實時計算在點評的使用場景
類别一:Dashboard、實時DAU、新激活使用者數、實時交易額等
♦ Dashboard類:北鬥(報表平台)、微信(公衆号)和雲圖(流量分析)等
♦ 實時DAU:包括主APP(Android/iPhone/iPad)、團APP、周邊快查、PC、M站
♦ 新激活使用者數:主APP
♦ 實時交易額:閃惠/團購交易額
以報表平台為例,下圖是一張APP UV的實時曲線圖,它以分鐘級别粒度展現了 實時的DAU資料和曲線。
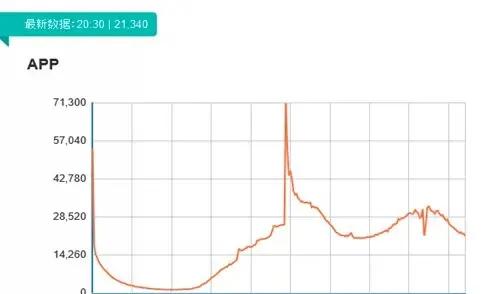
從圖中可以看見一個尖點,這個尖點就是當天push過後帶來的使用者,這樣可以看到實時的營運效率。
類别二:搜尋、推薦、安全等
以搜尋為例:使用者在點評的每一步有價值的操作(包括:搜尋、點選、浏覽、購買、收藏等),都将實時、智能地影響搜尋結果排序,進而顯著提升使用者搜尋體驗、搜尋轉化率。
某使用者 搜尋“ 火鍋 ”,當他 在搜尋結果頁 點選了“ 重慶高老九火鍋 ”後, 再次重新整理搜尋結果清單時,該商戶的排序就會提升到頂部 。
再結合其他的一些實時回報的個性化推薦政策,最終使團購的交易額有了明顯的增加,轉化率提升了2個多點。

實時計算在業界的使用場景
場景1:阿裡JStorm
♦ 雙11實時交易資料
場景2:360Storm
♦ 搶票軟體驗證碼自動識别:大家用360浏覽器在12306上買票的時候,驗證碼自動識别是在Storm上計算完成的。
♦ 網盤圖檔縮略圖生成:360網盤的縮略圖也是實時生成出來的,這樣可以節約大量的檔案數量和存儲空間。
♦ 實時入侵檢測
♦ 搜尋熱詞推薦
場景3:騰訊TDProcess
分布式K/V存儲引擎TDEngine和支援資料流計算的TDProcess,TDProcess是基于Storm的計算引擎,提供了通用的計算模型,如Sum、Count、PV/UV計算和TopK統計等。
場景4:京東Samza
整個業務主要應用訂單處理,實時分析統計出待定區域中訂單各個狀态的量:待定位、待派工、待揀貨、待發貨、待配送、待妥投等。
點評如何建構實時計算平台
點評的實時計算平台是一個端到端的方案,從下面的平台架構圖,可以看出整體架構是一個比較長的過程,包括了資料源、資料的傳輸通道、計算、存儲和對外服務等。
實時計算平台首先解決的問題是,資料怎麼擷取,如何拿到那些資料。現在做到了幾乎所有點評線上産生的資料都可以毫秒級拿到,封裝對應的資料輸入源Spout。
通過Blackhole支援日志類實時擷取,包括打點日志、業務Log、Nginx日志等。 整合Puma Client第一時間擷取資料庫資料變更。整合Swallow擷取應用消息。Blackhole是團隊開發的類Kafka系統,主要目标是批量從業務方拉取日志時做到資料的完整性和一緻性,然後也提供了實時的消費能力。Puma是以MySQL binlog為基礎開發的,這樣可以實時拿到資料庫的update、delete、insert操作。
Swallow是點評的MQ系統。通過整合各種傳輸通道,并且封裝相應的Spout,做業務開發的同學就完全不用關心資料怎樣可靠擷取,隻需要寫自己的業務邏輯就可以了。解決了資料和傳輸問題後,計算過程則在Storm中完成。
如果在Storm計算過程中或計算出結果後,需要與外部存儲系統互動,也提供了一個data-service服務 ,通過點評的RPC架構提供接口,使用者不用關心實際Redis/HBase這些系統的細節和部署情況, 以及這個資料到底是在Redis還是HBase中的,可以根據SLA來做自動切換;
同時計算的結果也是通過data-service服務,再回報到線上系統。就拿剛剛搜尋結果的例子,搜尋業務在使用者再次搜尋的時候會根據userId請求一次data-service,然後拿到這個使用者的最近浏覽記錄,并重新排序結果,傳回給使用者。
這樣的好處就是實時計算業務和線上其他業務完全解耦,實時計算這邊出現問題,不會導緻線上業務出現問題。
Storm基礎知識簡單介紹
Apache Storm( http://storm.apache.org/)是由Twitter開源的分布式實時計算系統。Storm可以非常容易、可靠地處理無限的資料流。對比Hadoop的批處理,Storm是個實時的、分布式以及具備高容錯的計算系統。Storm可以使用何程式設計語言進行開發。
Storm的叢集表面上看和Hadoop的叢集非常像,但是在Hadoop上面運作的是MapReduce的Job,而在Storm上面運作的是Topology。
Storm和Hadoop一個非常關鍵的差別是Hadoop的MapReduce Job最終會結束,而Storm的Topology會一直運作(除非顯式地殺掉)。
Storm基本概念:
Nimbus和Supervisor之間的通訊是依靠ZooKeeper來完成,并且Nimbus程序和Supervisor都是快速失敗(fail-fast)和無狀态的。可以用kill-9來殺死Nimbus和Supervisor程序,然後再重新開機它們,它們可以繼續工作。
在Storm中,Spout是Topology中産生源資料流的元件。通常Spout擷取從Kafka、MQ等的資料,然後調用nextTuple函數,發射資料出去供Bolt消費。
圖中的Spout就發射出去了兩條資料流。而Bolt是在Topology中接受Spout的資料,然後執行處理的元件。Bolt在接收到消息後會調用execute函數,使用者可以在其中執行自己想要的操作。
為什麼用Storm呢,因為Storm有它的優點:
易用性
隻要遵守Topology,Spout,Bolt的程式設計規範即可開發出一個擴充性極好的應用,像底層RPC,Worker之間備援,資料分流之類的操作,開發者完全不用考慮。
擴充性
當某一級處理單元速度不夠時,直接配置一下并發數,即可線性擴充性能。
健壯性
當Worker失效或機器出現故障時, 自動配置設定新的Worker替換失效Worker。
準确性
采用Acker機制,保證資料不丢失。采用事務機制,保證資料準确性。剛剛介紹了一些Storm的基礎概念和特性,再用一張比較完整的圖來回顧一下整個Storm的體系架構:
Storm送出一個作業的時候,是通過Thrift的Client執行相應的指令來完成。Nimbus針對該Topology建立本地的目錄,Nimbus中的排程器根據Topology的配置計算Task,并把Task配置設定到不同的Worker上,排程的結果寫入Zookeeper中。
Zookeeper上建立assignments節點,存儲Task和Supervisor中Worker的對應關系。在Zookeeper上建立workerbeats節點來監控Worker的心跳。Supervisor去Zookeeper上擷取配置設定的Tasks資訊,啟動一個或者多個Worker來執行。
每個Worker上運作多個Task,Task由Executor來具體執行。Worker根據Topology資訊初始化建立Task之間的連接配接,相同Worker内的Task通過DisrupterQueue來通信,不同Worker間預設采用Netty來通信,然後整個Topology就運作起來了。
如何保證業務運作可靠性
首先Storm自身有很多容錯機制,也加了很多監控資訊,友善業務同學監控自己的業務狀态。
在Storm上,遇到的一個很基本的問題就是,各個業務是運作的Worker會跑在同一台實體機上。曾經有位同學就在自己的Worker中起了200多個線程來處理json,結果就是這台機器的CPU都被他的Worker吃光了,其他的業務也跟着倒黴。
是以也使用CGroup做了每個Worker的資源隔離,主要限制了CPU和Memory的使用。相對而言JStorm在很多方面要完善一些,JStorm自己就帶資源隔離。對應監控來說,基本的主機次元的監控在ganglia上可以看見,比如現在叢集的運作狀況。下圖是現在此時的叢集的網絡和負載:
這些資訊并不能保證業務就OK,是以将Storm上的很多監控資訊和點評的開源監控系統Cat內建在了一起,從Cat上可以看見更多的業務運作狀态資訊。
比如在Cat中我可以看見整個叢集的TPS,現在已經從30多萬降下來了。 然後我可以設定若幹的報警規則, 如:連續N分鐘降低了50%可以報警。然後也監控了各個業務Topology的TPS、Spout輸入、Storm的可用Slot等的變化。
這個圖就是某個業務的TPS資訊, 如果TPS同比或者環比出現問題,也可以報警給業務方。
Storm使用經驗分享
1.使用元件的并行度代替線程池
Storm自身是一個分布式、多線程的架構,對每個Spout和Bolt,都可以設定其并發度;它也支援通過rebalance指令來動态調整并發度,把負載分攤到多個Worker上。
如果自己在元件内部采用線程池做一些計算密集型的任務,比如JSON解析,有可能使得某些元件的資源消耗特别高,其他元件又很低,導緻Worker之間資源消耗不均衡,這種情況在元件并行度比較低的時候更明顯。
