來源:http://t.cn/RO6NTBX
1. 前言
對于一張網頁,我們往往希望它是結構良好,内容清晰的,這樣搜尋引擎才能準确地認知它。
而反過來,又有一些情景,我們不希望内容能被輕易擷取,比方說電商網站的交易額,教育網站的題目等。因為這些内容,往往是一個産品的生命線,必須做到有效地保護。這就是爬蟲與反爬蟲這一話題的由來。
2. 常見反爬蟲政策
但是世界上沒有一個網站,能做到完美地反爬蟲。
如果頁面希望能在使用者面前正常展示,同時又不給爬蟲機會,就必須要做到識别真人與機器人。是以工程師們做了各種嘗試,這些政策大多采用于後端,也是目前比較正常單有效的手段,比如:
- User-Agent + Referer檢測
- 賬号及Cookie驗證
- 驗證碼
- IP限制頻次
而爬蟲是可以無限逼近于真人的,比如:
- chrome headless或phantomjs來模拟浏覽器環境
- tesseract識别驗證碼
- 代理IP淘寶就能買到
是以我們說,100%的反爬蟲政策?不存在的。
更多的是體力活,是個難易程度的問題。
不過作為前端工程師,我們可以增加一下遊戲難度,設計出一些很(sang)有(xin)意(bing)思(kuang)的反爬蟲政策。
3. 前端與反爬蟲
3.1 font-face拼湊式
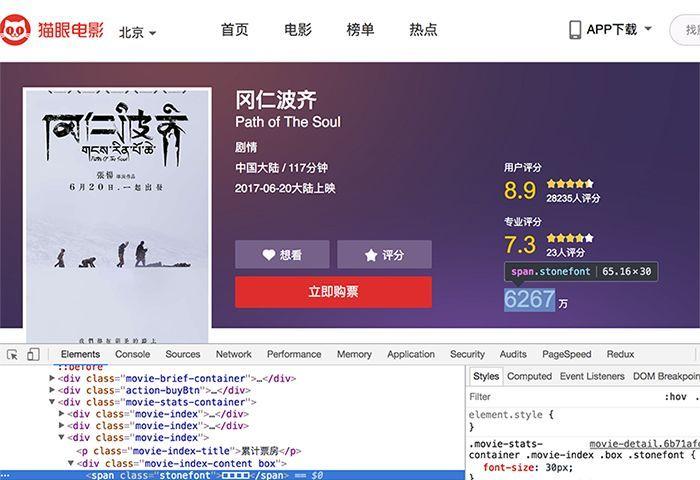
例子:貓眼電影
貓眼電影裡,對于票房資料,展示的并不是純粹的數字。 頁面使用了font-face定義了字元集,并通過unicode去映射展示。也就是說,除去圖像識别,必須同時爬取字元集,才能識别出數字。
img
并且,每次重新整理頁面,字元集的url都是有變化的,無疑更大難度地增加了爬取成本。

img
3.2 background拼湊式
例子:美團
與font的政策類似,美團裡用到的是background拼湊。數字其實是圖檔,根據不同的background偏移,顯示出不同的字元。
img
并且不同頁面,圖檔的字元排序也是有差別的。不過理論上隻需生成0-9與小數點,為何有重複字元就不是很懂。
頁面A:
img
頁面B:
img
3.3 字元穿插式
例子:微信公衆号文章
某些微信公衆号的文章裡,穿插了各種迷之字元,并且通過樣式把這些字元隐藏掉。
這種方式雖然令人震驚…但其實沒有太大的識别與過濾難度,甚至可以做得更好,不過也算是一種腦洞吧。
img
對了,我的手機流量可以找誰報帳嗎?
3.4 僞元素隐藏式
例子:汽車之家
汽車之家裡,把關鍵的廠商資訊,做到了僞元素的content裡。
這也是一種思路:爬取網頁,必須得解析css,需要拿到僞元素的content,這就提升了爬蟲的難度。
img
3.5 元素定位覆寫式
例子:去哪兒
還有熱愛數學的去哪兒,對于一個4位數字的機票價格,先用四個
i
标簽渲染,再用兩個
b
标簽去絕對定位偏移量,覆寫故意展示錯誤的
i
标簽,最後在視覺上形成正确的價格…
img
這說明爬蟲會解析css還不行,還得會做數學題。
3.6 iframe異步加載式
例子:網易雲音樂
網易雲音樂頁面一打開,html源碼裡幾乎隻有一個
iframe
,并且它的src是空白的:
about:blank
。接着js開始運作,把整個頁面的架構異步塞到了iframe裡面…
img
不過這個方式帶來的難度并不大,隻是在異步與iframe處理上繞了個彎(或者有其他原因,不完全是基于反爬蟲考慮),無論你是用selenium還是phantom,都有API可以拿到iframe裡面的content資訊。
3.7 字元分割式
例子:全網代理IP
在一些展示代理IP資訊的頁面,對于IP的保護也是大費周折。
img
他們會先把IP的數字與符号分割成dom節點,再在中間插入迷惑人的數字,如果爬蟲不知道這個政策,還會以為自己成功拿到了數值;不過如果爬蟲注意到,就很好解決了。
3.8 字元集替換式
例子:去哪兒移動側
同樣會欺騙爬蟲的還有去哪兒的移動版。
img
html裡明明寫的3211,視覺上展示的卻是1233。原來他們重新定義了字元集,3與1的順序剛好調換得來的結果…