雖然plink2.0已經存在好久了,但是一直用的都是plink1.9,因為文法熟悉。更主要是plink2.0文法變動太大,害怕步子邁得太大了……
今天看一下plink2.0的讀入和輸出資料常用參數,
plink2.0用是不會用的,2022年都不會用!!!但是碰到bgen,pgen資料進行轉化為bed,bim,fam檔案,然後用plink1.9使用的想法還是有的,而且很大!!!
本篇目的:使用plink2.0軟體将下面格式随便輸入、輸出
- plink1.9的ped和map資料,不如:a.ped, a.map
- plink1.9的bed和bim和fam資料,比如:a.bim, a.bed, a.fam
- plink2.0的bgen和sample資料,比如:a.bgen, a.sample
- plink2.0的pgen和bim和fam資料,比如a.pgen,a.fam,a.bim
- vcf資料,比如a.vcf
1,plink2.0的提升
plink2.0主要是從以下幾個方面,相對于plink1.9有較大的提升:
- 1,保留參考等位基因的資訊,比如vcf格式的資料,不要添加參數 --keep-allele-order。這樣vcf變為plink,plink變為vcf就可以不用指定ref和alt了,切換無障礙!
- 2,新的.pgen檔案,結合SNPack-style的壓縮,可以節約80%的檔案大小。比如1000個Genomes,比壓縮的gzip檔案小70%,且不丢失任何資訊。壓縮檔案空間更小,速度更快。
- 3,舊版的二進制檔案(bed,bim和fam)檔案,plink2.0依舊支援,輸出檔案包括兩種:–make-bpgen 和 --make-bpfile檔案。可以支援plink1.9的檔案格式,無論是map和ped資料,還是bed,bim和fam格式。
- 4,分析子產品,進行了優化。标準的logistic回歸分析失敗産生NA或者無意義的結果,–glm比plink1.9的–linear速度提升1000倍。尤其是填充的劑量效應的基因型值(比如0.2,1.8這樣的非整數型資料)。PCA分析彙總,增加了參數
PCA approx
2,plink2.0 安裝
plink2.0 網站:https://www.cog-genomics.org/plink/2.0/
二進制檔案,直接執行,支援:
- Intel
- AMD
- 蘋果M1
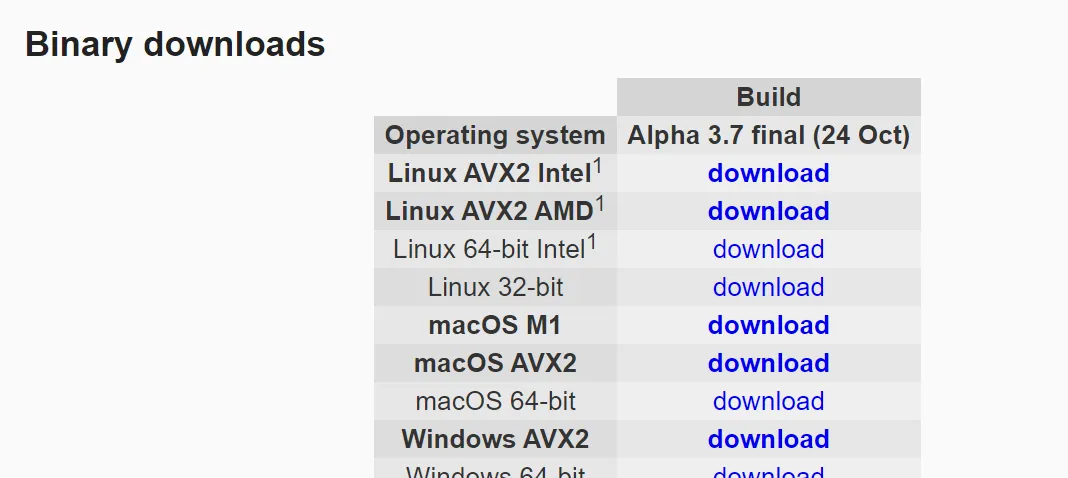
建議:plink1.9簡寫為plink,plink2.0 簡寫為plink2
3,plink幫助文檔
可以通過官網查詢具體參數:https://www.cog-genomics.org/plink/2.0/
也可以在指令行中調出幫助文檔:
比如直接鍵入plink2,出現基礎參數:
$ plink2
PLINK v2.00a3.7LM AVX2 Intel (24 Oct 2022) www.cog-genomics.org/plink/2.0/
(C) 2005-2022 Shaun Purcell, Christopher Chang GNU General Public License v3
plink2 <input flag(s)...> [command flag(s)...] [other flag(s)...]
plink2 --help [flag name(s)...]