比如某個Bolt設定了1個并行度,但在Bolt中又啟動了線程池,這樣導緻的一種後果就是,叢集中配置設定了這個Bolt的Worker程序可能會把機器的資源都給消耗光了,影響到其他Topology在這台機器上的任務的運作。如果真有計算密集型的任務,可以把元件的并發度設大,Worker的數量也相應提高,讓計算配置設定到多個節點上。
為了避免某個Topology的某些元件把整個機器的資源都消耗光的情況,除了不在元件内部啟動線程池來做計算以外,也可以通過CGroup控制每個Worker的資源使用量。
2.不要用DRPC批量處理大資料
RPC提供了應用程式和StormTopology之間互動的接口,可供其他應用直接調用,使用Storm的并發性來處理資料,然後将結果傳回給調用的用戶端。這種方式在資料量不大的情況下,通常不會有問題,而當需要處理批量大資料的時候,問題就比較明顯了。
(1)處理資料的Topology在逾時之前可能無法傳回計算的結果。
(2)批量處理資料,可能使得叢集的負載短暫偏高,處理完畢後,又降低回來,負載均衡性差。
批量處理大資料不是Storm設計的初衷,Storm考慮的 是時效性和批量之間的均衡,更多地看中前者。需要準實時地處理大資料量,可以考慮Spark Stream等批量架構。
3.不要在Spout中處理耗時的操作
Spout中nextTuple方法會發射資料流,在啟用Ack的情況下,fail方法和ack方法會被觸發。
需要明确一點,在Storm中Spout是單線程(JStorm的Spout分了3個線程,分别執行nextTuple方法、fail方法和ack方法)。如果nextTuple方法非常耗時,某個消息被成功執行完畢後,Acker會給Spout發送消息,Spout若無法及時消費,可能造成ACK消息逾時後被丢棄,然後Spout反而認為這個消息執行失敗了,造成邏輯錯誤。反之若fail方法或者ack方法的操作耗時較多,則會影響Spout發射資料的量,造成Topology吞吐量降低。
4.注意fieldsGrouping的資料均衡性
fieldsGrouping是根據一個或者多個Field對資料進行分組,不同的目标Task收到不同的資料,而同一個Task收到的資料會相同。
假設某個Bolt根據使用者ID對資料進行fieldsGrouping,如果某一些使用者的資料特别多,而另外一些使用者的資料又比較少,那麼就可能使得下一級處理Bolt收到的資料不均衡,整個處理的性能就會受制于某些資料量大的節點。可以加入更多的分組條件或者更換分組政策,使得資料具有均衡性。
5.優先使用localOrShuffleGrouping
localOrShuffleGrouping是指如果目标Bolt中的一個或者多個Task和目前産生資料的Task在同一個Worker程序裡面,那麼就走内部的線程間通信,将Tuple直接發給在目前Worker程序的目的Task。否則,同shuffleGrouping。
localOrShuffleGrouping的資料傳輸性能優于shuffleGrouping,因為在Worker内部傳輸,隻需要通過Disruptor隊列就可以完成,沒有網絡開銷和序列化開銷。是以在資料處理的複雜度不高,而網絡開銷和序列化開銷占主要地位的情況下,可以優先使用localOrShuffleGrouping來代替shuffleGrouping。
6.設定合理的MaxSpoutPending值
在啟用Ack的情況下,Spout中有個RotatingMap用來儲存Spout已經發送出去,但還沒有等到Ack結果的消息。RotatingMap的最大個數是有限制的,為p*num-tasks。其中p是topology.max.spout.pending值,也就是MaxSpoutPending(也可以由TopologyBuilder在setSpout通過setMaxSpoutPending方法來設定),num-tasks是Spout的Task數。如果不設定MaxSpoutPending的大小或者設定得太大,可能消耗掉過多的記憶體導緻記憶體溢出,設定太小則會影響Spout發射Tuple的速度。
7.設定合理的Worker數
Worker數越多,性能越好?先看一張Worker數量和吞吐量對比的曲線(來源于JStorm文檔:
https://github.com/alibaba/jstorm/tree/master/docs/ 0.9.4.1jstorm性能測試.docx)。
