ImagesPipeline是scrapy自帶的類,用來處理圖檔(爬取時将圖檔下載下傳到本地)用的。
優勢:
- 将下載下傳圖檔轉換成通用的JPG和RGB格式
- 避免重複下載下傳
- 縮略圖生成
- 圖檔大小過濾
- 異步下載下傳
- ......
工作流程:
- 爬取一個Item,将圖檔的URLs放入
image_urls
- 從
Spider
Item Pipeline
- 當
Item
ImagePipeline
image_urls
- 圖檔下載下傳成功結束後,圖檔下載下傳路徑、url和校驗和等資訊會被填充到images字段中。
實作方式:
- 自定義pipeline,優勢在于可以重寫ImagePipeline類中的實作方法,可以根據情況對照片進行分類;
- 直接使用ImagePipeline類,簡單但不夠靈活;所有的圖檔都是儲存在full檔案夾下,不能進行分類
實踐:爬取http://699pic.com/image/1/這個網頁下的前四個圖檔集(好進行分類示範)
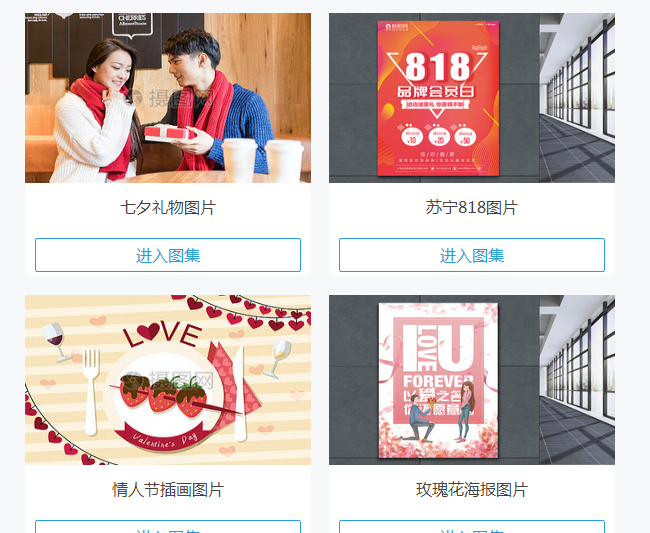
Scrapy自帶的ImagesPipeline下載下傳圖檔,并對其進行分類儲存案例
這裡使用方法一進行實作:
步驟一:建立項目與爬蟲
1.建立工程:scrapy startproject xxx(工程名)
2.建立爬蟲:進去到上一步建立的目錄下:scrapy genspider xxx(爬蟲名) xxx(域名)
步驟二:建立start.py
1 from scrapy import cmdline
2
3 cmdline.execute("scrapy crawl 699pic(爬蟲名)".split(" ")) 步驟三:設定settings
1.關閉機器人協定,改成False

2.設定headers
3.打開ITEM_PIPELINES
将項目自動生成的pipelines注釋掉,黃色部分是下面步驟中自己寫的pipeline,這裡先不寫。
步驟四:item
1 class Img699PicItem(scrapy.Item):
2 # 分類的标題
3 category=scrapy.Field()
4 # 存放圖檔位址
5 image_urls=scrapy.Field()
6 # 下載下傳成功後傳回有關images的一些相關資訊
7 images=scrapy.Field() 步驟五:寫spider
import scrapy
from ..items import Img699PicItem
import requests
from lxml import etree
class A699picSpider(scrapy.Spider):
name = '699pic'
allowed_domains = ['699pic.com']
start_urls = ['http://699pic.com/image/1/']
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.62 Safari/537.36'
}
def parse(self, response):
divs=response.xpath("//div[@class='special-list clearfix']/div")[0:4]
for div in divs:
category=div.xpath("./a[@class='special-list-title']//text()").get().strip()
url=div.xpath("./a[@class='special-list-title']/@href").get().strip()
image_urls=self.parse_url(url)
item=Img699PicItem(category=category,image_urls=image_urls)
yield item
def parse_url(self,url):
response=requests.get(url=url,headers=self.headers)
htmlElement=etree.HTML(response.text)
image_urls=htmlElement.xpath("//div[@class='imgshow clearfix']//div[@class='list']/a/img/@src")
return image_urls 步驟六:pipelines
import os
from scrapy.pipelines.images import ImagesPipeline
from . import settings
class Img699PicPipeline(object):
def process_item(self, item, spider):
return item
class Images699Pipeline(ImagesPipeline):
def get_media_requests(self, item, info):
# 這個方法是在發送下載下傳請求之前調用的,其實這個方法本身就是去發送下載下傳請求的
request_objs=super(Images699Pipeline, self).get_media_requests(item,info)
for request_obj in request_objs:
request_obj.item=item
return request_objs
def file_path(self, request, response=None, info=None):
# 這個方法是在圖檔将要被存儲的時候調用,來擷取這個圖檔存儲的路徑
path=super(Images699Pipeline, self).file_path(request,response,info)
category=request.item.get('category')
image_store=settings.IMAGES_STORE
category_path=os.path.join(image_store,category)
if not os.path.exists(category_path):
os.makedirs(category_path)
image_name=path.replace("full/","")
image_path=os.path.join(category_path,image_name)
return image_path 步驟七:傳回到settings中
1.将黃色部分填上
2.存放圖檔的總路徑
IMAGES_STORE=os.path.join(os.path.dirname(os.path.dirname(__file__)),'images')
最終結果: