第3章 Java記憶體模型
Java線程之間的通信對程式員完全透明,記憶體可見性問題很容易困擾Java程式員,本章将揭開Java記憶體模型神秘的面紗。本章大緻分4部分:Java記憶體模型的基礎,主要介紹記憶體模型相關的基本概念;Java記憶體模型中的順序一緻性,主要介紹重排序與順序一緻性記憶體模型;同步原語,主要介紹3個同步原語(synchronized、volatile和final)的記憶體語義及重排序規則在處理器中的實作;Java記憶體模型的設計,主要介紹Java記憶體模型的設計原理,及其與處理器記憶體模型和順序一緻性記憶體模型的關系。
3.1 Java記憶體模型的基礎
3.1.1 并發程式設計模型的兩個關鍵問題
在并發程式設計中,需要處理兩個關鍵問題:線程之間如何通信及線程之間如何同步(這裡的線程是指并發執行的活動實體)。通信是指線程之間以何種機制來交換資訊。在指令式程式設計中,線程之間的通信機制有兩種:共享記憶體和消息傳遞。
在共享記憶體的并發模型裡,線程之間共享程式的公共狀态,通過寫-讀記憶體中的公共狀态進行隐式通信。在消息傳遞的并發模型裡,線程之間沒有公共狀态,線程之間必須通過發送消息來顯式進行通信。
同步是指程式中用于控制不同線程間操作發生相對順序的機制。在共享記憶體并發模型裡,同步是顯式進行的。程式員必須顯式指定某個方法或某段代碼需要線上程之間互斥執行。
在消息傳遞的并發模型裡,由于消息的發送必須在消息的接收之前,是以同步是隐式進行的。
Java的并發采用的是共享記憶體模型,Java線程之間的通信總是隐式進行,整個通信過程對程式員完全透明。如果編寫多線程程式的Java程式員不了解隐式進行的線程之間通信的工作機制,很可能會遇到各種奇怪的記憶體可見性問題。
3.1.2 Java記憶體模型的抽象結構
在Java中,所有執行個體域、靜态域和數組元素都存儲在堆記憶體中,堆記憶體線上程之間共享(本章用“共享變量”這個術語代指執行個體域,靜态域和數組元素)。局部變量(Local Variables),方法定義參數(Java語言規範稱之為Formal Method Parameters)和異常處理器參數(Exception Handler Parameters)不會線上程之間共享,它們不會有記憶體可見性問題,也不受記憶體模型的影響。
Java線程之間的通信由Java記憶體模型(本文簡稱為JMM)控制,JMM決定一個線程對共享變量的寫入何時對另一個線程可見。從抽象的角度來看,JMM定義了線程和主記憶體之間的抽象關系:線程之間的共享變量存儲在主記憶體(Main Memory)中,每個線程都有一個私有的本地記憶體(Local Memory),本地記憶體中存儲了該線程以讀/寫共享變量的副本。本地記憶體是JMM的一個抽象概念,并不真實存在。它涵蓋了緩存、寫緩沖區、寄存器以及其他的硬體和編譯器優化。Java記憶體模型的抽象示意如圖3-1所示。
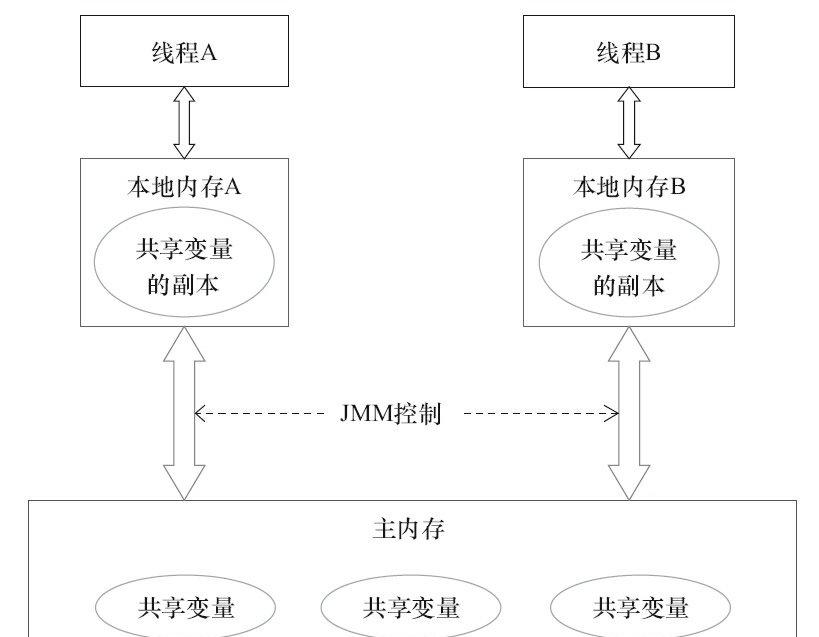
圖3-1 Java記憶體模型的抽象結構示意圖
從圖3-1來看,如果線程A與線程B之間要通信的話,必須要經曆下面2個步驟。
1)線程A把本地記憶體A中更新過的共享變量重新整理到主記憶體中去。
2)線程B到主記憶體中去讀取線程A之前已更新過的共享變量。
下面通過示意圖(見圖3-2)來說明這兩個步驟。

圖3-2 線程之間的通信圖
如圖3-2所示,本地記憶體A和本地記憶體B由主記憶體中共享變量x的副本。假設初始時,這3個記憶體中的x值都為0。線程A在執行時,把更新後的x值(假設值為1)臨時存放在自己的本地記憶體A中。當線程A和線程B需要通信時,線程A首先會把自己本地記憶體中修改後的x值重新整理到主記憶體中,此時主記憶體中的x值變為了1。随後,線程B到主記憶體中去讀取線程A更新後的x值,此時線程B的本地記憶體的x值也變為了1。
從整體來看,這兩個步驟實質上是線程A在向線程B發送消息,而且這個通信過程必須要經過主記憶體。JMM通過控制主記憶體與每個線程的本地記憶體之間的互動,來為Java程式員提供記憶體可見性保證。
3.1.3 從源代碼到指令序列的重排序
在執行程式時,為了提高性能,編譯器和處理器常常會對指令做重排序。重排序分3種類型。
1)編譯器優化的重排序。編譯器在不改變單線程程式語義的前提下,可以重新安排語句的執行順序。
2)指令級并行的重排序。現代處理器采用了指令級并行技術(Instruction-Level Parallelism,ILP)來将多條指令重疊執行。如果不存在資料依賴性,處理器可以改變語句對應機器指令的執行順序。
3)記憶體系統的重排序。由于處理器使用緩存和讀/寫緩沖區,這使得加載和存儲操作看上去可能是在亂序執行。
從Java源代碼到最終實際執行的指令序列,會分别經曆下面3種重排序,如圖3-3所示。
圖3-3 從源碼到最終執行的指令序列的示意圖
上述的1屬于編譯器重排序,2和3屬于處理器重排序。這些重排序可能會導緻多線程程式出現記憶體可見性問題。對于編譯器,JMM的編譯器重排序規則會禁止特定類型的編譯器重排序(不是所有的編譯器重排序都要禁止)。對于處理器重排序,JMM的處理器重排序規則會要求Java編譯器在生成指令序列時,插入特定類型的記憶體屏障(Memory Barriers,Intel稱之為Memory Fence)指令,通過記憶體屏障指令來禁止特定類型的處理器重排序。
JMM屬于語言級的記憶體模型,它確定在不同的編譯器和不同的處理器平台之上,通過禁止特定類型的編譯器重排序和處理器重排序,為程式員提供一緻的記憶體可見性保證。
3.1.4 并發程式設計模型的分類
現代的處理器使用寫緩沖區臨時儲存向記憶體寫入的資料。寫緩沖區可以保證指令流水線持續運作,它可以避免由于處理器停頓下來等待向記憶體寫入資料而産生的延遲。同時,通過以批處理的方式重新整理寫緩沖區,以及合并寫緩沖區中對同一記憶體位址的多次寫,減少對記憶體總線的占用。雖然寫緩沖區有這麼多好處,但每個處理器上的寫緩沖區,僅僅對它所在的處理器可見。這個特性會對記憶體操作的執行順序産生重要的影響:處理器對記憶體的讀/寫操作的執行順序,不一定與記憶體實際發生的讀/寫操作順序一緻!為了具體說明,請看下面的表3-1。
表3-1 處理器操作記憶體的執行結果
假設處理器A和處理器B按程式的順序并行執行記憶體通路,最終可能得到x=y=0的結果。具
體的原因如圖3-4所示。
圖3-4 處理器和記憶體的互動
這裡處理器A和處理器B可以同時把共享變量寫入自己的寫緩沖區(A1,B1),然後從記憶體中讀取另一個共享變量(A2,B2),最後才把自己寫緩存區中儲存的髒資料重新整理到記憶體中(A3,B3)。當以這種時序執行時,程式就可以得到x=y=0的結果。
從記憶體操作實際發生的順序來看,直到處理器A執行A3來重新整理自己的寫緩存區,寫操作A1才算真正執行了。雖然處理器A執行記憶體操作的順序為:A1→A2,但記憶體操作實際發生的順序卻是A2→A1。此時,處理器A的記憶體操作順序被重排序了(處理器B的情況和處理器A一樣,這裡就不贅述了)。
這裡的關鍵是,由于寫緩沖區僅對自己的處理器可見,它會導緻處理器執行記憶體操作的順序可能會與記憶體實際的操作執行順序不一緻。由于現代的處理器都會使用寫緩沖區,是以現代的處理器都會允許對寫-讀操作進行重排序。
表3-2是常見處理器允許的重排序類型的清單。
表3-2 處理器的重排序規則
注意,表3-2單元格中的“N”表示處理器不允許兩個操作重排序,“Y”表示允許重排序。
從表3-2我們可以看出:常見的處理器都允許Store-Load重排序;常見的處理器都不允許對存在資料依賴的操作做重排序。sparc-TSO和X86擁有相對較強的處理器記憶體模型,它們僅允許對寫-讀操作做重排序(因為它們都使用了寫緩沖區)。
注意
·sparc-TSO是指以TSO(Total Store Order)記憶體模型運作時sparc處理器的特性。
·表3-2中的X86包括X64及AMD64。
·由于ARM處理器的記憶體模型與PowerPC處理器的記憶體模型非常類似,本文将忽略它。
·資料依賴性後文會專門說明。
為了保證記憶體可見性,Java編譯器在生成指令序列的适當位置會插入記憶體屏障指令來禁止特定類型的處理器重排序。JMM把記憶體屏障指令分為4類,如表3-3所示。
表3-3 記憶體屏障類型表
