在自己沒有管理多台高負荷的ubuntu顯示卡伺服器之前,我是萬萬想不到linux伺服器居然也是如此容易當機的。
什麼每個版本的TensorFlow調用顯示卡驅動時和核心不相容,什麼系統自動更新導緻的顯示卡驅動和核心不相容,什麼顯示卡驅動沒有設定為persistent模式造成驅動程序啟動逾時,總之,管的時間長了這個GPU伺服器啥樣原因造成當機的都有,真是要人不得不感慨。
今天要記錄的一次伺服器當機的原因是顯示卡高負荷所引起的。
------------------------------------------
具體排查過程:
伺服器當機後顯示屏上的報錯資訊:
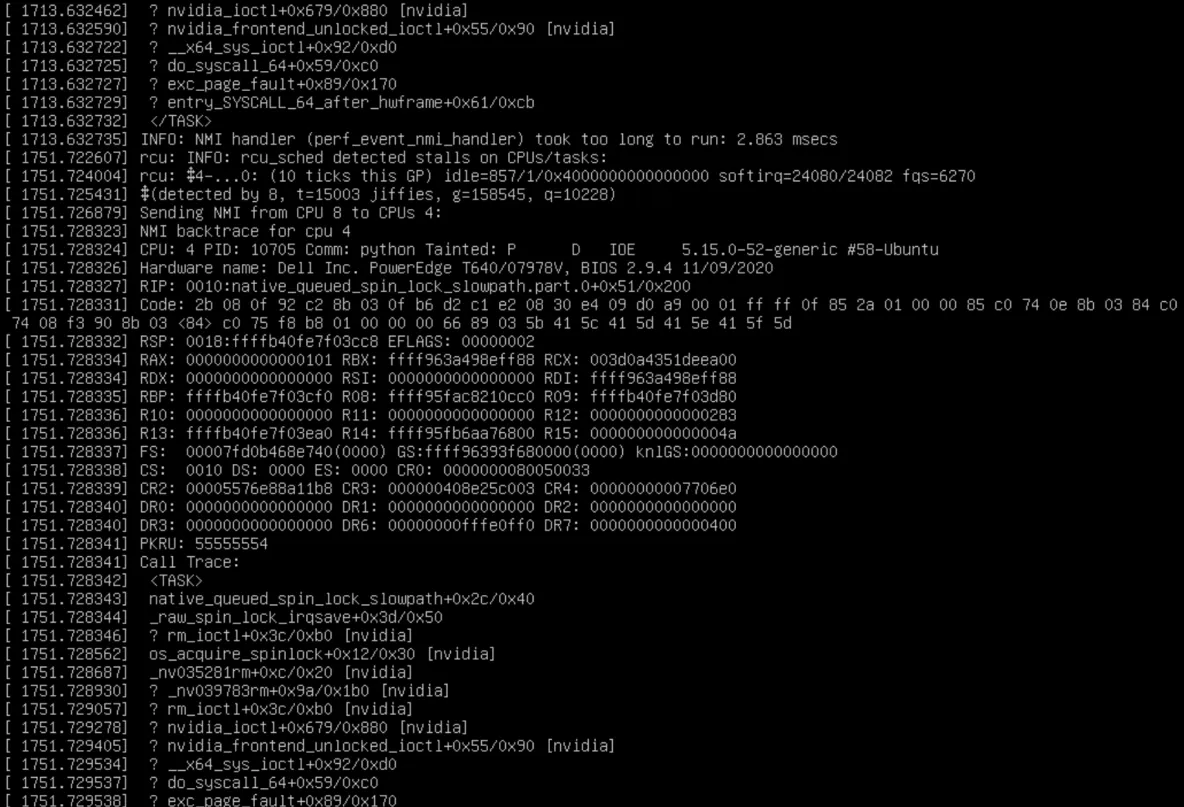
根據這個資訊,我們知道伺服器當機的同時報出大量的INFO:nmi handler took too long
NMI不可屏蔽中斷的資訊頻頻報出,說明此時存在某個CPU程序在調用核心函數時已經逾時,由此造成系統核心soft locked,此時整個伺服器已經進入slow down的狀态了,這也是伺服器當機的一種表現。
在伺服器當機,NMI資訊頻發的同時,我們可以看到kernel記錄了Call Trace資訊,也就是當機時報錯的核心函數的函數調用資訊,該資訊可以作為調試資訊和檢查當機原因之用。
根據Call Trace資訊,我們可以知道造成伺服器系統當機的具體程序的報錯資訊,是以可以知道native_queued_spin_lock_slowpath是造成這次當機最初的那個點的入口。
這個Call Trace資訊需要從下往上看:
entry_SYSCALL_64_after_hwfram :準備進入系統調用階段
exc_page_fault :通路缺頁
do_syscall_64 : 進入系統調用階段
x64_sys_ioctl : 核心對裝置驅動程式中的I/O通道進行調用
nvidia_frontend_unlocked_ioctl : 核心空間下調用nvidia驅動的I/O通道函數
可以看到報錯的資訊主要是nvidia驅動在進行I/O操作時候引起的。
===============================================
由于我們的這個Dell伺服器是可以通過遠端管理的,我們通過遠端管理界面看看廠家給的監控資訊:

可以看到官方廠家給出的報錯資訊為:
A bus fatal error was detected on a component at slot 6.
A fatal error was detected on a component at bus 216 device 0 function 0.
根據這個資訊,我們檢視PCIE上的裝置資訊
可以看到6号槽的裝置資訊為:
根據裝置的位址資訊,我們檢視下這個位址下的裝置到底是什麼裝置:
可以看到這個報錯的裝置就是第四張顯示卡。
=================================
檢視作業系統的核心日志:
可以看到在伺服器當機的時候第四個顯示卡的電源模式轉為最高,再根據最初的當機時報錯的資訊我們可以估計出問題是第四個顯示卡在滿功率運作并且再進行記憶體和顯存的申請、讀取等操作,這時候核心陷入了死鎖等待。
造成系統當機的直接導火索是第4個顯示卡運作滿負荷,在進行I/O通道操作時造成了NMI的累計,最後形成了死鎖,但是其根本原因則是核心與nvidia顯示卡驅動的不比對問題。顯示卡滿負荷隻是誘因,直接導緻這個發生的則是核心太新,驅動太舊: