > threshold 時,table 數組大小翻倍。
每次擴容之後容量都是翻倍。擴容後要将原數組中的所有元素找到在新數組中合适的位置。
當我們把 table[i] 位置的所有 Node 遷移到 newtab 中去的時候:這裡面的 node 要麼在 newtab 的 i 位置(不變),要麼在 newtab 的 i + n 位置。也就是我們可以這樣處理:把 table[i] 這個桶中的 node 拆分為兩個連結清單 l1 和 l2:如果 hash & n == 0,那麼目前這個 node 被連接配接到 l1 連結清單;否則連接配接到 l2 連結清單。這樣下來,當周遊完 table[i] 處的所有 node 的時候,我們得到兩個連結清單 l1 和 l2,這時我們令 newtab[i] = l1,newtab[i + n] = l2,這就完成了 table[i] 位置所有 node 的遷移(rehash),這也是 HashMap 中容量一定的是 2 的整數次幂帶來的友善之處。
10、HashMap 的 size 為什麼必須是 2 的整數次方?
- 這樣做總是能夠保證 HashMap 的底層數組長度為 2 的 n 次方。當 length 為 2 的 n 次方時,h & (length - 1) 就相當于對 length 取模,而且速度比直接取模快得多,這是 HashMap 在速度上的一個優化。而且每次擴容時都是翻倍。
- 如果 length 為 2 的次幂,則 length - 1 轉化為二進制必定是 11111……的形式,在與 h 的二進制進行與操作時效率會非常的快,而且空間不浪費。但是,如果 length 不是 2 的次幂,比如:length 為 15,則 length - 1 為 14,對應的二進制為 1110,在于 h 與操作,最後一位都為 0 ,而 0001,0011,0101,1001,1011,0111,1101 這幾個位置永遠都不能存放元素了,空間浪費相當大,更糟的是這種情況中,數組可以使用的位置比數組長度小了很多,這意味着進一步增加了碰撞的幾率,減慢了查詢的效率,這樣就會造成空間的浪費。
11、HashMap 多線程死循環問題?
詳細請閱讀:
https://blog.csdn.net/xuefeng0707/article/details/40797085
https://blog.csdn.net/dgutliangxuan/article/details/78779448
主要是多線程同時 put 時,如果同時觸發了 rehash 操作,會導緻 HashMap 中的連結清單中出現循環節點,進而使得後面 get 的時候,會死循環。
12、HashMap 的 get 方法能否判斷某個元素是否在 map 中?
HashMap 的 get 函數的傳回值不能判斷一個 key 是否包含在 map 中,因為 get 傳回 null 有可能是不包含該 key,也有可能該 key 對應的 value 為 null。因為 HashMap 中允許 key 為 null,也允許 value 為 null。
13、HashMap 與 HashTable 的差別是什麼?
- HashTable 基于 Dictionary 類,而 HashMap 是基于 AbstractMap。Dictionary 是任何可将鍵映射到相應值的類的抽象父類,而 AbstractMap 是基于 Map 接口的實作,它以最大限度地減少實作此接口所需的工作。
- HashMap 的 key 和 value 都允許為 null,而 Hashtable 的 key 和 value 都不允許為 null。HashMap 遇到 key 為 null 的時候,調用 putForNullKey 方法進行處理,而對 value 沒有處理;Hashtable 遇到 null,直接傳回 NullPointerException。
- Hashtable 是線程安全的,而 HashMap 不是線程安全的,但是我們也可以通過 Collections.synchronizedMap(hashMap),使其實作同步。
HashTable的補充:
HashTable 和 HashMap 的實作原理幾乎一樣,差别無非是
1. HashTable 不允許 key 和 value 為 null;
2. HashTable 是線程安全的。但是 HashTable 線程安全的政策實作代價卻太大了,簡單粗暴,get/put 所有相關操作都是 synchronized 的,這相當于給整個哈希表加了一把大鎖,多線程通路時候,隻要有一個線程通路或操作該對象,那其他線程隻能阻塞,相當于将所有的操作串行化,在競争激烈的并發場景中性能就會非常差。
14、HashMap 與 ConcurrentHashMap 的差別是什麼?
HashMap 不是線程安全的,而 ConcurrentHashMap 是線程安全的。
ConcurrentHashMap 采用鎖分段技術,将整個Hash桶進行了分段segment,也就是将這個大的數組分成了幾個小的片段 segment,而且每個小的片段 segment 上面都有鎖存在,那麼在插入元素的時候就需要先找到應該插入到哪一個片段 segment,然後再在這個片段上面進行插入,而且這裡還需要擷取 segment 鎖,這樣做明顯減小了鎖的粒度。
15、HashTable 和 ConcurrentHashMap 的差別?
HashTable 和 ConcurrentHashMap 相比,效率低。 Hashtable 之是以效率低主要是使用了 synchronized 關鍵字對 put 等操作進行加鎖,而 synchronized 關鍵字加鎖是對整張 Hash 表的,即每次鎖住整張表讓線程獨占,緻使效率低下,而 ConcurrentHashMap 在對象中儲存了一個 Segment 數組,即将整個 Hash 表劃分為多個分段;而每個Segment元素,即每個分段則類似于一個Hashtable;這樣,在執行 put 操作時首先根據 hash 算法定位到元素屬于哪個 Segment,然後對該 Segment 加鎖即可,是以, ConcurrentHashMap 在多線程并發程式設計中可是實作多線程 put操作。
16、ConcurrentHashMap 的實作原理是什麼?