StoreLoad Barriers是一個“全能型”的屏障,它同時具有其他3個屏障的效果。現代的多處理器大多支援該屏障(其他類型的屏障不一定被所有處理器支援)。執行該屏障開銷會很昂貴,因為目前處理器通常要把寫緩沖區中的資料全部重新整理到記憶體中(Buffer Fully Flush)。
3.1.5 happens-before簡介
從JDK 5開始,Java使用新的JSR-133記憶體模型(除非特别說明,本文針對的都是JSR-133記憶體模型)。JSR-133使用happens-before的概念來闡述操作之間的記憶體可見性。在JMM中,如果一個操作執行的結果需要對另一個操作可見,那麼這兩個操作之間必須要存在happens-before關系。這裡提到的兩個操作既可以是在一個線程之内,也可以是在不同線程之間。
與程式員密切相關的happens-before規則如下。
·程式順序規則:一個線程中的每個操作,happens-before于該線程中的任意後續操作。
·螢幕鎖規則:對一個鎖的解鎖,happens-before于随後對這個鎖的加鎖。
·volatile變量規則:對一個volatile域的寫,happens-before于任意後續對這個volatile域的讀。
·傳遞性:如果A happens-before B,且B happens-before C,那麼A happens-before C。
注意 兩個操作之間具有happens-before關系,并不意味着前一個操作必須要在後一個操作之前執行!happens-before僅僅要求前一個操作(執行的結果)對後一個操作可見,且前一個操作按順序排在第二個操作之前(the first is visible to and ordered before the second)。happens-before的定義很微妙,後文會具體說明happens-before為什麼要這麼定義。
happens-before與JMM的關系如圖3-5所示。
圖3-5 happens-before與JMM的關系
如圖3-5所示,一個happens-before規則對應于一個或多個編譯器和處理器重排序規則。對于Java程式員來說,happens-before規則簡單易懂,它避免Java程式員為了了解JMM提供的記憶體可見性保證而去學習複雜的重排序規則以及這些規則的具體實作方法。
3.2 重排序
重排序是指編譯器和處理器為了優化程式性能而對指令序列進行重新排序的一種手段。
3.2.1 資料依賴性
如果兩個操作通路同一個變量,且這兩個操作中有一個為寫操作,此時這兩個操作之間就存在資料依賴性。資料依賴分為下列3種類型,如表3-4所示。
表3-4 資料依賴類型表
上面3種情況,隻要重排序兩個操作的執行順序,程式的執行結果就會被改變。
前面提到過,編譯器和處理器可能會對操作做重排序。編譯器和處理器在重排序時,會遵守資料依賴性,編譯器和處理器不會改變存在資料依賴關系的兩個操作的執行順序。
這裡所說的資料依賴性僅針對單個處理器中執行的指令序列和單個線程中執行的操作,不同處理器之間和不同線程之間的資料依賴性不被編譯器和處理器考慮。
3.2.2 as-if-serial語義
as-if-serial語義的意思是:不管怎麼重排序(編譯器和處理器為了提高并行度),(單線程)程式的執行結果不能被改變。編譯器、runtime和處理器都必須遵守as-if-serial語義。
為了遵守as-if-serial語義,編譯器和處理器不會對存在資料依賴關系的操作做重排序,因為這種重排序會改變執行結果。但是,如果操作之間不存在資料依賴關系,這些操作就可能被編譯器和處理器重排序。為了具體說明,請看下面計算圓面積的代碼示例。
double pi = 3.14; // A
double r = 1.0; // B
double area = pi * r * r; // C
上面3個操作的資料依賴關系如圖3-6所示。
圖3-6 3個操作之間的依賴關系
如圖3-6所示,A和C之間存在資料依賴關系,同時B和C之間也存在資料依賴關系。是以在最終執行的指令序列中,C不能被重排序到A和B的前面(C排到A和B的前面,程式的結果将會被改變)。但A和B之間沒有資料依賴關系,編譯器和處理器可以重排序A和B之間的執行順序。
圖3-7是該程式的兩種執行順序。
圖3-7 程式的兩種執行順序
as-if-serial語義把單線程程式保護了起來,遵守as-if-serial語義的編譯器、runtime和處理器共同為編寫單線程程式的程式員建立了一個幻覺:單線程程式是按程式的順序來執行的。asif-serial語義使單線程程式員無需擔心重排序會幹擾他們,也無需擔心記憶體可見性問題。
3.2.3 程式順序規則
根據happens-before的程式順序規則,上面計算圓的面積的示例代碼存在3個happensbefore
關系。
1)A happens-before B。
2)B happens-before C。
3)A happens-before C。
這裡的第3個happens-before關系,是根據happens-before的傳遞性推導出來的。
這裡A happens-before B,但實際執行時B卻可以排在A之前執行(看上面的重排序後的執行順序)。如果A happens-before B,JMM并不要求A一定要在B之前執行。JMM僅僅要求前一個操作(執行的結果)對後一個操作可見,且前一個操作按順序排在第二個操作之前。這裡操作A的執行結果不需要對操作B可見;而且重排序操作A和操作B後的執行結果,與操作A和操作B按happens-before順序執行的結果一緻。在這種情況下,JMM會認為這種重排序并不非法(not illegal),JMM允許這種重排序。
在計算機中,軟體技術和硬體技術有一個共同的目标:在不改變程式執行結果的前提下,盡可能提高并行度。編譯器和處理器遵從這一目标,從happens-before的定義我們可以看出,JMM同樣遵從這一目标。
3.2.4 重排序對多線程的影響
現在讓我們來看看,重排序是否會改變多線程程式的執行結果。請看下面的示例代碼。
class ReorderExample {
int a = 0;
boolean flag = false;
public void writer() {
a = 1; // 1
flag = true; // 2
}
Public void reader() {
if (flag) { // 3
int i = a * a; // 4
//……
}
}
}
flag變量是個标記,用來辨別變量a是否已被寫入。這裡假設有兩個線程A和B,A首先執行writer()方法,随後B線程接着執行reader()方法。線程B在執行操作4時,能否看到線程A在操作1對共享變量a的寫入呢?
答案是:不一定能看到。
由于操作1和操作2沒有資料依賴關系,編譯器和處理器可以對這兩個操作重排序;同樣,操作3和操作4沒有資料依賴關系,編譯器和處理器也可以對這兩個操作重排序。讓我們先來看看,當操作1和操作2重排序時,可能會産生什麼效果?請看下面的程式執行時序圖,如圖3-8所示。
圖3-8 程式執行時序圖
如圖3-8所示,操作1和操作2做了重排序。程式執行時,線程A首先寫标記變量flag,随後線程B讀這個變量。由于條件判斷為真,線程B将讀取變量a。此時,變量a還沒有被線程A寫入,在這裡多線程程式的語義被重排序破壞了!
注意 本文統一用虛箭線辨別錯誤的讀操作,用實箭線辨別正确的讀操作。下面再讓我們看看,當操作3和操作4重排序時會産生什麼效果(借助這個重排序,可以順便說明控制依賴性)。下面是操作3和操作4重排序後,程式執行的時序圖,如圖3-9所示。
圖3-9 程式的執行時序圖
在程式中,操作3和操作4存在控制依賴關系。當代碼中存在控制依賴性時,會影響指令序列執行的并行度。為此,編譯器和處理器會采用猜測(Speculation)執行來克服控制相關性對并行度的影響。以處理器的猜測執行為例,執行線程B的處理器可以提前讀取并計算a*a,然後把計算結果臨時儲存到一個名為重排序緩沖(Reorder Buffer,ROB)的硬體緩存中。當操作3的條件判斷為真時,就把該計算結果寫入變量i中。
從圖3-9中我們可以看出,猜測執行實質上對操作3和4做了重排序。重排序在這裡破壞了多線程程式的語義!