Commands include --rm-dup list, --make-bpgen, --export, --freq, --geno-counts,
--sample-counts, --missing, --hardy, --het, --fst, --indep-pairwise, --ld,
--sample-diff, --make-king, --king-cutoff, --pmerge, --pgen-diff,
--write-samples, --write-snplist, --make-grm-list, --pca, --glm, --adjust-file,
--score, --variant-score, --genotyping-rate, --pgen-info, --validate, and
--zst-decompress.
"plink2 --help | more" describes all functions. 想檢視一下–export的用法,可以看到主要功能:
- A,是0-1-2編碼
- ped,是map和ped格式
- vcf,是vcf格式
- bgen-1.x,包括1.1, 1.2, 1.3,都是bgen格式
$ plink2 --export --help
PLINK v2.00a3.7LM AVX2 Intel (24 Oct 2022) www.cog-genomics.org/plink/2.0/
(C) 2005-2022 Shaun Purcell, Christopher Chang GNU General Public License v3
--help present, ignoring other flags.
--export <output format(s)...> [{01 | 12}] ['bgz'] ['id-delim='<char>]
['id-paste='<column set descriptor>] ['include-alt']
['omit-nonmale-y'] ['spaces'] ['vcf-dosage='<field>] ['ref-first']
['bits='<#>] ['sample-v2']
Create a new fileset with all filters applied. The following output
formats are supported:
(actually, only A, AD, Av, bcf, bgen-1.x, haps, hapslegend, ind-major-bed,
oxford, ped, tped, and vcf are implemented for now)
* '23': 23andMe 4-column format. This can only be used on a single
sample's data (--keep may be handy), and does not support
multicharacter allele codes.
* 'A': Sample-major additive (0/1/2) coding, suitable for loading from R.
If you need uncounted alleles to be named in the header line, add
the 'include-alt' modifier.
* 'AD': Sample-major additive (0/1/2) + dominant (het=1/hom=0) coding.
Also supports 'include-alt'.
* 'Av': Variant-major 0/1/2.
* 'beagle': Unphased per-autosome .dat and .map files, readable by early
BEAGLE versions.
* 'beagle-nomap': Single .beagle.dat file.
* 'bgen-1.x': Oxford-format .bgen + .sample. For v1.2/v1.3, sample
identifiers are stored in the .bgen (with id-delim and
id-paste settings applied), and default precision is 16-bit
(use the 'bits' modifier to reduce this).
* 'bimbam': Regular BIMBAM format.
* 'bimbam-1chr': BIMBAM format, with a two-column .pos.txt file. Does not
support multiple chromosomes.
* 'fastphase': Per-chromosome fastPHASE files, with
.chr-<chr #>.phase.inp filename extensions.
* 'fastphase-1chr': Single .phase.inp file. Does not support
multiple chromosomes.
* 'haps', 'hapslegend': Oxford-format .haps + .sample[ + .legend]. All
data must be biallelic and phased. When the 'bgz'
modifier is present, the .haps file is
block-gzipped.
* 'HV': Per-chromosome Haploview files, with .chr-<chr #>{.ped,.info}
filename extensions.
* 'HV-1chr': Single Haploview .ped + .info file pair. Does not support
multiple chromosomes.
* 'ind-major-bed': PLINK 1 sample-major .bed (+ .bim + .fam).
* 'lgen': PLINK 1 long-format (.lgen + .fam + .map), loadable with --lfile.
* 'lgen-ref': .lgen + .fam + .map + .ref, loadable with --lfile +
--reference.
* 'list': Single genotype-based list, up to 4 lines per variant. To omit
nonmale genotypes on the Y chromosome, add the 'omit-nonmale-y'
modifier.
* 'rlist': .rlist + .fam + .map fileset, where the .rlist file is a
genotype-based list which omits the most common genotype for
each variant. Also supports 'omit-nonmale-y'.
* 'oxford', 'oxford-v2': Oxford-format .gen + .sample. When the 'bgz'
modifier is present, the .gen file is
block-gzipped. 'oxford' requests the original
.gen file format with 5 leading columns
(understood by older PLINK builds); 'oxford-v2'
requests the current 6-leading-column flavor.
* 'ped', 'compound-genotypes': PLINK 1 sample-major (.ped + .map),
loadable with --pedmap.
* 'structure': Structure-format.
* 'tped': PLINK 1 variant-major (.tped + .tfam), loadable with --tfile.
* 'vcf', : VCF (default version 4.3). If PAR1 and PAR2 are present,
'vcf-4.2', they are automatically merged with chrX, with proper
'bcf', handling of chromosome codes and male ploidy.