資料結構
JDK 7:中 ConcurrentHashMap 采用了數組 + Segment + 分段鎖的方式實作。
JDK 8:中 ConcurrentHashMap 參考了 JDK 8 HashMap 的實作,采用了數組 + 連結清單 + 紅黑樹的實作方式來設計,内部大量采用 CAS 操作。
ConcurrentHashMap 采用了非常精妙的"分段鎖"政策,ConcurrentHashMap 的主幹是個 Segment 數組。
final Segment<K,V>[] segments; 複制
Segment 繼承了 ReentrantLock,是以它就是一種可重入鎖(ReentrantLock)。在 ConcurrentHashMap,一個 Segment 就是一個子哈希表,Segment 裡維護了一個 HashEntry 數組,并發環境下,對于不同 Segment 的資料進行操作是不用考慮鎖競争的。就按預設的 ConcurrentLevel 為 16 來講,理論上就允許 16 個線程并發執行。
是以,對于同一個 Segment 的操作才需考慮線程同步,不同的 Segment 則無需考慮。Segment 類似于 HashMap,一個 Segment 維護着一個HashEntry 數組:
transient volatile HashEntry<K,V>[] table; 複制
HashEntry 是目前我們提到的最小的邏輯處理單元了。一個 ConcurrentHashMap 維護一個 Segment 數組,一個 Segment 維護一個 HashEntry 數組。是以,ConcurrentHashMap 定位一個元素的過程需要進行兩次 Hash 操作。第一次 Hash 定位到 Segment,第二次 Hash 定位到元素所在的連結清單的頭部。
17、HashSet 的實作原理?
HashSet 的實作是依賴于 HashMap 的,HashSet 的值都是存儲在 HashMap 中的。在 HashSet 的構造法中會初始化一個 HashMap 對象,HashSet 不允許值重複。是以,HashSet 的值是作為 HashMap 的 key 存儲在 HashMap 中的,當存儲的值已經存在時傳回 false。
18、HashSet 怎麼保證元素不重複的?
public boolean add(E e) {
return map.put(e, PRESENT)==null;
} 複制
元素值作為的是 map 的 key,map 的 value 則是 PRESENT 變量,這個變量隻作為放入 map 時的一個占位符而存在,是以沒什麼實際用處。其實,這時候答案已經出來了:HashMap 的 key 是不能重複的,而這裡HashSet 的元素又是作為了 map 的 key,當然也不能重複了。
19、LinkedHashMap 的實作原理?
LinkedHashMap 也是基于 HashMap 實作的,不同的是它定義了一個 Entry header,這個 header 不是放在 Table 裡,它是額外獨立出來的。LinkedHashMap 通過繼承 hashMap 中的 Entry,并添加兩個屬性 Entry before,after 和 header 結合起來組成一個雙向連結清單,來實作按插入順序或通路順序排序。
LinkedHashMap 定義了排序模式 accessOrder,該屬性為 boolean 型變量,對于通路順序,為 true;對于插入順序,則為 false。一般情況下,不必指定排序模式,其疊代順序即為預設為插入順序。
20、Iterator 怎麼使用?有什麼特點?
疊代器是一種設計模式,它是一個對象,它可以周遊并選擇序列中的對象,而開發人員不需要了解該序列的底層結構。疊代器通常被稱為“輕量級”對象,因為建立它的代價小。Java 中的 Iterator 功能比較簡單,并且隻能單向移動:
- 使用方法 iterator() 要求容器傳回一個 Iterator。第一次調用 Iterator 的 next() 方法時,它傳回序列的第一個元素。注意:iterator() 方法是 java.lang.Iterable 接口,被 Collection 繼承。
- 使用 next() 獲得序列中的下一個元素。
- 使用 hasNext() 檢查序列中是否還有元素。
- 使用 remove() 将疊代器新傳回的元素删除。
21、 Iterator 和 ListIterator 有什麼差別?
Iterator 可用來周遊 Set 和 List 集合,但是 ListIterator 隻能用來周遊 List。Iterator 對集合隻能是前向周遊,ListIterator 既可以前向也可以後向。ListIterator 實作了 Iterator 接口,并包含其他的功能,比如:增加元素,替換元素,擷取前一個和後一個元素的索引等等。
22、Iterator 和 Enumeration 接口的差別?
與 Enumeration 相比,Iterator 更加安全,因為當一個集合正在被周遊的時候,它會阻止其它線程去修改集合。否則會抛出 ConcurrentModificationException 異常。這其實就是 fail-fast 機制。具體差別有三點:
- Iterator 的方法名比 Enumeration 更科學;
- Iterator 有 fail-fast 機制,比 Enumeration 更安全;
- Iterator 能夠删除元素,Enumeration 并不能删除元素。
23、fail-fast 與 fail-safe 有什麼差別?
Iterator 的 fail-fast 屬性與目前的集合共同起作用,是以它不會受到集合中任何改動的影響。Java.util 包中的所有集合類都被設計為 fail-fast 的,而 java.util.concurrent 中的集合類都為 fail-safe 的。當檢測到正在周遊的集合的結構被改變時,fail-fast 疊代器抛出ConcurrentModificationException,而 fail-safe 疊代器從不抛出 ConcurrentModificationException。
24、Collection 和 Collections 有什麼差別?
Collection:是最基本的集合接口,一個 Collection 代表一組 Object,即 Collection 的元素。它的直接繼承接口有 List,Set 和 Queue。
Collections:是不屬于 Java 的集合架構的,它是集合類的一個工具類/幫助類。此類不能被執行個體化, 服務于 Java 的 Collection 架構。它包含有關集合操作的靜态多态方法,實作對各種集合的搜尋、排序、線程安全等操作