現實情況中,很多機器學習訓練集會遇到樣本不均衡的情況,應對的方案也有很多種。
筆者把看到的一些内容進行簡單羅列,此處還想分享的是交叉驗證對不平衡資料訓練極為重要。
文章目錄
- 1 樣本不平衡的解決思路
- 1.2 将不平衡樣本當作離群點
- 1.2 欠采樣/過采樣
- **觀點:為什麼over-sampling在這種情況下工作得不好**
- **觀點:兩則的缺陷**
- **觀點:解決**
- **觀點:下采樣的情況下的三個解決方案**
- 1.3 訓練政策的優化
- 1.3.1 Focal_Loss
- 1.3.2 class_weight
- 1.4 不平衡評價名額:不要ROC,用Precision/Recall
- 1.5 使用相關模型 或調整預測機率
- 2 交叉驗證CV的有效性
1 樣本不平衡的解決思路
有好幾篇原創知乎内容都很贊,不做贅述,參考:
- 嚴重資料傾斜文本分類,比如正反比1:20~100,适合什麼model,查準一般要做到多少可以上線?
- 如何處理資料中的「類别不平衡」?
1.2 将不平衡樣本當作離群點
具體問題具體分析,依據不平衡的比例,如果一些問題是極其不平衡的1:100+,該任務就可以當作尋找離群點。一分類就是左圖中一大堆點的區域,當有超過這一堆的就會分到另外一類。
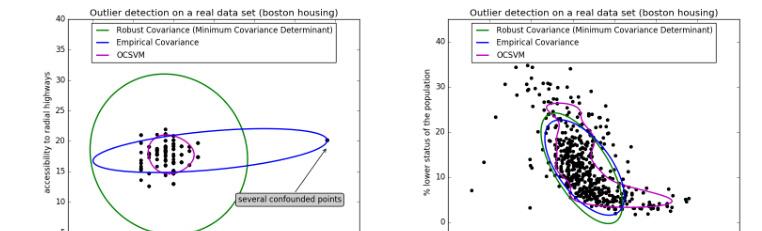
正常的可以使用一些聚類 或 OneClassSVM(無監督︱異常、離群點檢測 一分類——OneClassSVM)
正常的可參考文獻 :
- 微調:資料挖掘中常見的『異常檢測』算法有哪些?
- 「異常檢測」開源工具庫推薦
1.2 欠采樣/過采樣
這個方式應該是最多被提及的,對于樣本比較多的分類進行欠采樣,樣本比較少的進行過采樣。
過采樣,就相當于文本增強,常見的文本增強有:
- 随機打亂句子
- 加入噪聲:在正例中加入一些噪聲詞,或随機剔除一些詞
- 裁剪掉長文本的某一句(或開頭句,或結尾句)
- 複制(最常見)
- paraphrasing,用序列到序列的方式去生成,在問答系統有一個領域叫做問題複述,根據原始問題生成格式更好的問題,相當于修正不規範的問題,将新問題代替舊問題輸入到問答系統中,我覺得的也算是一種資料增強方法了吧(文本多分類踩過的坑)。
- TTA ,kaggle比賽轉用,中文->英文->中文
英語 - 德語 - 英語
EN -> DE -> EN
EN -> FR -> EN
EN -> ES -> EN 複制
欠采樣:删除掉一些文本(一些不重要文本進行剔除)
觀點:為什麼over-sampling在這種情況下工作得不好
以smote為例,我們希望從樣本及其最近鄰的點的連線上選一個随機點将其作為新的樣本來合成。但是文本資料(無論是用n-gram feature還是distributed representation)都是很高次元的。在高維空間的一個事實就是資料傾向于接近互相正交,故而兩兩不相近,是以采用NN的思想來做up-sampling,效果是不會太好的。
正樣本的資料,是否能夠公正地代表正樣本的分布?是否有明顯的屬于正樣本但是沒有包括進來的例子?很大可能,需要補資料。如果真的是缺乏正樣本資料的話,用什麼辦法都很難了。
觀點:兩則的缺陷
過拟合的缺陷:過拟合風險
欠拟合的缺陷:缺失樣本,偏差較大
觀點:解決
過采樣(或SMOTE)+強正則模型(如XGBoost)可能比較适合不平衡的資料。
觀點:下采樣的情況下的三個解決方案
(幹貨|如何解決機器學習中資料不平衡問題)
因為下采樣會丢失資訊,如何減少資訊的損失呢?