在單線程程式中,對存在控制依賴的操作重排序,不會改變執行結果(這也是as-if-serial語義允許對存在控制依賴的操作做重排序的原因);但在多線程程式中,對存在控制依賴的操作重排序,可能會改變程式的執行結果。
3.3 順序一緻性
順序一緻性記憶體模型是一個理論參考模型,在設計的時候,處理器的記憶體模型和程式設計語言的記憶體模型都會以順序一緻性記憶體模型作為參照。
3.3.1 資料競争與順序一緻性
當程式未正确同步時,就可能會存在資料競争。Java記憶體模型規範對資料競争的定義如下。
在一個線程中寫一個變量,
在另一個線程讀同一個變量,
而且寫和讀沒有通過同步來排序。
當代碼中包含資料競争時,程式的執行往往産生違反直覺的結果(前一章的示例正是如此)。如果一個多線程程式能正确同步,這個程式将是一個沒有資料競争的程式。
JMM對正确同步的多線程程式的記憶體一緻性做了如下保證。
如果程式是正确同步的,程式的執行将具有順序一緻性(Sequentially Consistent)——即程式的執行結果與該程式在順序一緻性記憶體模型中的執行結果相同。馬上我們就會看到,這對于程式員來說是一個極強的保證。這裡的同步是指廣義上的同步,包括對常用同步原語(synchronized、volatile和final)的正确使用。
3.3.2 順序一緻性記憶體模型
順序一緻性記憶體模型是一個被計算機科學家理想化了的理論參考模型,它為程式員提供了極強的記憶體可見性保證。順序一緻性記憶體模型有兩大特性。
1)一個線程中的所有操作必須按照程式的順序來執行。
2)(不管程式是否同步)所有線程都隻能看到一個單一的操作執行順序。在順序一緻性記憶體模型中,每個操作都必須原子執行且立刻對所有線程可見。
順序一緻性記憶體模型為程式員提供的視圖如圖3-10所示。
圖3-10 順序一緻性記憶體模型的視圖
在概念上,順序一緻性模型有一個單一的全局記憶體,這個記憶體通過一個左右擺動的開關可以連接配接到任意一個線程,同時每一個線程必須按照程式的順序來執行記憶體讀/寫操作。從上面的示意圖可以看出,在任意時間點最多隻能有一個線程可以連接配接到記憶體。當多個線程并發執行時,圖中的開關裝置能把所有線程的所有記憶體讀/寫操作串行化(即在順序一緻性模型中,所有操作之間具有全序關系)。
為了更好進行了解,下面通過兩個示意圖來對順序一緻性模型的特性做進一步的說明。
假設有兩個線程A和B并發執行。其中A線程有3個操作,它們在程式中的順序是:
A1→A2→A3。B線程也有3個操作,它們在程式中的順序是:B1→B2→B3。
假設這兩個線程使用螢幕鎖來正确同步:A線程的3個操作執行後釋放螢幕鎖,随後B
線程擷取同一個螢幕鎖。那麼程式在順序一緻性模型中的執行效果将如圖3-11所示。
圖3-11 順序一緻性模型的一種執行效果
現在我們再假設這兩個線程沒有做同步,下面是這個未同步程式在順序一緻性模型中的執行示意圖,如圖3-12所示。
圖3-12 順序一緻性模型中的另一種執行效果
未同步程式在順序一緻性模型中雖然整體執行順序是無序的,但所有線程都隻能看到一個一緻的整體執行順序。以上圖為例,線程A和B看到的執行順序都是:
B1→A1→A2→B2→A3→B3。之是以能得到這個保證是因為順序一緻性記憶體模型中的每個操作必須立即對任意線程可見。
但是,在JMM中就沒有這個保證。未同步程式在JMM中不但整體的執行順序是無序的,而且所有線程看到的操作執行順序也可能不一緻。比如,在目前線程把寫過的資料緩存在本地
記憶體中,在沒有重新整理到主記憶體之前,這個寫操作僅對目前線程可見;從其他線程的角度來觀察,會認為這個寫操作根本沒有被目前線程執行。隻有目前線程把本地記憶體中寫過的資料重新整理到主記憶體之後,這個寫操作才能對其他線程可見。在這種情況下,目前線程和其他線程看到的操作執行順序将不一緻。
3.3.3 同步程式的順序一緻性效果
下面,對前面的示例程式ReorderExample用鎖來同步,看看正确同步的程式如何具有順序一緻性。
請看下面的示例代碼。
class SynchronizedExample {
int a = 0;
boolean flag = false;
public synchronized void writer() { // 擷取鎖
a = 1;
flag = true;
} // 釋放鎖
public synchronized void reader() { // 擷取鎖
if (flag) {
int i = a;
……
} // 釋放鎖
}
}
在上面示例代碼中,假設A線程執行writer()方法後,B線程執行reader()方法。這是一個正确同步的多線程程式。根據JMM規範,該程式的執行結果将與該程式在順序一緻性模型中的執行結果相同。下面是該程式在兩個記憶體模型中的執行時序對比圖,如圖3-13所示。
順序一緻性模型中,所有操作完全按程式的順序串行執行。而在JMM中,臨界區内的代碼可以重排序(但JMM不允許臨界區内的代碼“逸出”到臨界區之外,那樣會破壞螢幕的語義)。JMM會在退出臨界區和進入臨界區這兩個關鍵時間點做一些特别處理,使得線程在這兩個時間點具有與順序一緻性模型相同的記憶體視圖(具體細節後文會說明)。雖然線程A在臨界區内做了重排序,但由于螢幕互斥執行的特性,這裡的線程B根本無法“觀察”到線程A在臨界區内的重排序。這種重排序既提高了執行效率,又沒有改變程式的執行結果。
圖3-13 兩個記憶體模型中的執行時序對比圖
從這裡我們可以看到,JMM在具體實作上的基本方針為:在不改變(正确同步的)程式執
行結果的前提下,盡可能地為編譯器和處理器的優化打開友善之門。
3.3.4 未同步程式的執行特性
對于未同步或未正确同步的多線程程式,JMM隻提供最小安全性:線程執行時讀取到的值,要麼是之前某個線程寫入的值,要麼是預設值(0,Null,False),JMM保證線程讀操作讀取到的值不會無中生有(Out Of Thin Air)的冒出來。為了實作最小安全性,JVM在堆上配置設定對象時,首先會對記憶體空間進行清零,然後才會在上面配置設定對象(JVM内部會同步這兩個操作)。是以,在已清零的記憶體空間(Pre-zeroed Memory)配置設定對象時,域的預設初始化已經完成了。
JMM不保證未同步程式的執行結果與該程式在順序一緻性模型中的執行結果一緻。因為如果想要保證執行結果一緻,JMM需要禁止大量的處理器和編譯器的優化,這對程式的執行性能會産生很大的影響。而且未同步程式在順序一緻性模型中執行時,整體是無序的,其執行結果往往無法預知。而且,保證未同步程式在這兩個模型中的執行結果一緻沒什麼意義。未同步程式在JMM中的執行時,整體上是無序的,其執行結果無法預知。未同步程式在兩個模型中的執行特性有如下幾個差異。
1)順序一緻性模型保證單線程内的操作會按程式的順序執行,而JMM不保證單線程内的操作會按程式的順序執行(比如上面正确同步的多線程程式在臨界區内的重排序)。這一點前面已經講過了,這裡就不再贅述。
2)順序一緻性模型保證所有線程隻能看到一緻的操作執行順序,而JMM不保證所有線程能看到一緻的操作執行順序。這一點前面也已經講過,這裡就不再贅述。
3)JMM不保證對64位的long型和double型變量的寫操作具有原子性,而順序一緻性模型保證對所有的記憶體讀/寫操作都具有原子性。
第3個差異與處理器總線的工作機制密切相關。在計算機中,資料通過總線在處理器和記憶體之間傳遞。每次處理器和記憶體之間的資料傳遞都是通過一系列步驟來完成的,這一系列步驟稱之為總線事務(Bus Transaction)。總線事務包括讀事務(Read Transaction)和寫事務(Write Transaction)。讀事務從記憶體傳送資料到處理器,寫事務從處理器傳送資料到記憶體,每個事務會讀/寫記憶體中一個或多個實體上連續的字。這裡的關鍵是,總線會同步試圖并發使用總線的事務。在一個處理器執行總線事務期間,總線會禁止其他的處理器和I/O裝置執行記憶體的讀/寫。
下面,讓我們通過一個示意圖來說明總線的工作機制,如圖3-14所示。
圖3-14 總線的工作機制
由圖可知,假設處理器A,B和C同時向總線發起總線事務,這時總線仲裁(Bus Arbitration)會對競争做出裁決,這裡假設總線在仲裁後判定處理器A在競争中獲勝(總線仲裁會確定所有處理器都能公平的通路記憶體)。此時處理器A繼續它的總線事務,而其他兩個處理器則要等待處理器A的總線事務完成後才能再次執行記憶體通路。假設在處理器A執行總線事務期間(不管這個總線事務是讀事務還是寫事務),處理器D向總線發起了總線事務,此時處理器D的請求會被總線禁止。
總線的這些工作機制可以把所有處理器對記憶體的通路以串行化的方式來執行。在任意時間點,最多隻能有一個處理器可以通路記憶體。這個特性確定了單個總線事務之中的記憶體讀/寫操作具有原子性。
在一些32位的處理器上,如果要求對64位資料的寫操作具有原子性,會有比較大的開銷。為了照顧這種處理器,Java語言規範鼓勵但不強求JVM對64位的long型變量和double型變量的寫操作具有原子性。當JVM在這種處理器上運作時,可能會把一個64位long/double型變量的寫操作拆分為兩個32位的寫操作來執行。這兩個32位的寫操作可能會被配置設定到不同的總線事務中執行,此時對這個64位變量的寫操作将不具有原子性。
當單個記憶體操作不具有原子性時,可能會産生意想不到後果。請看示意圖,如圖3-15所示。
圖3-15 總線事務執行的時序圖
如上圖所示,假設處理器A寫一個long型變量,同時處理器B要讀這個long型變量。處理器A中64位的寫操作被拆分為兩個32位的寫操作,且這兩個32位的寫操作被配置設定到不同的寫事務中執行。同時,處理器B中64位的讀操作被配置設定到單個的讀事務中執行。當處理器A和B按上圖的時序來執行時,處理器B将看到僅僅被處理器A“寫了一半”的無效值。
注意,在JSR-133之前的舊記憶體模型中,一個64位long/double型變量的讀/寫操作可以被拆分為兩個32位的讀/寫操作來執行。從JSR-133記憶體模型開始(即從JDK5開始),僅僅隻允許把一個64位long/double型變量的寫操作拆分為兩個32位的寫操作來執行,任意的讀操作在JSR-133中都必須具有原子性(即任意讀操作必須要在單個讀事務中執行)。
3.4 volatile的記憶體語義
當聲明共享變量為volatile後,對這個變量的讀/寫将會很特别。為了揭開volatile的神秘面紗,下面将介紹volatile的記憶體語義及volatile記憶體語義的實作。
3.4.1 volatile的特性
了解volatile特性的一個好方法是把對volatile變量的單個讀/寫,看成是使用同一個鎖對這些單個讀/寫操作做了同步。下面通過具體的示例來說明,示例代碼如下。
class VolatileFeaturesExample {
volatile long vl = 0L; // 使用volatile聲明64位的long型變量
public void set(long l) {
vl = l; // 單個volatile變量的寫
}
public void getAndIncrement () {