'bcf-4.2' When the 'bgz' modifier is present, the VCF file is
block-gzipped. (This always happens with BCF output.)
The 'id-paste' modifier controls which .psam columns are
used to construct sample IDs (choices are maybefid, fid,
iid, maybesid, and sid; default is maybefid,iid,maybesid),
while the 'id-delim' modifier sets the character between the
ID pieces (default '_').
Genotypes are always exported. If you want to export a
sites-only VCF instead, see --make-pgen/--make-just-pvar's
'vcfheader' column set.
Dosages are not exported unless the 'vcf-dosage=' modifier
is present. The following six dosage export modes are
supported:
'GP': genotype posterior probabilities (v4.3 only).
'DS': Minimac3-style dosages, omitted for hardcalls.
'DS-force': Minimac3-style dosages, never omit.
'DS-only': Same as DS-force, except GT field is omitted.
'HDS': Minimac3-style phased dosages, omitted for hardcalls
and unphased calls. Also includes 'DS' output.
'HDS-force': Always report DS and HDS.
In addition,
* The '12' modifier causes alt1 alleles to be coded as '1' and ref alleles
to be coded as '2', while '01' maps alt1 -> 0 and ref -> 1.
* The 'spaces' modifier makes the output space-delimited instead of
tab-delimited, whenever both are permitted.
* For biallelic formats where it's unspecified whether the reference/major
allele should appear first or second, --export defaults to second for
compatibility with PLINK 1.9. Use 'ref-first' to change this.
(Note that this doesn't apply to the 'A', 'AD', and 'Av' formats; use
--export-allele to control which alleles are counted there.)
* 'sample-v2' exports .sample files according to the QCTOOLv2 rather than
the original specification. Only one ID column is exported ('id-paste'
and 'id-delim' settings apply), parental IDs are exported if present, and
category names are preserved rather than converted to positive integers.
--export-allele <file> : With --export A/AD/Av, count alleles named in the
file, instead of REF alleles. 4. plink2.0 筆記
4.1 讀取plink的ped和map資料
plink2.0,沒有–file這個參數了,變為了:
--pedmap
,也可以分開寫,比如 --ped --map分别接ped和map資料。
plink2 --ped yuanshi.ped --map yuanshi.map 或者寫為:
plink2 --pedmap yuanshi 預設輸出檔案:
plink2.log plink2.pgen plink2.psam plink2.pvar - plink2.log,log日志,不用理會
- plink2.pgen,二進制檔案,類似plink1.9的bim檔案
- plink2.psam,個體和性别資訊
- plink2.pvar,snp的資訊,包括染色體、實體位置、名稱、ref和alt
4.2 讀取plink的bed,bim和fam資料
plink1.9的二進制資料是bed,bim和fam資料,plink2.0通過–bfile指定。
比如讀取plink1.9的二進制檔案,輸出bgen格式:
plink2 --bfile a1 --export bgen-1.1 --out t1 日志:
$ plink2 --bfile a1 --export bgen-1.1 --out t1
PLINK v2.00a3.7LM AVX2 Intel (24 Oct 2022) www.cog-genomics.org/plink/2.0/
(C) 2005-2022 Shaun Purcell, Christopher Chang GNU General Public License v3
Logging to t1.log.
Options in effect:
--bfile a1
--export bgen-1.1
--out t1
Start time: Thu Dec 1 18:59:10 2022
1031523 MiB RAM detected; reserving 515761 MiB for main workspace.
Using up to 96 threads (change this with --threads).
86 samples (0 females, 0 males, 86 ambiguous; 86 founders) loaded from a1.fam.
50904 variants loaded from a1.bim.
Note: No phenotype data present.
Writing t1.bgen ... done.
Writing t1.sample ... done. 4.3 讀取bgen和sample格式
導出ped和map的格式:
plink2 --bgen t1.bgen 'ref-last' --sample t1.sample --export ped --out x1 注意:bgen和sample是一對資料,讀取時,要分開指定,–bgen, --sample,同時要指定‘ref-last’,即後面的是ref,前面的是alt,也可以修改。
4.4 讀取vcf資料
導出ped和map資料
讀取vcf,導出ped和map資料:需要定義
--export ped
plink2 --vcf x2.vcf --export ped --out y1 導出bed和bim和fam資料
讀取vcf資料,導出bim,bed和fam資料:需要定義
--make-bed
plink2 --vcf x2.vcf --make-bed --out y2 導出bgen資料
plink2 --vcf x2.vcf --export bgen-1.1 --out y3 ![Babylon.js 第21章 材質映射到網格+貼花[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)