1. "兩級緩存+持久化"結構
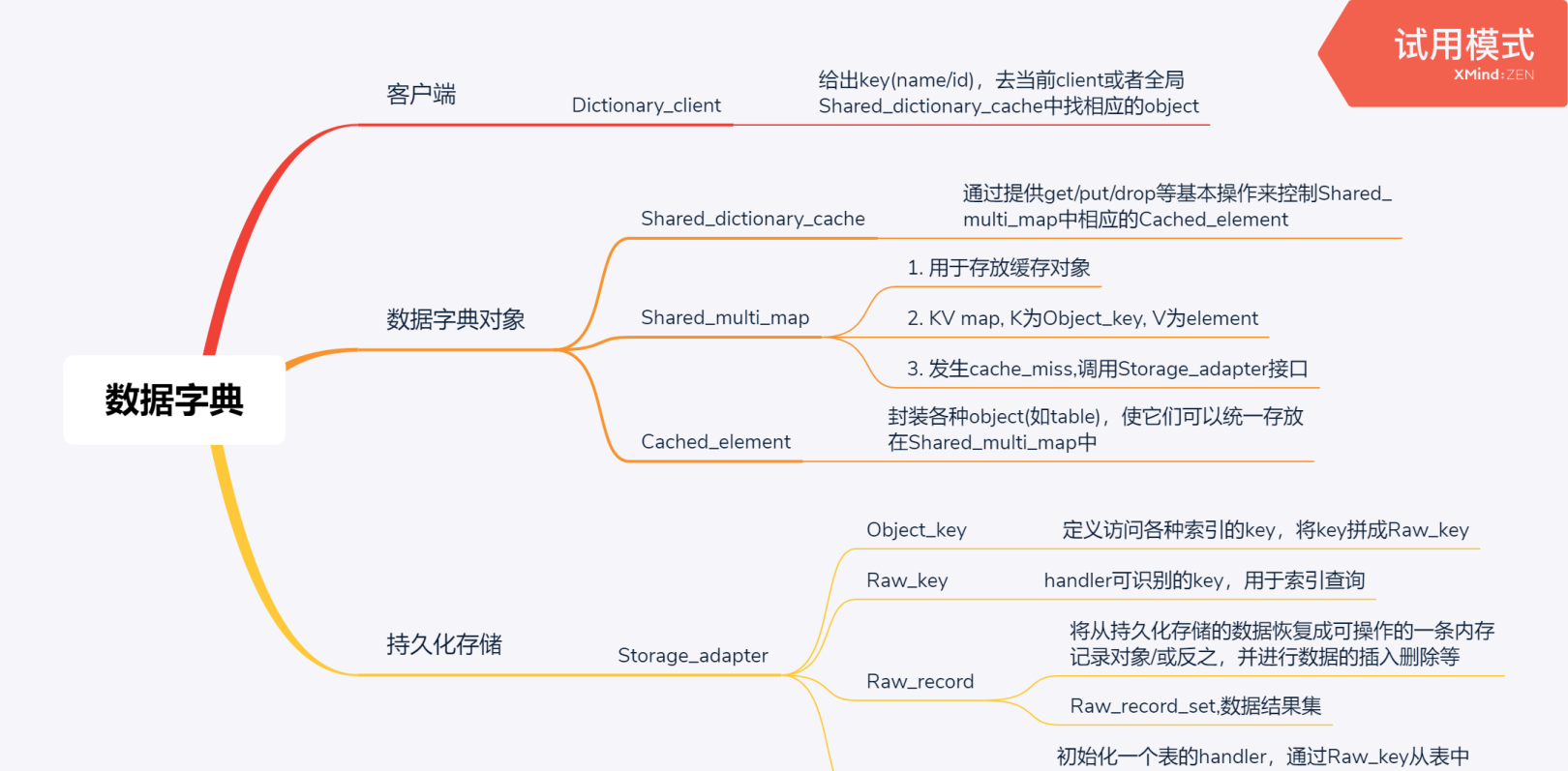
整個MySQL 8.0的資料字典實作在資料字典對象分布上呈現
|--Dictionary_client
|--Shared_dictionary_cache
|--Storage_adapte 複制
這種三級存儲的方式。
1.1 Dictionary_client
Dictionary_client是整個資料字典的用戶端,使用者對于資料字典的操作都是通過該client實作的。
Dictionary_client中維護有三個map作為該用戶端私有的緩存,如果能在私有緩存命中的話,就不需要去全局公有的Shared_dictionary_cache,甚至持久化存儲中擷取了。
- m_registry_uncommitted
client調用store/update接口時将object放到uncommitted map中
- m_registry_committed
事務送出後,object從uncommitted map移到committed map中
- m_registry_dropped
執行drop操作後,object移入dropped map
這三個map的類型都是Local_multi_map,本質是對std::map的封裝。
每個client退出後,調用Auto_releaser的析構函數将每個map清空。
主要接口:
- acquire() acquire通過參數提供的各種類型的資訊(name/id等)來組裝查詢的key。流程:
- acquire_uncommitted,從未送出map中檢視是該對象是否處于未送出狀态,如果是,則傳回該未送出對象
- 從m_registry_committed中檢視該對象是否處于已送出狀态,如果是,那麼這個對象可能被修改了,rename或者drop
- 該對象不存在于以上任一map,那就去全局的shared_dictionary_cache中去get
- store()
- 調用Storage_adapter的store接口
- 将操作對象從uncomitted_map移動至committed_map
- drop()
- 調用Storage_adapter的drop接口
- 将被drop的對象設定為失效
- 将被drop的對象放入dropped_map
- update()
- 通過object_id确認該對象确實存在
- 從uncommitted_map中看一下同一個client中是否已經修改過該對象
- 調用Storage_adapter的store接口
- 将該對象從uncommitted_map中移除
1.2 Shared_dictionary_cache
上面說到,在client的三個私有map中(極大)可能會有cache miss的現象,比如一個client中已commit的對象不可能被另一個client讀到,這時候就要用到全局的緩存Shared_dictionary_cache,Shared_dictionary_cache本身也是map,30多張資料字典表各自維護一個map,其中存放的對象是Object_key + Element_cache,Element_cache是對資料字典對象的一層封裝,目的在于可以統一管理所有類型的資料字典對象。以下是一個element_cache所包含的内容,實際上就是一個指向原資料字典對象的指針以及屬于這個資料字典對象的key資訊。
const T *m_object; // Pointer to the actual object.
uint m_ref_counter; // Number of concurrent object usages.
