歡迎通路我的GitHub
這裡分類和彙總了欣宸的全部原創(含配套源碼):https://github.com/zq2599/blog_demos
關于ProcessFunction狀态的疑惑
學習Flink的ProcessFunction過程中,官方文檔中涉及狀态處理的時候,不止一次提到隻适用于keyed stream的元素,如下圖紅框所示:
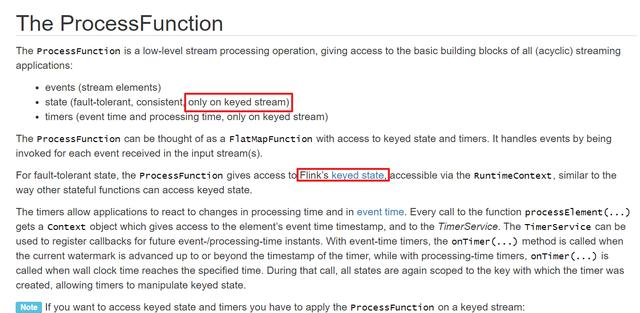
之前寫過一些flink應用,keyed stream常用但不是必須用的,是以産生了疑問:
- 為何隻有==keyed stream==的元素能讀寫狀态?
- 每個key對應的狀态是如何操作的?
Flink的"狀态"
先去回顧Flink"狀态"的知識點:
- 官方文檔說就兩種狀态:keyed state和operator state:

Flink處理函數實戰之一:深入了解ProcessFunction的狀态(Flink-1.10) - 如上圖,keyed stream的元素是具有key的特征,與ProcessFunction的操作狀态時要求比對,其他steam的元素由于沒有key的特征,是以也就沒有==狀态==一說了;
- 另一種狀态是==Operator State==,如下圖,這是和多并行度計算時的算子執行個體綁定的,例如目前算子消費kafka的某個分區的最新offset,而ProcessFunction是用來處理stream元素的,不會涉及到Operator State:
Flink處理函數實戰之一:深入了解ProcessFunction的狀态(Flink-1.10)
官方demo
為了學習ProcessFunction就去看官方demo,位址是:https://ci.apache.org/projects/flink/flink-docs-release-1.10/dev/stream/operators/process_function.html ,簡單說說這個demo的功能:
- 資料源在不間斷的産生單詞,每個單詞對應一個Tuple2<String,String>的執行個體;
- 資料源被==keyBy==方法轉成KeyedStream,key是Tuple2執行個體的f0字段;
- 一個KeyedProcessFunction的子類==CountWithTimeoutFunction==,被用來處理KeyedStream的每個元素,處理的邏輯:為每個key維護一個狀态,狀态的内容是這個key的出現次數和最後一次出現時間;
- 如果那個key連續一分鐘沒有出現,KeyedProcessFunction就向下遊發送這個元素;
先反思為何會有上述疑惑
- 上述疑惑産生的原因,應該是受到平時使用HashMap的影響,HashMap擷取值就是在調用get方法時指定key,設定值也是在put時指定key,是以看到state.value()方法沒有用key做入參就不習慣了
- 要消除這種不适應,要做的第一件事就是提醒自己:processElement是在架構内運作的,很多資料在之前已經由架構準備好了;
- 接下來要做的,就是把==架構準備資料==的邏輯看一遍,除了弄明白自己的問題,由于ProcessFunction屬于最低階抽象(如下圖的最下方位置),看懂了這些,其實也是在了解DataStream/DataSet API的設計思路:
Flink處理函數實戰之一:深入了解ProcessFunction的狀态(Flink-1.10)
跟蹤源碼
- 如下圖,讓我們從一個斷點的堆棧開始吧,這是在執行上面demo中==的processElement==方法之前的一個斷點,可見根源是個線程的run方法,也就是KeyedProcessFunction對應的算子執行任務的線程:
Flink處理函數實戰之一:深入了解ProcessFunction的狀态(Flink-1.10) - 上面的堆棧不必每一層都細看,隻關注重要的部分,下圖這段很重要:StreamTask.run方法中,有個無限循環(猜測是每次執行processInput方法都處理KeyedStream的一個元素):
Flink處理函數實戰之一:深入了解ProcessFunction的狀态(Flink-1.10) - 如下圖,StreamOneInputProcessor.processInput方法取出KeyedStream的一個元素,調用processElement方法,并将此元素作為入參,再結合上一幅圖可以看出:在編寫==KeyedProcessFunction子類的時候,KeyedStream的每個元素都會作為入參,在調用你重寫的processElement方法時傳進去;==這一點,在做ProcessFunction和KeyedProcessFunction開發時都是要格外注意的:
Flink處理函數實戰之一:深入了解ProcessFunction的狀态(Flink-1.10) - 接下來到了最關鍵的地方了,下圖紅框中的streamOperator.setKeyContextElement1(record)會解答我前面的疑惑,一定要進去看個清楚,(後面的黃線上的代碼,您應該猜到了,裡面其實就是調用demo中的processElement方法)
Flink處理函數實戰之一:深入了解ProcessFunction的狀态(Flink-1.10) - 下圖中,AbstractStreamOperator.setKeyContextElement給出了答案:==對于KeyedStream的每個元素,都會在這裡算出key,再調用setCurrentKey儲存這個key==:
Flink處理函數實戰之一:深入了解ProcessFunction的狀态(Flink-1.10) - 展開==setCurrentKey==,如下圖,發現key的儲存和目前狀态的存儲政策(StateBackend)有關,我這裡是預設政策==HeapKeyedStateBackend==:
Flink處理函數實戰之一:深入了解ProcessFunction的狀态(Flink-1.10) - 最終,根據目前元素得到的key會在StateBackend的keyContext對象中找地方儲存,StateBackend的具體實作和Flink設定有關,我這裡是儲存到了InternalKeyContextImpl執行個體的currentKey變量中:
Flink處理函數實戰之一:深入了解ProcessFunction的狀态(Flink-1.10) - 代碼讀到這裡,對我前面的疑惑,您應該能推測出答案了:state.value()裡面會通過StateBackend的keyContext取出剛才儲存的key,接下來就能像HashMap那樣根據key查出該key的狀态了,接下來是愉快的印證我們推測的過程;
- 在==state.value()==代碼位置打斷點一次看個明白,如下圖,果然,state裡面有StateBackend的keyContext對象的引用,通路剛才儲存的key就不成問題了:
Flink處理函數實戰之一:深入了解ProcessFunction的狀态(Flink-1.10) - 展開state.value()方法如下,簡單明了,直接拿keyContext儲存的key作為入參去取對應的狀态:
Flink處理函數實戰之一:深入了解ProcessFunction的狀态(Flink-1.10) - 再展開上面的get方法,可見最終是從stateMap中取得的,而這個stateMap的具體實作是CopyOnWriteStateMap類型的執行個體:
Flink處理函數實戰之一:深入了解ProcessFunction的狀态(Flink-1.10) - 代碼讀到這裡,隻剩最後一處需要印證了:更新狀态的state.update(current)方法,應該也是以StateBackend的keyContext中的key作為自己的key,再将入參的current作為value,更新到stateMap中,來吧,一起印證這個推測;
- 展開方法,看到的是stateTable.put方法(前面剛看過stateTable的get方法,穩了):
Flink處理函數實戰之一:深入了解ProcessFunction的狀态(Flink-1.10) - stateTable.put方法裡面和前面的get方法一樣,直接拿keyContext儲存的key作為自己的key:
Flink處理函數實戰之一:深入了解ProcessFunction的狀态(Flink-1.10) - 最終是調用了stateMap.put方法,将資料儲存在CopyOnWriteStateMap執行個體中:
Flink處理函數實戰之一:深入了解ProcessFunction的狀态(Flink-1.10) - 得益于Flink代碼自身規範、清晰的設計和實作,再加上IDEA強大的debug功能,整個閱讀和分析過程十分順利,這其中的收獲會逐漸在今後深入學習DataStreamAPI的過程中見效;