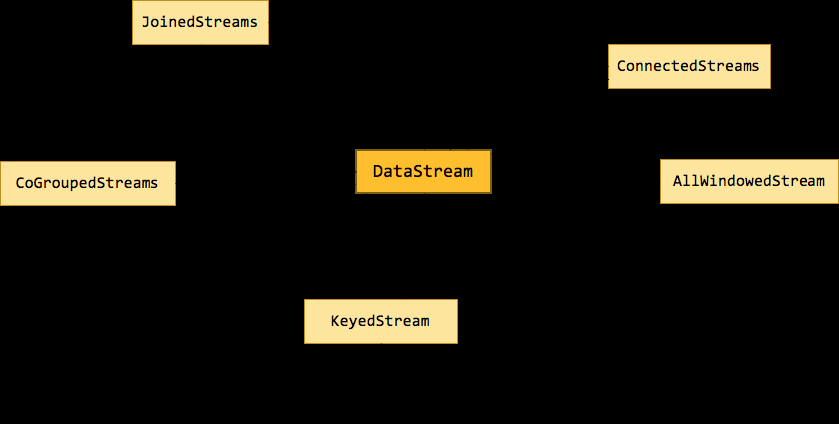
Flink 為流處理和批處理分别提供了 DataStream API 和 DataSet API。正是這種高層的抽象和 flunent API 極大地便利了使用者編寫大資料應用。不過很多初學者在看到官方文檔中那一大坨的轉換時,常常會蒙了圈,文檔中那些隻言片語也很難講清它們之間的關系。是以本文将介紹幾種關鍵的資料流類型,它們之間是如何通過轉換關聯起來的。下圖展示了 Flink 中目前支援的主要幾種流的類型,以及它們之間的轉換關系。
1. DataStream
DataStream
是
Flink
流處理 API 中最核心的資料結構。它代表了一個運作在多個分區上的并行流。一個
DataStream
可以從
StreamExecutionEnvironment
通過
env.addSource(SourceFunction)
獲得。
DataStream
上的轉換操作都是逐條的,比如
map()
,
flatMap()
,
filter()
。
DataStream
也可以執行
rebalance
(再平衡,用來減輕資料傾斜)和
broadcaseted
(廣播)等分區轉換。
val stream: DataStream[MyType] = env.addSource(new FlinkKafkaConsumer08[String](...))
val str1: DataStream[(String, MyType)] = stream.flatMap { ... }
val str2: DataStream[(String, MyType)] = stream.rebalance()
val str3: DataStream[AnotherType] = stream.map { ... } 複制
上述 DataStream 上的轉換在運作時會轉換成如下的執行圖:

如上圖的執行圖所示,
DataStream
各個算子會并行運作,算子之間是資料流分區。如
Source
的第一個并行執行個體(S1)和
flatMap()
的第一個并行執行個體(m1)之間就是一個資料流分區。而在
flatMap()
和
map()
之間由于加了
rebalance()
,它們之間的資料流分區就有3個子分區(m1的資料流向3個map()執行個體)。這與
Apache Kafka
是很類似的,把流想象成
Kafka Topic
,而一個流分區就表示一個
Topic Partition
,流的目标并行算子執行個體就是
Kafka Consumers
。
2. KeyedStream
KeyedStream
用來表示根據指定的
key
進行分組的資料流。一個
KeyedStream
可以通過調用
DataStream.keyBy()
來獲得。而在
KeyedStream
上進行任何
transformation
都将轉變回
DataStream
。在實作中,
KeyedStream
是把
key
的資訊寫入到了
transformation
中。每條記錄隻能通路所屬
key
的狀态,其上的聚合函數可以友善地操作和儲存對應
key
的狀态。
3. WindowedStream & AllWindowedStream
WindowedStream
代表了根據
key
分組,并且基于
WindowAssigner
切分視窗的資料流。是以
WindowedStream
都是從
KeyedStream
衍生而來的。而在
WindowedStream
上進行任何
transformation
也都将轉變回
DataStream
。
val stream: DataStream[MyType] = ...
val windowed: WindowedDataStream[MyType] = stream
.keyBy("userId")
.window(TumblingEventTimeWindows.of(Time.seconds(5))) // Last 5 seconds of data
val result: DataStream[ResultType] = windowed.reduce(myReducer) 複制
上述
WindowedStream
的樣例代碼在運作時會轉換成如下的執行圖:
Flink
的視窗實作中會将到達的資料緩存在對應的視窗
buffer
中(一個資料可能會對應多個視窗)。當到達視窗發送的條件時(由
Trigger
控制),
Flink
會對整個視窗中的資料進行處理。
Flink
在聚合類視窗有一定的優化,即不會儲存視窗中的所有值,而是每到一個元素執行一次聚合函數,最終隻儲存一份資料即可。
在
key
分組的流上進行視窗切分是比較常用的場景,也能夠很好地并行化(不同的
key
上的視窗聚合可以配置設定到不同的
task
去處理)。不過有時候我們也需要在普通流上進行視窗的操作,這就是
AllWindowedStream
。
AllWindowedStream
是直接在
DataStream
上進行
windowAll(...)