vl++; // 複合(多個)volatile變量的讀/寫
}
public long get() {
return vl; // 單個volatile變量的讀
}
}
假設有多個線程分别調用上面程式的3個方法,這個程式在語義上和下面程式等價。
class VolatileFeaturesExample {
long vl = 0L; // 64位的long型普通變量
public synchronized void set(long l) { // 對單個的普通變量的寫用同一個鎖同步
vl = l;
}
public void getAndIncrement () { // 普通方法調用
long temp = get(); // 調用已同步的讀方法
temp += 1L; // 普通寫操作
set(temp); // 調用已同步的寫方法
}
public synchronized long get() { // 對單個的普通變量的讀用同一個鎖同步
return vl;
}
}
如上面示例程式所示,一個volatile變量的單個讀/寫操作,與一個普通變量的讀/寫操作都是使用同一個鎖來同步,它們之間的執行效果相同。
鎖的happens-before規則保證釋放鎖和擷取鎖的兩個線程之間的記憶體可見性,這意味着對一個volatile變量的讀,總是能看到(任意線程)對這個volatile變量最後的寫入。
鎖的語義決定了臨界區代碼的執行具有原子性。這意味着,即使是64位的long型和double型變量,隻要它是volatile變量,對該變量的讀/寫就具有原子性。如果是多個volatile操作或類似于volatile++這種複合操作,這些操作整體上不具有原子性。
簡而言之,volatile變量自身具有下列特性。
·可見性。對一個volatile變量的讀,總是能看到(任意線程)對這個volatile變量最後的寫入。
·原子性:對任意單個volatile變量的讀/寫具有原子性,但類似于volatile++這種複合操作不具有原子性。
3.4.2 volatile寫-讀建立的happens-before關系
上面講的是volatile變量自身的特性,對程式員來說,volatile對線程的記憶體可見性的影響比volatile自身的特性更為重要,也更需要我們去關注。
從JSR-133開始(即從JDK5開始),volatile變量的寫-讀可以實作線程之間的通信。
從記憶體語義的角度來說,volatile的寫-讀與鎖的釋放-擷取有相同的記憶體效果:volatile寫和鎖的釋放有相同的記憶體語義;volatile讀與鎖的擷取有相同的記憶體語義。
請看下面使用volatile變量的示例代碼。
class VolatileExample {
int a = 0;
volatile boolean flag = false;
public void writer() {
a = 1; // 1
flag = true; // 2
}
public void reader() {
if (flag) { // 3
int i = a; // 4
……
}
}
}
假設線程A執行writer()方法之後,線程B執行reader()方法。根據happens-before規則,這個
過程建立的happens-before關系可以分為3類:
1)根據程式次序規則,1 happens-before 2;3 happens-before 4。
2)根據volatile規則,2 happens-before 3。
3)根據happens-before的傳遞性規則,1 happens-before 4。
上述happens-before關系的圖形化表現形式如下。
圖3-16 happens-before關系
在上圖中,每一個箭頭連結的兩個節點,代表了一個happens-before關系。黑色箭頭表示程式順序規則;橙色箭頭表示volatile規則;藍色箭頭表示組合這些規則後提供的happens-before保證。
這裡A線程寫一個volatile變量後,B線程讀同一個volatile變量。A線程在寫volatile變量之前所有可見的共享變量,在B線程讀同一個volatile變量後,将立即變得對B線程可見。
注意 本文統一用粗實線辨別組合後産生的happens-before關系。
3.4.3 volatile寫-讀的記憶體語義
volatile寫的記憶體語義如下。
當寫一個volatile變量時,JMM會把該線程對應的本地記憶體中的共享變量值重新整理到主記憶體。
以上面示例程式VolatileExample為例,假設線程A首先執行writer()方法,随後線程B執行
reader()方法,初始時兩個線程的本地記憶體中的flag和a都是初始狀态。圖3-17是線程A執行volatile寫後,共享變量的狀态示意圖。
圖3-17 共享變量的狀态示意圖
如圖3-17所示,線程A在寫flag變量後,本地記憶體A中被線程A更新過的兩個共享變量的值被重新整理到主記憶體中。此時,本地記憶體A和主記憶體中的共享變量的值是一緻的。
volatile讀的記憶體語義如下。
當讀一個volatile變量時,JMM會把該線程對應的本地記憶體置為無效。線程接下來将從主記憶體中讀取共享變量。
圖3-18為線程B讀同一個volatile變量後,共享變量的狀态示意圖。
如圖所示,在讀flag變量後,本地記憶體B包含的值已經被置為無效。此時,線程B必須從主記憶體中讀取共享變量。線程B的讀取操作将導緻本地記憶體B與主記憶體中的共享變量的值變成一緻。
如果我們把volatile寫和volatile讀兩個步驟綜合起來看的話,在讀線程B讀一個volatile變量後,寫線程A在寫這個volatile變量之前所有可見的共享變量的值都将立即變得對讀線程B可見。
下面對volatile寫和volatile讀的記憶體語義做個總結。
·線程A寫一個volatile變量,實質上是線程A向接下來将要讀這個volatile變量的某個線程發出了(其對共享變量所做修改的)消息。
·線程B讀一個volatile變量,實質上是線程B接收了之前某個線程發出的(在寫這個volatile變量之前對共享變量所做修改的)消息。
·線程A寫一個volatile變量,随後線程B讀這個volatile變量,這個過程實質上是線程A通過主記憶體向線程B發送消息。
圖3-18 共享變量的狀态示意圖
3.4.4 volatile記憶體語義的實作
下面來看看JMM如何實作volatile寫/讀的記憶體語義。
前文提到過重排序分為編譯器重排序和處理器重排序。為了實作volatile記憶體語義,JMM會分别限制這兩種類型的重排序類型。表3-5是JMM針對編譯器制定的volatile重排序規則表。
表3-5 volatile重排序規則表
舉例來說,第三行最後一個單元格的意思是:在程式中,當第一個操作為普通變量的讀或寫時,如果第二個操作為volatile寫,則編譯器不能重排序這兩個操作。
從表3-5我們可以看出。
·當第二個操作是volatile寫時,不管第一個操作是什麼,都不能重排序。這個規則確定volatile寫之前的操作不會被編譯器重排序到volatile寫之後。
·當第一個操作是volatile讀時,不管第二個操作是什麼,都不能重排序。這個規則確定volatile讀之後的操作不會被編譯器重排序到volatile讀之前。
·當第一個操作是volatile寫,第二個操作是volatile讀時,不能重排序。
為了實作volatile的記憶體語義,編譯器在生成位元組碼時,會在指令序列中插入記憶體屏障來禁止特定類型的處理器重排序。對于編譯器來說,發現一個最優布置來最小化插入屏障的總數幾乎不可能。為此,JMM采取保守政策。下面是基于保守政策的JMM記憶體屏障插入政策。
·在每個volatile寫操作的前面插入一個StoreStore屏障。
·在每個volatile寫操作的後面插入一個StoreLoad屏障。
·在每個volatile讀操作的後面插入一個LoadLoad屏障。
·在每個volatile讀操作的後面插入一個LoadStore屏障。
上述記憶體屏障插入政策非常保守,但它可以保證在任意處理器平台,任意的程式中都能得到正确的volatile記憶體語義。
下面是保守政策下,volatile寫插入記憶體屏障後生成的指令序列示意圖,如圖3-19所示。
圖3-19 指令序列示意圖
圖3-19中的StoreStore屏障可以保證在volatile寫之前,其前面的所有普通寫操作已經對任意處理器可見了。這是因為StoreStore屏障将保障上面所有的普通寫在volatile寫之前重新整理到主記憶體。
這裡比較有意思的是,volatile寫後面的StoreLoad屏障。此屏障的作用是避免volatile寫與後面可能有的volatile讀/寫操作重排序。因為編譯器常常無法準确判斷在一個volatile寫的後面是否需要插入一個StoreLoad屏障(比如,一個volatile寫之後方法立即return)。為了保證能正确實作volatile的記憶體語義,JMM在采取了保守政策:在每個volatile寫的後面,或者在每個volatile讀的前面插入一個StoreLoad屏障。從整體執行效率的角度考慮,JMM最終選擇了在每個volatile寫的後面插入一個StoreLoad屏障。因為volatile寫-讀記憶體語義的常見使用模式是:一個寫線程寫volatile變量,多個讀線程讀同一個volatile變量。當讀線程的數量大大超過寫線程時,選擇在volatile寫之後插入StoreLoad屏障将帶來可觀的執行效率的提升。從這裡可以看到JMM在實作上的一個特點:首先確定正确性,然後再去追求執行效率。
下面是在保守政策下,volatile讀插入記憶體屏障後生成的指令序列示意圖,如圖3-20所示。
圖3-20 指令序列示意圖
圖3-20中的LoadLoad屏障用來禁止處理器把上面的volatile讀與下面的普通讀重排序。LoadStore屏障用來禁止處理器把上面的volatile讀與下面的普通寫重排序。
上述volatile寫和volatile讀的記憶體屏障插入政策非常保守。在實際執行時,隻要不改變volatile寫-讀的記憶體語義,編譯器可以根據具體情況省略不必要的屏障。下面通過具體的示例代碼進行說明。
class VolatileBarrierExample {
int a;
volatile int v1 = 1;
volatile int v2 = 2;
void readAndWrite() {
int i = v1; // 第一個volatile讀
int j = v2; // 第二個volatile讀
a = i + j; // 普通寫
v1 = i + 1; // 第一個volatile寫
v2 = j * 2; // 第二個 volatile寫
}
//... // 其他方法
}
針對readAndWrite()方法,編譯器在生成位元組碼時可以做如下的優化。
圖3-21 指令序列示意圖