- 第一種方法叫做EasyEnsemble,利用模型融合的方法(Ensemble):多次下采樣(放回采樣,這樣産生的訓練集才互相獨立)産生多個不同的訓練集,進而訓練多個不同的分類器,通過組合多個分類器的結果得到最終的結果。
- 第二種方法叫做BalanceCascade,利用增量訓練的思想(Boosting):先通過一次下采樣産生訓練集,訓練一個分類器,對于那些分類正确的大衆樣本不放回,然後對這個更小的大衆樣本下采樣産生訓練集,訓練第二個分類器,以此類推,最終組合所有分類器的結果得到最終結果。
- 第三種方法是利用KNN試圖挑選那些最具代表性的大衆樣本,叫做NearMiss,這類方法計算量很大,感興趣的可以參考“Learning from Imbalanced Data”這篇綜述的3.2.1節。
1.3 訓練政策的優化
在模型訓練的時候有一些政策,比較常見的是sklearn的class_weight:
1.3.1 Focal_Loss
舉一個keras的例子,focal_loss:
# new focal loss
from keras import backend as K
def new_focal_loss(gamma=2., alpha=.25):
def focal_loss_fixed(y_true, y_pred):
pt_1 = tf.where(tf.equal(y_true, 1), y_pred, tf.ones_like(y_pred))
pt_0 = tf.where(tf.equal(y_true, 0), y_pred, tf.zeros_like(y_pred))
return -K.sum(alpha * K.pow(1. - pt_1, gamma) * K.log(pt_1))-K.sum((1-alpha) * K.pow( pt_0, gamma) * K.log(1. - pt_0))
return focal_loss_fixed 複制
1.3.2 class_weight
在随機選擇mini batch的時候,每個batch中正負樣本配平。示例:
from sklearn.utils import class_weight
imbalance_label = class_weight.compute_class_weight('balanced',np.unique(y_train), y_train) 複制
1.4 不平衡評價名額:不要ROC,用Precision/Recall
Credit Card Fraud: Handling highly imbalance classes and why Receiver Operating Characteristics Curve (ROC Curve) should not be used, and Precision/Recall curve should be preferred in highly imbalanced situations
來看一下這篇kaggle文獻的觀點,樣本不均衡的情況下不适用ROC,而應該考量的是Precision/Recall這兩條曲線。

作者的表述如下,筆者就不翻譯啦:
For a PR curve, a good classifer aims for the upper right corner of the chart but upper left for the ROC curve.
While PR and ROC curves use the same data, i.e. the real class labels and predicted probability for the class lables, you can see that the two charts tell very different stories, with some weights seem to perform better in ROC than in the PR curve.
While the blue, w=1, line performed poorly in both charts, the black, w=10000, line performed “well” in the ROC but poorly in the PR curve. This is due to the high class imbalance in our data. ROC curve is not a good visual illustration for highly imbalanced data, because the False Positive Rate ( False Positives / Total Real Negatives ) does not drop drastically when the Total Real Negatives is huge.
Whereas Precision ( True Positives / (True Positives + False Positives) ) is highly sensitive to False Positives and is not impacted by a large total real negative denominator.
The biggest difference among the models are at around 0.8 recall rate. Seems like a lower weight, i.e. 5 and 10, out performs other weights significantly at 0.8 recall. This means that with those specific weights, our model can detect frauds fairly well (catching 80% of fraud) while not annoying a bunch of customers with false positives with an equally high precision of 80%.
1.5 使用相關模型 或調整預測機率
不對資料進行過采樣和欠采樣,但使用現有的內建學習模型,如随機森林,輸出随機森林的預測機率,調整門檻值得到最終結果
2 交叉驗證CV的有效性
但是如果你處于比賽階段,如果是分類單一還可以,如果分類較多比較複雜的分類體系的話,過采與欠采就非常困難。欠采影響分布之後,會對名額造成非常明顯的打擊,不能輕易動大簇類别。不過,小類别過采樣,這個還是可以接受的,直接複制的效果也很明顯。一般情況下,為了高效訓練以及模型融合,一般情況下對不平衡不會做太大的采樣操作。
對于分類體系較為複雜的文本分類任務,交叉驗證的結果受不平衡資料,效果也有很大差異。正因為很大差異,CV對于不平衡來說是一種非常有效的訓練手段。
以筆者看到的kaggle Toxic Comment Classification中該篇文獻:Things you need to be aware of before stacking
可以看到不同分類,單個模型的OOF 預測結果差異很大,對于Full OOF,一些fold的效果差異比較大。
有差異,有效的融合就顯得很有必要,單純的bagging在一起并不合理。