操作。
AllWindowedStream
的實作是基于
WindowedStream
的(Flink 1.1.x 開始)。
Flink
不推薦使用
AllWindowedStream
,因為在普通流上進行視窗操作,就勢必需要将所有分區的流都彙集到單個的
Task
中,而這個單個的
Task
很顯然就會成為整個Job的瓶頸。
4. JoinedStreams & CoGroupedStreams
雙流
Join
也是一個非常常見的應用場景。深入源碼你可以發現,
JoinedStreams
和
CoGroupedStreams
的代碼實作有80%是一模一樣的,
JoinedStreams
在底層又調用了
CoGroupedStreams
來實作
Join
功能。除了名字不一樣,一開始很難将它們區分開來,而且為什麼要提供兩個功能類似的接口呢?
實際上這兩者還是很點差別的。首先
co-group
側重的是
group
,是對同一個
key
上的兩組集合進行操作,而
join
側重的是
pair
,是對同一個
key
上的每對元素進行操作。
co-group
比
join
更通用一些,因為
join
隻是
co-group
的一個特例,是以
join
是可以基于
co-group
來實作的(當然有優化的空間)。而在
co-group
之外又提供了
join
接口是因為使用者更熟悉
join
(源于資料庫吧),而且能夠跟
DataSet API
保持一緻,降低使用者的學習成本。
JoinedStreams
和
CoGroupedStreams
是基于
Window
上實作的,是以
CoGroupedStreams
最終又調用了
WindowedStream
來實作。
val firstInput: DataStream[MyType] = ...
val secondInput: DataStream[AnotherType] = ...
val result: DataStream[(MyType, AnotherType)] = firstInput.join(secondInput)
.where("userId").equalTo("id")
.window(TumblingEventTimeWindows.of(Time.seconds(3)))
.apply (new JoinFunction () {...}) 複制
上述
JoinedStreams
的樣例代碼在運作時會轉換成如下的執行圖:
雙流上的資料在同一個
key
的會被分别配置設定到同一個
window
視窗的左右兩個籃子裡,當
window
結束的時候,會對左右籃子進行笛卡爾積進而得到每一對
pair
,對每一對
pair
應用
JoinFunction
。不過目前(Flink 1.1.x)
JoinedStreams
隻是簡單地實作了流上的
join
操作而已,距離真正的生産使用還是有些距離。因為目前
join
視窗的雙流資料都是被緩存在記憶體中的,也就是說如果某個
key
上的視窗資料太多就會導緻
JVM OOM
(然而資料傾斜是常态)。雙流
join
的難點也正是在這裡,這也是社群後面對
join
操作的優化方向,例如可以借鑒
Flink
在批處理
join
中的優化方案,也可以用
ManagedMemory
來管理視窗中的資料,并當資料超過門檻值時能spill到硬碟。
5. ConnectedStreams
在
DataStream
上有一個
union
的轉換
dataStream.union(otherStream1, otherStream2, ...)
,用來合并多個流,新的流會包含所有流中的資料。
union
有一個限制,就是所有合并的流的類型必須是一緻的。
ConnectedStreams
提供了和
union
類似的功能,用來連接配接兩個流,但是與
union
轉換有以下幾個差別:
-
ConnectedStreams
union
-
ConnectedStreams
union
-
ConnectedStreams
如下
ConnectedStreams
的樣例,連接配接
input
和
other
流,并在
input
流上應用
map1
方法,在
other
上應用
map2
方法,雙流可以共享狀态(比如計數)。
val input: DataStream[MyType] = ...
val other: DataStream[AnotherType] = ...
val connected: ConnectedStreams[MyType, AnotherType] = input.connect(other)
val result: DataStream[ResultType] =
connected.map(new CoMapFunction[MyType, AnotherType, ResultType]() {
override def map1(value: MyType): ResultType = { ... }
override def map2(value: AnotherType): ResultType = { ... }
}) 複制
當并行度為2時,其執行圖如下所示:
6. 總結
本文介紹通過不同資料流類型的轉換圖來解釋每一種資料流的含義、轉換關系。後面的文章會深入講解 Window 機制的實作,雙流 Join 的實作等。
原文:http://wuchong.me/blog/2016/05/20/flink-internals-streams-and-operations-on-streams/