注意,最後的StoreLoad屏障不能省略。因為第二個volatile寫之後,方法立即return。此時編譯器可能無法準确斷定後面是否會有volatile讀或寫,為了安全起見,編譯器通常會在這裡插入一個StoreLoad屏障。
上面的優化針對任意處理器平台,由于不同的處理器有不同“松緊度”的處理器記憶體模型,記憶體屏障的插入還可以根據具體的處理器記憶體模型繼續優化。以X86處理器為例,圖3-21中除最後的StoreLoad屏障外,其他的屏障都會被省略。
前面保守政策下的volatile讀和寫,在X86處理器平台可以優化成如圖3-22所示。
前文提到過,X86處理器僅會對寫-讀操作做重排序。X86不會對讀-讀、讀-寫和寫-寫操作做重排序,是以在X86處理器中會省略掉這3種操作類型對應的記憶體屏障。在X86中,JMM僅需在volatile寫後面插入一個StoreLoad屏障即可正确實作volatile寫-讀的記憶體語義。這意味着在X86處理器中,volatile寫的開銷比volatile讀的開銷會大很多(因為執行StoreLoad屏障開銷會比較大)。
圖3-22 指令序列示意圖
3.4.5 JSR-133為什麼要增強volatile的記憶體語義
在JSR-133之前的舊Java記憶體模型中,雖然不允許volatile變量之間重排序,但舊的Java記憶體模型允許volatile變量與普通變量重排序。在舊的記憶體模型中,VolatileExample示例程式可能被重排序成下列時序來執行,如圖3-23所示。
圖3-23 線程執行時序圖
在舊的記憶體模型中,當1和2之間沒有資料依賴關系時,1和2之間就可能被重排序(3和4類似)。其結果就是:讀線程B執行4時,不一定能看到寫線程A在執行1時對共享變量的修改。
是以,在舊的記憶體模型中,volatile的寫-讀沒有鎖的釋放-獲所具有的記憶體語義。為了提供一種比鎖更輕量級的線程之間通信的機制,JSR-133專家組決定增強volatile的記憶體語義:嚴格限制編譯器和處理器對volatile變量與普通變量的重排序,確定volatile的寫-讀和鎖的釋放-擷取具有相同的記憶體語義。從編譯器重排序規則和處理器記憶體屏障插入政策來看,隻要volatile變量與普通變量之間的重排序可能會破壞volatile的記憶體語義,這種重排序就會被編譯器重排序規則和處理器記憶體屏障插入政策禁止。
由于volatile僅僅保證對單個volatile變量的讀/寫具有原子性,而鎖的互斥執行的特性可以確定對整個臨界區代碼的執行具有原子性。在功能上,鎖比volatile更強大;在可伸縮性和執行性能上,volatile更有優勢。如果讀者想在程式中用volatile代替鎖,請一定謹慎,具體詳情請參閱Brian Goetz的文章《Java理論與實踐:正确使用Volatile變量》。
3.5 鎖的記憶體語義
衆所周知,鎖可以讓臨界區互斥執行。這裡将介紹鎖的另一個同樣重要,但常常被忽視的功能:鎖的記憶體語義。
3.5.1 鎖的釋放-擷取建立的happens-before關系
鎖是Java并發程式設計中最重要的同步機制。鎖除了讓臨界區互斥執行外,還可以讓釋放鎖的線程向擷取同一個鎖的線程發送消息。
下面是鎖釋放-擷取的示例代碼。
class MonitorExample {
int a = 0;
public synchronized void writer() { // 1
a++; // 2
} // 3
public synchronized void reader() { // 4
int i = a; // 5
……
} // 6
}
假設線程A執行writer()方法,随後線程B執行reader()方法。根據happens-before規則,這個過程包含的happens-before關系可以分為3類。
1)根據程式次序規則,1 happens-before 2,2 happens-before 3;4 happens-before 5,5 happensbefore6。
2)根據螢幕鎖規則,3 happens-before 4。
3)根據happens-before的傳遞性,2 happens-before 5。
上述happens-before關系的圖形化表現形式如圖3-24所示。
圖3-24 happens-before關系圖
在圖3-24中,每一個箭頭連結的兩個節點,代表了一個happens-before關系。黑色箭頭表示程式順序規則;橙色箭頭表示螢幕鎖規則;藍色箭頭表示組合這些規則後提供的happens-before保證。
圖3-24表示線上程A釋放了鎖之後,随後線程B擷取同一個鎖。在上圖中,2 happens-before 5。是以,線程A在釋放鎖之前所有可見的共享變量,線上程B擷取同一個鎖之後,将立刻變得對B線程可見。
3.5.2 鎖的釋放-擷取的記憶體語義
當線程釋放鎖時,JMM會把該線程對應的本地記憶體中的共享變量重新整理到主記憶體中。以上面的MonitorExample程式為例,A線程釋放鎖後,共享資料的狀态示意圖如圖3-25所示。
圖3-25 共享資料的狀态示意圖
當線程擷取鎖時,JMM會把該線程對應的本地記憶體置為無效。進而使得被螢幕保護的臨界區代碼必須從主記憶體中讀取共享變量。圖3-26是鎖擷取的狀态示意圖。
圖3-26 鎖擷取的狀态示意圖
對比鎖釋放-擷取的記憶體語義與volatile寫-讀的記憶體語義可以看出:鎖釋放與volatile寫有相同的記憶體語義;鎖擷取與volatile讀有相同的記憶體語義。
下面對鎖釋放和鎖擷取的記憶體語義做個總結。
·線程A釋放一個鎖,實質上是線程A向接下來将要擷取這個鎖的某個線程發出了(線程A對共享變量所做修改的)消息。
·線程B擷取一個鎖,實質上是線程B接收了之前某個線程發出的(在釋放這個鎖之前對共享變量所做修改的)消息。
·線程A釋放鎖,随後線程B擷取這個鎖,這個過程實質上是線程A通過主記憶體向線程B發送消息。
3.5.3 鎖記憶體語義的實作
本文将借助ReentrantLock的源代碼,來分析鎖記憶體語義的具體實作機制。
請看下面的示例代碼。
class ReentrantLockExample {
int a = 0;
ReentrantLock lock = new ReentrantLock();
public void writer() {
lock.lock(); // 擷取鎖
try {
a++;
} finally {
lock.unlock(); // 釋放鎖
}
}
public void reader () {
lock.lock(); // 擷取鎖
try {
int i = a;
……
} finally {
lock.unlock(); // 釋放鎖
}
}
}
在ReentrantLock中,調用lock()方法擷取鎖;調用unlock()方法釋放鎖。
ReentrantLock的實作依賴于Java同步器架構AbstractQueuedSynchronizer(本文簡稱之為AQS)。AQS使用一個整型的volatile變量(命名為state)來維護同步狀态,馬上我們會看到,這個volatile變量是ReentrantLock記憶體語義實作的關鍵。
圖3-27是ReentrantLock的類圖(僅畫出與本文相關的部分)。
圖3-27 ReentrantLock的類圖
ReentrantLock分為公平鎖和非公平鎖,我們首先分析公平鎖。
使用公平鎖時,加鎖方法lock()調用軌迹如下。
1)ReentrantLock:lock()。
2)FairSync:lock()。
3)AbstractQueuedSynchronizer:acquire(int arg)。
4)ReentrantLock:tryAcquire(int acquires)。
在第4步真正開始加鎖,下面是該方法的源代碼。
protected final boolean tryAcquire(int acquires) {
final Thread current = Thread.currentThread();
int c = getState(); // 擷取鎖的開始,首先讀volatile變量state
if (c == 0) {
if (isFirst(current) &&
compareAndSetState(0, acquires)) {
setExclusiveOwnerThread(current);
return true;
}
}
else if (current == getExclusiveOwnerThread()) {
int nextc = c + acquires;
if (nextc < 0)
throw new Error("Maximum lock count exceeded");
setState(nextc);
return true;
}
return false;
}
從上面源代碼中我們可以看出,加鎖方法首先讀volatile變量state。
在使用公平鎖時,解鎖方法unlock()調用軌迹如下。
1)ReentrantLock:unlock()。
2)AbstractQueuedSynchronizer:release(int arg)。
3)Sync:tryRelease(int releases)。
在第3步真正開始釋放鎖,下面是該方法的源代碼。
protected final boolean tryRelease(int releases) {
int c = getState() - releases;
if (Thread.currentThread() != getExclusiveOwnerThread())
throw new IllegalMonitorStateException();
boolean free = false;
if (c == 0) {
free = true;
setExclusiveOwnerThread(null);
}
setState(c); // 釋放鎖的最後,寫volatile變量state
return free;
}
從上面的源代碼可以看出,在釋放鎖的最後寫volatile變量state。
公平鎖在釋放鎖的最後寫volatile變量state,在擷取鎖時首先讀這個volatile變量。根據volatile的happens-before規則,釋放鎖的線程在寫volatile變量之前可見的共享變量,在擷取鎖的線程讀取同一個volatile變量後将立即變得對擷取鎖的線程可見。
現在我們來分析非公平鎖的記憶體語義的實作。非公平鎖的釋放和公平鎖完全一樣,是以
這裡僅僅分析非公平鎖的擷取。使用非公平鎖時,加鎖方法lock()調用軌迹如下。
1)ReentrantLock:lock()。
2)NonfairSync:lock()。
3)AbstractQueuedSynchronizer:compareAndSetState(int expect,int update)。
在第3步真正開始加鎖,下面是該方法的源代碼。
protected final boolean compareAndSetState(int expect, int update) {