/*
全局對象的 priamry key,一個ulonglong類型的id
Primary_id_key Id_key;
*/
Key_wrapper<typename T::Id_key> m_id_key; // The id key for the object.
/*
全局對象的 name
Item_name_key Name_key;
*/
Key_wrapper<typename T::Name_key> m_name_key; // The name key for the object.
/*
輔助kye,暫時用不到
Void_key Aux_key
*/
Key_wrapper<typename T::Aux_key> m_aux_key; // The aux key for the object. 複制
主要接口:
- get():
- 通過key(Shared_multi_map->get())->找到傳回
- 找不到調用get_uncached()從持久化存儲中讀取->找到則寫回緩存(Shared_multi_map->put())
- get_uncached():
- 調用Storage_adapter的get接口讀持久化存儲
- put():
- 将element_cache放入相應的map,如果map中已經存在該element_cache,傳回這個element_cache的引用,element_cache的引用計數加1
- drop():
- 從map中移除element_cache
- element_cache中的object對象被釋放,element_cache本身被放入資源池中,下次要配置設定element_map就從資源池中擷取并初始化就可以重新使用
- dump():
- 調試接口,列印map中的所有元素。所有的map都有這個接口,在進行調試的時候十分有用。
Shared_dictionary_cache基于一個最重要的資料結構便是Shared_multi_map,Share_multi_map繼承自Multi_map_base(與上述client的Local_multi_map一緻,再往上找的話就是std::map),通過擴充了Autolocker内部類實作multi_map的線程間同步,以及map中元素的生命周期管理。
To ensure that the mutex is locked and unlocked correctly.
To delete unused elements and objects outside the scope
where the mutex is locked.
重要成員變量:
/*
m_free_list實際上維護了一個LRU隊列,引用計數歸零的element
說明目前沒有被使用,是以被放到free_list的尾部。可以看作是map的
緩存。
*/
Free_list<Cache_element<T>> m_free_list; // Free list.
/*
1.在進行put操作時,我們需要根據給定的object建立新的element,
此時并不知道cache中是否有該對象,執行get之後,如果找到了該element,
那麼該element就應該被丢棄,我們不會把它直接删除,隻要m_element_pool
還有空間,就會把它先存到pool中,供下次使用。
2.在進行remove操作時,被remove的element也會被存入element_pool中。
*/
std::vector<Cache_element<T> *> m_element_pool; // Pool of allocated elements.
複制
其中重要的成員函數就是對map的讀寫:
1. template <typename K>
Cache_element<T> *use_if_present(const K &key);
/*
對應的其實就是get,通過key傳回被封裝成Cache_element的object的指針,
傳回指針的同時該element對象的引用計數+1。
*/
2. void remove(Cache_element<T> *element, Autolocker *lock);
/*
調用父類Multi_map_base的remove_single_element()方法。
*/
3. void add_single_element(Cache_element<T> *element)方法。
/*
而put則直接調用父類Multi_map_base的add_single_element()方法。
*/ 複制
内部類 Autolocker
class Autolocker {
private:
// Vector containing objects to be deleted unconditionally.
typedef std::vector<const T *, Malloc_allocator<const T *>>
Object_list_type;
Object_list_type m_objects_to_delete;
// Vector containing elements to be deleted unconditionally, which
// happens when elements are evicted while the pool is already full.
typedef std::vector<const Cache_element<T> *,
Malloc_allocator<const Cache_element<T> *>>
Element_list_type;
Element_list_type m_elements_to_delete;
...
} 複制
注:
m_objects_to_delete->object對象不複用,用完即删。m_elements_to_delete->element對象放回element_pool,下次使用時直接從pool中取出init後繼續使用。
1.3 Storage_adapter(讀寫InnoDB)
既然是cache就有可能産生cache miss,這裡的cache miss指的是通過特定的key在Shared_dictionary_cache維護的map執行個體中找不到目标對象,這時候就要調用Storage_adapter的接口來讀取持久化存儲中的資料對象了(MySQL資料字典持久化存儲在InnoDB)
主要接口:
- core_get()
- 從m_core_registry(一個專門存放系統資料字典對象的map)中擷取core_object(如dd_properties/tables之類的資料字典表)
- core_store()
- 存儲一個系統表core_object對象
- core_drop()
- 删除一個系統表core_object對象
- get()
- 先通過core_get找系統表core_object對象
- 在bootstrap::Stage::CREATED_TABLES階段之前的所有查詢都認為資料字典對象不存在
- 打開一個讀取資料字典的事務,去讀取持久化存儲,如果找到則将元組中所含的資料字典資訊恢複成記憶體object
- store()
- store接口兼有update/insert功能,它會先查一次主鍵,存在就調用update邏輯,不存在則調用insert邏輯
- drop()
- delete一條表對象記錄(及與之相關的所有記錄)
2. 查詢
2.1 key的定義
現在我們知道資料字典對象分布在dictionary_client/Shared_dictionary_cache/Storage_adapter中,那麼查詢中如何擷取相應的資料字典對象呢?
一二級cache都是map結構,是以要拿資料字典對象隻要知道key就可以,資料字典所有的key都繼承自
Object_key
,所有類型定義在
sql/dd/impl/raw/object_keys.h
.
以Primary_id_key為例:每個資料字典表都有一個id列作為主鍵,而Primary_id_key就是用于基于id的讀操作
-
Primary_id_keyclass Primary_id_key : public Object_key {
public:
Primary_id_key() {}
Primary_id_key(Object_id object_id) : m_object_id(object_id) {}
// Update a preallocated instance.
