論文筆記:NLP之Attention is all you need. Transformer 的結構與特點
ref:
1.Step-by-step to Transformer:深入解析工作原理(以Pytorch機器翻譯為例)
2.How do Transformers Work in NLP? A Guide to the Latest State-of-the-Art Models
1. transformer的自注意力機制實際上是encoder和decoder自身内部分别對于各自語言模型的模組化,建立分布找到hidden。
2.Seq2Seq 中的context attention機制是encoder和decoder之間的hidden。
3. Mask:
encoder:self-attention中使用padding mask
decoder:self-attention中使用padding mask和sequence mask
context-attention中使用padding mask
4.Embedding:
- wording embedding
- position embedding: 對詞位置的編碼
5. LayerNorm: 在d-model次元上計算平均值和方差,并歸一化。
6. multi-head self-attention layer:
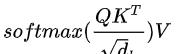
scaled dot-product attention 為了減輕梯度消失問題
multi-head 在初始化Q K V映射矩陣時,做多個線性映射
7.前向傳播 position-wise feed forward:為一個全連接配接層,用relu做激活函數
8. residual connection:目的是減輕梯度消失問題
9.結構上:
encoder:multihead self-attention + feed forward + ResNet
decoder:multihead self-attention + multihead context attention + feed forward + ResNet
10. Limitation:
由于在做資料分割時,把sequence分成了固定長度的片段。不同片段之間可能會失去上下文資訊。
一個改進工作為transformer-XL。使用前一片段的hidden作為context資訊補入目前訓練中。但是我的了解是,這樣處理會使Transformer-XL變回RNN類的模型,隻能按照時間序列處理資料,前一個資料未完成時無法進入下一訓練資料。使得模型的并行性下降。
![從詞向量衡量标準到全局向量的詞嵌入模型GloVe再到一詞多義的解決方式衡量标準Evaluation引子全局向量的詞嵌入應用對一詞多義的思考Reference[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)