從圖可以看出,在12個Worker的情況下,吞吐量最大,整體性能最優。這是由于一方面,每新增加一個Worker程序,都會将一些原本線程間的記憶體通信變為程序間的網絡通信,這些程序間的網絡通信還需要進行序列化與反序列化操作,這些降低了吞吐率。
另一方面,每新增加一個Worker程序,都會額外地增加多個線程(Netty發送和接收線程、心跳線程、SystemBolt線程以及其他系統元件對應的線程等),這些線程切換消耗了不少CPU,sys系統CPU消耗占比增加,在CPU總使用率受限的情況下,降低了業務線程的使用效率。
8.平衡吞吐量和時效性
Storm的資料傳輸預設使用Netty。在資料傳輸性能方面,有如下的參數可以調整:
storm.messaging.netty.server_worker_threads和storm.messaging.netty.client_worker_threads分别為接收消息線程和發送消息線程的數量。
netty.transfer.batch.size是指每次 Netty Client向 Netty Server發送的資料的大小,如果需要發送的Tuple消息大于netty.transfer.batch.size,則Tuple消息會按照netty.transfer.batch.size進行切分,然後多次發送。
storm.messaging.netty.buffer_size為每次批量發送的Tuple序列化之後的TaskMessage消息的大storm.messaging.netty.flush.check.interval.ms表示當有TaskMessage需要發送的時候, Netty Client檢查可以發送資料的頻率。
降低storm.messaging.netty.flush.check.interval.ms的值,可以提高時效性。增加netty.transfer.batch.size和storm.messaging.netty.buffer_size的值,可以提升網絡傳輸的吐吞量,使得網絡的有效載荷提升(減少TCP包的數量,并且TCP包中的有效資料量增加),通常時效性就會降低一些。是以需要根據自身的業務情況,合理在吞吐量和時效性直接的平衡。
除了這些參數,怎麼找到Storm中性能的瓶頸,可以通過如下的一些途徑來進行:
在Storm的UI中,對每個Topology都提供了相應的統計資訊,其中有3個參數對性能來說參考意義比較明顯,包括Execute latency、Process latency和Capacity。
分别看一下這3個參數的含義和作用。
(1)Execute latency:消息的平均處理時間,機關為毫秒。
(2)Process latency:消息從收到到被ack掉所花的時間,機關為毫秒。如果沒有啟用Acker機制,那麼Process latency的值為0。
(3)Capacity:計算公式為Capacity = Bolt或者Executor調用execute方法處理的消息數量 * 消息平均執行時間 /時間區間。這個值越接近1,說明Bolt或者Executor基本一直在調用execute方法,是以并行度不夠,需要擴充這個元件的Executor數量。為了在Storm中達到高性能,在設計和開發Topology的時候,需要注意以下原則。
(1)子產品和子產品之間解耦,子產品之間的層次清晰,每個子產品可以獨立擴充,并且符合流水線的原則。
(2)無狀态設計,無鎖設計,水準擴充支援。
(3)為了達到高的吞吐量,延遲會加大;為了低延遲,吞吐量可能降低,需要在二者之間平衡。
(4)性能的瓶頸永遠在熱點,解決熱點問題。
(5)優化的前提是測量,而不是主觀臆測。收集相關資料,再動手,事半功倍。
關于計算架構的後續問題
目前Hadoop/Hive專注于離線分析業務,每天點評有1.6萬個離線分析任務。Storm專注于實時業務,實時每天會處理100億+條的資料。
在這兩個架構目前有很大的gap,一個是天級别,一個是秒級别,然後有大量的業務是準實時的,比如分鐘級别。是以會使用Spark來做中間的補充。
Spark Streaming + Spark SQL也能夠降低很大的開發難度。相對而言,目前Storm的學習和開發成本還是偏高。要做一個10萬+TPS的業務在Storm上穩定運作,需要對Storm了解比較深入才能做到,不然會發現有這樣或者那樣的問題。