void update(Object_id object_id) { m_object_id = object_id; }
public:
virtual Raw_key *create_access_key(Raw_table *db_table) const;
virtual String_type str() const;
bool operator<(const Primary_id_key &rhs) const {
return m_object_id < rhs.m_object_id; 複制
}
private:
Object_id m_object_id;
};
Primary_id_key隻有一個成員變量m_object_id,其對應的就是各個資料字典表的主鍵。
主要接口:
- update():
- 用于更新Primary_id_key
- create_access_key():
- 将目前的Primary_id_key組裝成Raw_key,Raw_key将會在下文介紹
- str():
- 調試接口,列印key資訊
- operator<():
- 重載<,用于在map中判斷key的大小關系
2.2 從map中查詢
從map中查詢比較簡單,因為已經在key中已經重載了比較符,隻要調用相應的get接口(實際上是map的find接口)就可以。
2.3 從持久化存儲中查詢
從持久化中查找資訊需要重新建構key,由此引出Raw_key/Raw_record/Raw_table的概念。
struct Raw_key {
uchar key[MAX_KEY_LENGTH];
int index_no;
int key_len;
key_part_map keypart_map;
Raw_key(int p_index_no, int p_key_len, key_part_map p_keypart_map)
: index_no(p_index_no), key_len(p_key_len), keypart_map(p_keypart_map) {}
}; 複制
Raw_key是一個簡單的結構體,可以把它看作是去查詢持久化存儲索引的key,需要關注的有兩個變量。
- index_no:需要查詢的索引是表上的第幾個索引,所有資料字典表的主鍵索引都是第一個。
- keypart_map:一個key中可能包含了好幾列的資訊,MySQL使用bitmap(小端存儲)的形式來标記到底會用到哪幾列的。比如,一個key中包含了三列:
a b c
1 0 0 // keypart_map = 1,隻用第一列a
1 1 0 // keypart_map = 3,用a/b兩列
1 0 1 // keypart_map = 5,用a/c兩列
... 複制
這個在基于複合key進行範圍掃描的時候非常有用。
Raw_table維護了一個待通路資料字典表的table_list,從這裡面可以拿到一個TABLE對象,進而可以通過它來讀寫持久化中的元組資訊(TABLE->record0).
主要接口:
- find_record():
- 通過key從持久化存儲中找到一條資料,并将資料填寫到Raw_record
- prepare_record_for_update():
- 讀出一條已存在的record,并将更新的資訊寫入TABLE->record0
- prepare_record_for_insert():
- 建構一條新的Raw_record(Raw_new_record)
- open_record_set():
- 初始化一次掃描,并産生一個符合條件的記錄結果集。
Raw_record是一個持久化元組buffer和可操作記憶體對象的一個轉換載體。
主要接口:
- update():
- 實際上就是調用handler的ha_update_row接口,資料由Raw_table的prepare_record_for_update提供
- drop():
- 實際上是調用handler的ha_delete_row接口
- store():
- 将資料存入到record的TABLE對象的filed中
- read_xx():
- 将資料從TABLE對象的field中按類型讀取出來
- insert()(Raw_new_record的成員,Raw_record的子類):
- 實際上就是調用handler的ha_write_row接口,資料由Raw_table的prepare_record_for_insert提供
Raw_record_set是由Raw_table::open_record_set産生的結果集,可以調用其提供的next()接口實作結果集的周遊。
主要接口:
- current_record():
- 指向目前Raw_record
- next():
- 指向下一條Raw_record
4.代碼分布及類的繼承關系
4.1 代碼分布
- 資料字典相關代碼位于sql/dd
- 資料字典表定義(表結構/索引/限制等)代碼位sql/dd/impl/tablesundefinedtables路徑下面主要是對資料字典表的定義,其中.cc檔案就是建立表的定義,如
tables.cc
tables.h
- 對資料字典對象進行相應的操作代碼位sql/dd/impl/typesundefinedtypes路徑下面實作了各個資料字典表從記憶體對象到持久化存儲互相轉換的内容,如
restore_attributes
store_attributes
serialize/deserialize
xx_impl.h/xx_impl.cc
- 記憶體對象到持久化存儲的互動,讀寫存儲引擎等代碼位于sql/dd/impl/cache(包括key的定義等)
4.2 主要類的繼承關系
資料字典表2
namespace dd {
Weak_object
Entity_object
Dictionary_object
Tablespace
Schema
Event
Routine
Function
Procedure
Charset
Collation
Abstract_table
Table
View
Spatial_reference_system
Index_stat
Table_stat
Partition
Trigger
Index
Foreign_key
Parameter
Column
Partition_index
Partition_value
View_routine
View_table
Tablespace_file
Foreign_key_element
Index_element
Column_type_element
Parameter_type_element
Object_table
Dictionary_object_table
Object_type
Object_table_definition
} 複制
資料字典緩存2
dd::cache {
dd::cache::Dictionary_client
Object_registry
Element_map
Multi_map_base
Local_multi_map
Shared_multi_map
Cache_element
Free_list
Shared_dictionary_cache
Storage_adapter
} 複制
參考
[1] https://note.youdao.com/yws/public/resource/d73e1962c7f00aadd4df680f2e9d1722/xmlnote/18D8F2ECF3CD470FA932DA04FC6346AA/5481
[2] https://yq.aliyun.com/articles/61286
[3] https://blog.51cto.com/14136767/2334464
資料字典腦圖