return unsafe.compareAndSwapInt(this, stateOffset, expect, update);
}
該方法以原子操作的方式更新state變量,本文把Java的compareAndSet()方法調用簡稱為CAS。JDK文檔對該方法的說明如下:如果目前狀态值等于預期值,則以原子方式将同步狀态設定為給定的更新值。此操作具有volatile讀和寫的記憶體語義。
這裡我們分别從編譯器和處理器的角度來分析,CAS如何同時具有volatile讀和volatile寫的記憶體語義。
前文我們提到過,編譯器不會對volatile讀與volatile讀後面的任意記憶體操作重排序;編譯器不會對volatile寫與volatile寫前面的任意記憶體操作重排序。組合這兩個條件,意味着為了同時實作volatile讀和volatile寫的記憶體語義,編譯器不能對CAS與CAS前面和後面的任意記憶體操作重排序。
下面我們來分析在常見的intel X86處理器中,CAS是如何同時具有volatile讀和volatile寫的記憶體語義的。
下面是sun.misc.Unsafe類的compareAndSwapInt()方法的源代碼。
可以看到,這是一個本地方法調用。這個本地方法在openjdk中依次調用的c++代碼為:
unsafe.cpp,atomic.cpp和atomic_windows_x86.inline.hpp。這個本地方法的最終實作在openjdk的如下位置:openjdk-7-fcs-src-b147-27_jun_2011\openjdk\hotspot\src\os_cpu\windows_x86\vm\atomic_windows_x86.inline.hpp(對應于Windows作業系統,X86處理器)。下面是對應于intel X86處理器的源代碼的片段。
inline jint Atomic::cmpxchg (jint exchange_value, volatile jint* dest,
jint compare_value) {
// alternative for InterlockedCompareExchange
int mp = os::is_MP();
__asm {
mov edx, dest
mov ecx, exchange_value
mov eax, compare_value
LOCK_IF_MP(mp)
cmpxchg dword ptr [edx], ecx
}
}
如上面源代碼所示,程式會根據目前處理器的類型來決定是否為cmpxchg指令添加lock字首。如果程式是在多處理器上運作,就為cmpxchg指令加上lock字首(Lock Cmpxchg)。反之,如果程式是在單處理器上運作,就省略lock字首(單處理器自身會維護單處理器内的順序一緻性,不需要lock字首提供的記憶體屏障效果)。
intel的手冊對lock字首的說明如下。
1)確定對記憶體的讀-改-寫操作原子執行。在Pentium及Pentium之前的處理器中,帶有lock字首的指令在執行期間會鎖住總線,使得其他處理器暫時無法通過總線通路記憶體。很顯然,這會帶來昂貴的開銷。從Pentium 4、Intel Xeon及P6處理器開始,Intel使用緩存鎖定(Cache Locking)來保證指令執行的原子性。緩存鎖定将大大降低lock字首指令的執行開銷。
2)禁止該指令,與之前和之後的讀和寫指令重排序。
3)把寫緩沖區中的所有資料重新整理到記憶體中。
上面的第2點和第3點所具有的記憶體屏障效果,足以同時實作volatile讀和volatile寫的記憶體語義。
經過上面的分析,現在我們終于能明白為什麼JDK文檔說CAS同時具有volatile讀和volatile寫的記憶體語義了。
現在對公平鎖和非公平鎖的記憶體語義做個總結。
·公平鎖和非公平鎖釋放時,最後都要寫一個volatile變量state。
·公平鎖擷取時,首先會去讀volatile變量。
·非公平鎖擷取時,首先會用CAS更新volatile變量,這個操作同時具有volatile讀和volatile寫的記憶體語義。
從本文對ReentrantLock的分析可以看出,鎖釋放-擷取的記憶體語義的實作至少有下面兩種方式。
1)利用volatile變量的寫-讀所具有的記憶體語義。
2)利用CAS所附帶的volatile讀和volatile寫的記憶體語義。
3.5.4 concurrent包的實作
由于Java的CAS同時具有volatile讀和volatile寫的記憶體語義,是以Java線程之間的通信現在有了下面4種方式。
1)A線程寫volatile變量,随後B線程讀這個volatile變量。
2)A線程寫volatile變量,随後B線程用CAS更新這個volatile變量。
3)A線程用CAS更新一個volatile變量,随後B線程用CAS更新這個volatile變量。
4)A線程用CAS更新一個volatile變量,随後B線程讀這個volatile變量。
Java的CAS會使用現代處理器上提供的高效機器級别的原子指令,這些原子指令以原子方式對記憶體執行讀-改-寫操作,這是在多處理器中實作同步的關鍵(從本質上來說,能夠支援原子性讀-改-寫指令的計算機,是順序計算圖靈機的異步等價機器,是以任何現代的多處理器都會去支援某種能對記憶體執行原子性讀-改-寫操作的原子指令)。同時,volatile變量的讀/寫和CAS可以實作線程之間的通信。把這些特性整合在一起,就形成了整個concurrent包得以實作的基石。如果我們仔細分析concurrent包的源代碼實作,會發現一個通用化的實作模式。
首先,聲明共享變量為volatile。
然後,使用CAS的原子條件更新來實作線程之間的同步。
同時,配合以volatile的讀/寫和CAS所具有的volatile讀和寫的記憶體語義來實作線程之間的通信。
AQS,非阻塞資料結構和原子變量類(java.util.concurrent.atomic包中的類),這些concurrent包中的基礎類都是使用這種模式來實作的,而concurrent包中的高層類又是依賴于這些基礎類來實作的。從整體來看,concurrent包的實作示意圖如3-28所示。
圖3-28 concurrent包的實作示意圖
3.6 final域的記憶體語義
與前面介紹的鎖和volatile相比,對final域的讀和寫更像是普通的變量通路。下面将介紹final域的記憶體語義。
3.6.1 final域的重排序規則
對于final域,編譯器和處理器要遵守兩個重排序規則。
1)在構造函數内對一個final域的寫入,與随後把這個被構造對象的引用指派給一個引用變量,這兩個操作之間不能重排序。
2)初次讀一個包含final域的對象的引用,與随後初次讀這個final域,這兩個操作之間不能重排序。
下面通過一些示例性的代碼來分别說明這兩個規則。
public class FinalExample {
int i; // 普通變量
final int j; // final變量
static FinalExample obj;
public FinalExample () { // 構造函數
i = 1; // 寫普通域
j = 2; // 寫final域
}
public static void writer () { // 寫線程A執行
obj = new FinalExample ();
}
public static void reader () { // 讀線程B執行
FinalExample object = obj; // 讀對象引用
int a = object.i; // 讀普通域
int b = object.j; // 讀final域
}
}
這裡假設一個線程A執行writer()方法,随後另一個線程B執行reader()方法。下面我們通過這兩個線程的互動來說明這兩個規則。
3.6.2 寫final域的重排序規則
寫final域的重排序規則禁止把final域的寫重排序到構造函數之外。這個規則的實作包含下面2個方面。
1)JMM禁止編譯器把final域的寫重排序到構造函數之外。
2)編譯器會在final域的寫之後,構造函數return之前,插入一個StoreStore屏障。這個屏障禁止處理器把final域的寫重排序到構造函數之外。
現在讓我們分析writer()方法。writer()方法隻包含一行代碼:finalExample=newFinalExample()。這行代碼包含兩個步驟,如下。
1)構造一個FinalExample類型的對象。
2)把這個對象的引用指派給引用變量obj。
假設線程B讀對象引用與讀對象的成員域之間沒有重排序(馬上會說明為什麼需要這個假設),圖3-29是一種可能的執行時序。
在圖3-29中,寫普通域的操作被編譯器重排序到了構造函數之外,讀線程B錯誤地讀取了普通變量i初始化之前的值。而寫final域的操作,被寫final域的重排序規則“限定”在了構造函數之内,讀線程B正确地讀取了final變量初始化之後的值。
寫final域的重排序規則可以確定:在對象引用為任意線程可見之前,對象的final域已經被正确初始化過了,而普通域不具有這個保障。以上圖為例,在讀線程B“看到”對象引用obj時,很可能obj對象還沒有構造完成(對普通域i的寫操作被重排序到構造函數外,此時初始值1還沒有寫入普通域i)。
圖3-29 線程執行時序圖
3.6.3 讀final域的重排序規則
讀final域的重排序規則是,在一個線程中,初次讀對象引用與初次讀該對象包含的final域,JMM禁止處理器重排序這兩個操作(注意,這個規則僅僅針對處理器)。編譯器會在讀final域操作的前面插入一個LoadLoad屏障。
初次讀對象引用與初次讀該對象包含的final域,這兩個操作之間存在間接依賴關系。由于編譯器遵守間接依賴關系,是以編譯器不會重排序這兩個操作。大多數處理器也會遵守間接依賴,也不會重排序這兩個操作。但有少數處理器允許對存在間接依賴關系的操作做重排序
(比如alpha處理器),這個規則就是專門用來針對這種處理器的。
reader()方法包含3個操作。
·初次讀引用變量obj。
·初次讀引用變量obj指向對象的普通域j。
·初次讀引用變量obj指向對象的final域i。
現在假設寫線程A沒有發生任何重排序,同時程式在不遵守間接依賴的處理器上執行,圖
3-30所示是一種可能的執行時序。
圖3-30 線程執行時序圖
在圖3-30中,讀對象的普通域的操作被處理器重排序到讀對象引用之前。讀普通域時,該域還沒有被寫線程A寫入,這是一個錯誤的讀取操作。而讀final域的重排序規則會把讀對象final域的操作“限定”在讀對象引用之後,此時該final域已經被A線程初始化過了,這是一個正确的讀取操作。
讀final域的重排序規則可以確定:在讀一個對象的final域之前,一定會先讀包含這個final域的對象的引用。在這個示例程式中,如果該引用不為null,那麼引用對象的final域一定已經被A線程初始化過了。
