1、urllib其實是一個包,包括了四個子產品:
urllib.request:用于打開和讀取 URL
urllib.parse:用于分解url
urllib.error:包括了ullib.request産生的異常
urllib.robotparser:分解robots.txt檔案
2、來說一下具體用法
比如用于通路百度
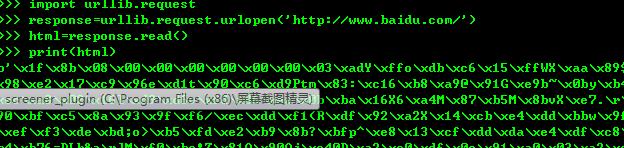
首先調用urllib包中request子產品,然後用urlopen方法打開URL
另外列印的結果感覺像亂碼,實際這是二進制碼。需要對其進行解碼代碼如下:
html=html.decode("utf-8")
print(html)
#要根據網頁所使用的編碼體制來決定解碼,在有道網站上,上面的語句運作後沒問題,在百度上,則用utf-8無法解碼,搞不清什麼原因
3、下載下傳一隻貓的例子
從http://placekitten.com/g/200/300下載下傳一張貓的圖檔
#導入request子產品
import urllib.request
#打開網站
response=urllib.request.urlopen('http://placekitten.com/g/200/300')
#将網站的回複指派給變量cat_img
cat_img=response.read()
#以wb的方法打開檔案cat.jpg,因為網站讀下來的資料是二進制
with open('cat.jpg','wb') as f:
#将變量cat_jpg寫入檔案cat.jpg
f.write(cat_img)
實際運作後确實生成了一個cat的jpg檔案,但無法打開

原因可能為網站的問題,我之前成功打開網站,也運作成功了。這次網站打不開,是以也下載下傳了空檔案。實際原因待查
4、用程式實作有道翻譯
用程式實作有道翻譯實際是模拟人工通路有道翻譯的模式,将其用程式實作
首先用python中的url包中的子產品實作通路送出資料,然後獲得其接口
但在實際運作以下程式時,發現實際不能正常運作,不知道為什麼
運作上述程式後,其結果如下,顯示待翻譯内容不能擷取
# coding=utf-8
"""
created on 2018/3/11
@author:hewp
程式作用:
"""
#引入urllib.request子產品和parse子產品
import urllib.request
import urllib.parse
#引入json子產品,json是一種輕量級的網絡資料交換格式,此處調用用于解析URL資料
import json
content=input("請輸入需要翻譯的内容:")
#輸入網站request位址,在網頁審查元素中擷取
url='http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule&smartresult=ugc'
#定義一個頭檔案字典,用于存儲頭檔案中的資料
head={}
#以下資料從審查元素中直接複制過來
head['Referer']='http://fanyi.youdao.com/'
head['User-Agent']='Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)
Chrome/64.0.3282.168 Safari/537.36 OPR/51.0.2830.40'
#data字典中的資料從審查元素中直接複雜
data = {
"type" : "AUTO",
"i" : content,
"doctype" : "json",
"xmlVersion" : "1.8",
"keyfrom" : "fanyi.web",
"ue" : "UTF-8",
"action" : "FY_BY_CLICKBUTTON",
"typoResult" : "true"
}
data=urllib.parse.urlencode(data).encode('utf-8')
req=urllib.request.Request(url,data,head)
response=urllib.request.urlopen(req)
html=response.read().decode('utf-8')
#此處是為了擷取解析html中的内容
target=json.loads(html)
#此處列印中的内容是為了擷取鍵translateResult對應的值
print("翻譯結果: %s" (target['translateResult'][0][0]['tgt']))
5、使用代理來通路網站
此點沒有實作,代碼如下,對代理的機制不太了解,沒找到代理ip要專門學習http中網絡技術的機制,得專門學習
代碼如下:
#程式說明:該程式是使用代理來通路文章,以此避免網站對”非人類“通路的拒絕
import urllib.request
url='http://www.whatismyip.com/'
proxy_support=urllib.request.ProxyHandler({'http':'211.138.121.38:80'})
#建立一個包含代理IP的opener
opener=urllib.request.build_opener(proxy_support)
#安裝進預設環境
urllib.request.install_opener(opener)
#試試看IP位址改了沒
response=urllib.request.urlopen(url)
html=response.read().decode('utf-8')
print(html)
運作結果如下