3.6.4 final域為引用類型
上面我們看到的final域是基礎資料類型,如果final域是引用類型,将會有什麼效果?請看下列示例代碼。
public class FinalReferenceExample {
final int[] intArray; // final是引用類型
static FinalReferenceExample obj;
public FinalReferenceExample () { // 構造函數
intArray = new int[1]; // 1
intArray[0] = 1; // 2
}
public static void writerOne () { // 寫線程A執行
obj = new FinalReferenceExample (); // 3
}
public static void writerTwo () { // 寫線程B執行
obj.intArray[0] = 2; // 4
}
public static void reader () { // 讀線程C執行
if (obj != null) { // 5
int temp1 = obj.intArray[0]; // 6
}
}
}
本例final域為一個引用類型,它引用一個int型的數組對象。對于引用類型,寫final域的重排序規則對編譯器和處理器增加了如下限制:在構造函數内對一個final引用的對象的成員域的寫入,與随後在構造函數外把這個被構造對象的引用指派給一個引用變量,這兩個操作之間不能重排序。
對上面的示例程式,假設首先線程A執行writerOne()方法,執行完後線程B執行writerTwo()方法,執行完後線程C執行reader()方法。圖3-31是一種可能的線程執行時序。
圖3-31 引用型final的執行時序圖
在圖3-31中,1是對final域的寫入,2是對這個final域引用的對象的成員域的寫入,3是把被構造的對象的引用指派給某個引用變量。這裡除了前面提到的1不能和3重排序外,2和3也不能重排序。
JMM可以確定讀線程C至少能看到寫線程A在構造函數中對final引用對象的成員域的寫入。即C至少能看到數組下标0的值為1。而寫線程B對數組元素的寫入,讀線程C可能看得到,也可能看不到。JMM不保證線程B的寫入對讀線程C可見,因為寫線程B和讀線程C之間存在資料競争,此時的執行結果不可預知。
如果想要確定讀線程C看到寫線程B對數組元素的寫入,寫線程B和讀線程C之間需要使用同步原語(lock或volatile)來確定記憶體可見性。
3.6.5 為什麼final引用不能從構造函數内“溢出”
前面我們提到過,寫final域的重排序規則可以確定:在引用變量為任意線程可見之前,該引用變量指向的對象的final域已經在構造函數中被正确初始化過了。其實,要得到這個效果,
還需要一個保證:在構造函數内部,不能讓這個被構造對象的引用為其他線程所見,也就是對象引用不能在構造函數中“逸出”。為了說明問題,讓我們來看下面的示例代碼。
public class FinalReferenceEscapeExample {
final int i;
static FinalReferenceEscapeExample obj;
public FinalReferenceEscapeExample () {
i = 1; // 1寫final域
obj = this; // 2 this引用在此"逸出"
}
public static void writer() {
new FinalReferenceEscapeExample ();
}
public static void reader() {
if (obj != null) { // 3
int temp = obj.i; // 4
}
}
}
假設一個線程A執行writer()方法,另一個線程B執行reader()方法。這裡的操作2使得對象還未完成構造前就為線程B可見。即使這裡的操作2是構造函數的最後一步,且在程式中操作2排在操作1後面,執行read()方法的線程仍然可能無法看到final域被初始化後的值,因為這裡的操作1和操作2之間可能被重排序。實際的執行時序可能如圖3-32所示。
圖3-32 多線程執行時序圖
從圖3-32可以看出:在構造函數傳回前,被構造對象的引用不能為其他線程所見,因為此時的final域可能還沒有被初始化。在構造函數傳回後,任意線程都将保證能看到final域正确初始化之後的值。
3.6.6 final語義在處理器中的實作
現在我們以X86處理器為例,說明final語義在處理器中的具體實作。
上面我們提到,寫final域的重排序規則會要求編譯器在final域的寫之後,構造函數return之前插入一個StoreStore障屏。讀final域的重排序規則要求編譯器在讀final域的操作前面插入一個LoadLoad屏障。
由于X86處理器不會對寫-寫操作做重排序,是以在X86處理器中,寫final域需要的StoreStore障屏會被省略掉。同樣,由于X86處理器不會對存在間接依賴關系的操作做重排序,是以在X86處理器中,讀final域需要的LoadLoad屏障也會被省略掉。也就是說,在X86處理器中,final域的讀/寫不會插入任何記憶體屏障!
3.6.7 JSR-133為什麼要增強final的語義
在舊的Java記憶體模型中,一個最嚴重的缺陷就是線程可能看到final域的值會改變。比如,
一個線程目前看到一個整型final域的值為0(還未初始化之前的預設值),過一段時間之後這個線程再去讀這個final域的值時,卻發現值變為1(被某個線程初始化之後的值)。最常見的例子就是在舊的Java記憶體模型中,String的值可能會改變。
為了修補這個漏洞,JSR-133專家組增強了final的語義。通過為final域增加寫和讀重排序規則,可以為Java程式員提供初始化安全保證:隻要對象是正确構造的(被構造對象的引用在構造函數中沒有“逸出”),那麼不需要使用同步(指lock和volatile的使用)就可以保證任意線程都能看到這個final域在構造函數中被初始化之後的值。
3.7 happens-before
happens-before是JMM最核心的概念。對應Java程式員來說,了解happens-before是了解JMM的關鍵。
3.7.1 JMM的設計
首先,讓我們來看JMM的設計意圖。從JMM設計者的角度,在設計JMM時,需要考慮兩個關鍵因素。
·程式員對記憶體模型的使用。程式員希望記憶體模型易于了解、易于程式設計。程式員希望基于一個強記憶體模型來編寫代碼。
·編譯器和處理器對記憶體模型的實作。編譯器和處理器希望記憶體模型對它們的束縛越少越好,這樣它們就可以做盡可能多的優化來提高性能。編譯器和處理器希望實作一個弱記憶體模型。
由于這兩個因素互相沖突,是以JSR-133專家組在設計JMM時的核心目标就是找到一個好的平衡點:一方面,要為程式員提供足夠強的記憶體可見性保證;另一方面,對編譯器和處理器的限制要盡可能地放松。下面讓我們來看JSR-133是如何實作這一目标的。
double pi = 3.14; // A
double r = 1.0; // B
double area = pi * r * r; // C
上面計算圓的面積的示例代碼存在3個happens-before關系,如下。
·A happens-before B。
·B happens-before C。
·A happens-before C。
在3個happens-before關系中,B和C是必需的,但A是不必要的。是以,JMM把happens-before要求禁止的重排序分為了下面兩類。
·會改變程式執行結果的重排序。
·不會改變程式執行結果的重排序。
JMM對這兩種不同性質的重排序,采取了不同的政策,如下。
·對于會改變程式執行結果的重排序,JMM要求編譯器和處理器必須禁止這種重排序。
·對于不會改變程式執行結果的重排序,JMM對編譯器和處理器不做要求(JMM允許這種重排序)。
圖3-33是JMM的設計示意圖。
圖3-33 JMM的設計示意圖
從圖3-33可以看出兩點,如下。
·JMM向程式員提供的happens-before規則能滿足程式員的需求。JMM的happens-before規則不但簡單易懂,而且也向程式員提供了足夠強的記憶體可見性保證(有些記憶體可見性保證其實并不一定真實存在,比如上面的A happens-before B)。
·JMM對編譯器和處理器的束縛已經盡可能少。從上面的分析可以看出,JMM其實是在遵循一個基本原則:隻要不改變程式的執行結果(指的是單線程程式和正确同步的多線程程式),編譯器和處理器怎麼優化都行。例如,如果編譯器經過細緻的分析後,認定一個鎖隻會被單個線程通路,那麼這個鎖可以被消除。再如,如果編譯器經過細緻的分析後,認定一個volatile變量隻會被單個線程通路,那麼編譯器可以把這個volatile變量當作一個普通變量來對待。這些優化既不會改變程式的執行結果,又能提高程式的執行效率。
3.7.2 happens-before的定義
happens-before的概念最初由Leslie Lamport在其一篇影響深遠的論文(《Time,Clocks and the Ordering of Events in a Distributed System》)中提出。Leslie Lamport使用happens-before來定義分布式系統中事件之間的偏序關系(partial ordering)。Leslie Lamport在這篇論文中給出了一個分布式算法,該算法可以将該偏序關系擴充為某種全序關系。
JSR-133使用happens-before的概念來指定兩個操作之間的執行順序。由于這兩個操作可以在一個線程之内,也可以是在不同線程之間。是以,JMM可以通過happens-before關系向程式員提供跨線程的記憶體可見性保證(如果A線程的寫操作a與B線程的讀操作b之間存在happens-before關系,盡管a操作和b操作在不同的線程中執行,但JMM向程式員保證a操作将對b操作可見)。
《JSR-133:Java Memory Model and Thread Specification》對happens-before關系的定義如下。
1)如果一個操作happens-before另一個操作,那麼第一個操作的執行結果将對第二個操作可見,而且第一個操作的執行順序排在第二個操作之前。
2)兩個操作之間存在happens-before關系,并不意味着Java平台的具體實作必須要按照happens-before關系指定的順序來執行。如果重排序之後的執行結果,與按happens-before關系來執行的結果一緻,那麼這種重排序并不非法(也就是說,JMM允許這種重排序)。
上面的1)是JMM對程式員的承諾。從程式員的角度來說,可以這樣了解happens-before關系:如果A happens-before B,那麼Java記憶體模型将向程式員保證——A操作的結果将對B可見,且A的執行順序排在B之前。注意,這隻是Java記憶體模型向程式員做出的保證!
上面的2)是JMM對編譯器和處理器重排序的限制原則。正如前面所言,JMM其實是在遵循一個基本原則:隻要不改變程式的執行結果(指的是單線程程式和正确同步的多線程程式),編譯器和處理器怎麼優化都行。JMM這麼做的原因是:程式員對于這兩個操作是否真的被重排序并不關心,程式員關心的是程式執行時的語義不能被改變(即執行結果不能被改變)。是以,happens-before關系本質上和as-if-serial語義是一回事。
·as-if-serial語義保證單線程内程式的執行結果不被改變,happens-before關系保證正确同步的多線程程式的執行結果不被改變。
·as-if-serial語義給編寫單線程程式的程式員創造了一個幻境:單線程程式是按程式的順序來執行的。happens-before關系給編寫正确同步的多線程程式的程式員創造了一個幻境:正确同步的多線程程式是按happens-before指定的順序來執行的。
as-if-serial語義和happens-before這麼做的目的,都是為了在不改變程式執行結果的前提下,盡可能地提高程式執行的并行度。
3.7.3 happens-before規則
《JSR-133:Java Memory Model and Thread Specification》定義了如下happens-before規則。
1)程式順序規則:一個線程中的每個操作,happens-before于該線程中的任意後續操作。
2)螢幕鎖規則:對一個鎖的解鎖,happens-before于随後對這個鎖的加鎖。
3)volatile變量規則:對一個volatile域的寫,happens-before于任意後續對這個volatile域的讀。
4)傳遞性:如果A happens-before B,且B happens-before C,那麼A happens-before C。
5)start()規則:如果線程A執行操作ThreadB.start()(啟動線程B),那麼A線程的ThreadB.start()操作happens-before于線程B中的任意操作。
6)join()規則:如果線程A執行操作ThreadB.join()并成功傳回,那麼線程B中的任意操作
happens-before于線程A從ThreadB.join()操作成功傳回。
這裡的規則1)、2)、3)和4)前面都講到過,這裡再做個總結。由于2)和3)情況類似,這裡隻以1)、3)和4)為例來說明。圖3-34是volatile寫-讀建立的happens-before關系圖。
圖3-34 happens-before關系的示意圖
結合圖3-34,我們做以下分析。
·1 happens-before 2和3 happens-before 4由程式順序規則産生。由于編譯器和處理器都要遵守as-if-serial語義,也就是說,as-if-serial語義保證了程式順序規則。是以,可以把程式順序規則看成是對as-if-serial語義的“封裝”。
·2 happens-before 3是由volatile規則産生。前面提到過,對一個volatile變量的讀,總是能看到(任意線程)之前對這個volatile變量最後的寫入。是以,volatile的這個特性可以保證實作volatile規則。
·1 happens-before 4是由傳遞性規則産生的。這裡的傳遞性是由volatile的記憶體屏障插入政策和volatile的編譯器重排序規則共同來保證的。
下面我們來看start()規則。假設線程A在執行的過程中,通過執行ThreadB.start()來啟動線程B;同時,假設線程A在執行ThreadB.start()之前修改了一些共享變量,線程B在開始執行後會讀這些共享變量。圖3-35是該程式對應的happens-before關系圖。
圖3-35 happens-before關系的示意圖
在圖3-35中,1 happens-before 2由程式順序規則産生。2 happens-before 4由start()規則産生。根據傳遞性,将有1 happens-before 4。這實意味着,線程A在執行ThreadB.start()之前對共享變量所做的修改,接下來線上程B開始執行後都将確定對線程B可見。
下面我們來看join()規則。假設線程A在執行的過程中,通過執行ThreadB.join()來等待線程B終止;同時,假設線程B在終止之前修改了一些共享變量,線程A從ThreadB.join()傳回後會讀這些共享變量。圖3-36是該程式對應的happens-before關系圖。
圖3-36 happens-before關系的示意圖
在圖3-36中,2 happens-before 4由join()規則産生;4 happens-before 5由程式順序規則産生。根據傳遞性規則,将有2 happens-before 5。這意味着,線程A執行操作ThreadB.join()并成功傳回後,線程B中的任意操作都将對線程A可見。
3.8 雙重檢查鎖定與延遲初始化
在Java多線程程式中,有時候需要采用延遲初始化來降低初始化類和建立對象的開銷。雙重檢查鎖定是常見的延遲初始化技術,但它是一個錯誤的用法。本文将分析雙重檢查鎖定的錯誤根源,以及兩種線程安全的延遲初始化方案。
3.8.1 雙重檢查鎖定的由來
在Java程式中,有時候可能需要推遲一些高開銷的對象初始化操作,并且隻有在使用這些對象時才進行初始化。此時,程式員可能會采用延遲初始化。但要正确實作線程安全的延遲初始化需要一些技巧,否則很容易出現問題。比如,下面是非線程安全的延遲初始化對象的示例代碼。
public class UnsafeLazyInitialization {
private static Instance instance;
public static Instance getInstance() {
if (instance == null) // 1:A線程執行
instance = new Instance(); // 2:B線程執行
return instance;
}
}
在UnsafeLazyInitialization類中,假設A線程執行代碼1的同時,B線程執行代碼2。此時,線程A可能會看到instance引用的對象還沒有完成初始化(出現這種情況的原因見3.8.2節)。
對于UnsafeLazyInitialization類,我們可以對getInstance()方法做同步處理來實作線程安全的延遲初始化。示例代碼如下。
public class SafeLazyInitialization {
private static Instance instance;
public synchronized static Instance getInstance() {
if (instance == null)
instance = new Instance();
return instance;
}
}
由于對getInstance()方法做了同步處理,synchronized将導緻性能開銷。如果getInstance()方法被多個線程頻繁的調用,将會導緻程式執行性能的下降。反之,如果getInstance()方法不會被多個線程頻繁的調用,那麼這個延遲初始化方案将能提供令人滿意的性能。
在早期的JVM中,synchronized(甚至是無競争的synchronized)存在巨大的性能開銷。是以,人們想出了一個“聰明”的技巧:雙重檢查鎖定(Double-Checked Locking)。人們想通過雙重檢查鎖定來降低同步的開銷。下面是使用雙重檢查鎖定來實作延遲初始化的示例代碼。
public class DoubleCheckedLocking { // 1
private static Instance instance; // 2
public static Instance getInstance() { // 3
if (instance == null) { // 4:第一次檢查
synchronized (DoubleCheckedLocking.class) { // 5:加鎖
if (instance == null) // 6:第二次檢查
instance = new Instance(); // 7:問題的根源出在這裡
} // 8
} // 9
return instance; // 10
} // 11
}
如上面代碼所示,如果第一次檢查instance不為null,那麼就不需要執行下面的加鎖和初始化操作。是以,可以大幅降低synchronized帶來的性能開銷。上面代碼表面上看起來,似乎兩全其美。
·多個線程試圖在同一時間建立對象時,會通過加鎖來保證隻有一個線程能建立對象。
·在對象建立好之後,執行getInstance()方法将不需要擷取鎖,直接傳回已建立好的對象。
雙重檢查鎖定看起來似乎很完美,但這是一個錯誤的優化!線上程執行到第4行,代碼讀取到instance不為null時,instance引用的對象有可能還沒有完成初始化。
3.8.2 問題的根源
前面的雙重檢查鎖定示例代碼的第7行(instance=new Singleton();)建立了一個對象。這一行代碼可以分解為如下的3行僞代碼。
memory = allocate(); // 1:配置設定對象的記憶體空間
ctorInstance(memory); // 2:初始化對象
instance = memory; // 3:設定instance指向剛配置設定的記憶體位址
上面3行僞代碼中的2和3之間,可能會被重排序(在一些JIT編譯器上,這種重排序是真實發生的,詳情見參考文獻1的“Out-of-order writes”部分)。2和3之間重排序之後的執行時序如下。
memory = allocate(); // 1:配置設定對象的記憶體空間
instance = memory; // 3:設定instance指向剛配置設定的記憶體位址
// 注意,此時對象還沒有被初始化!
ctorInstance(memory); // 2:初始化對象
根據《The Java Language Specification,Java SE 7 Edition》(後文簡稱為Java語言規範),所有線程在執行Java程式時必須要遵守intra-thread semantics。intra-thread semantics保證重排序不會改變單線程内的程式執行結果。換句話說,intra-thread semantics允許那些在單線程内,不會改變單線程程式執行結果的重排序。上面3行僞代碼的2和3之間雖然被重排序了,但這個重排序并不會違反intra-thread semantics。這個重排序在沒有改變單線程程式執行結果的前提下,可以提高程式的執行性能。
為了更好地了解intra-thread semantics,請看如圖3-37所示的示意圖(假設一個線程A在構造對象後,立即通路這個對象)。
如圖3-37所示,隻要保證2排在4的前面,即使2和3之間重排序了,也不會違反intra-threadsemantics。
下面,再讓我們檢視多線程并發執行的情況。如圖3-38所示。
圖3-37 線程執行時序圖
圖3-38 多線程執行時序圖
由于單線程内要遵守intra-thread semantics,進而能保證A線程的執行結果不會被改變。但是,當線程A和B按圖3-38的時序執行時,B線程将看到一個還沒有被初始化的對象。
回到本文的主題,DoubleCheckedLocking示例代碼的第7行(instance=new Singleton();)如果發生重排序,另一個并發執行的線程B就有可能在第4行判斷instance不為null。線程B接下來将通路instance所引用的對象,但此時這個對象可能還沒有被A線程初始化!表3-6是這個場景的具體執行時序。
表3-6 多線程執行時序表
這裡A2和A3雖然重排序了,但Java記憶體模型的intra-thread semantics将確定A2一定會排在A4前面執行。是以,線程A的intra-thread semantics沒有改變,但A2和A3的重排序,将導緻線程B在B1處判斷出instance不為空,線程B接下來将通路instance引用的對象。此時,線程B将會通路到一個還未初始化的對象。
在知曉了問題發生的根源之後,我們可以想出兩個辦法來實作線程安全的延遲初始化。
1)不允許2和3重排序。
2)允許2和3重排序,但不允許其他線程“看到”這個重排序。
後文介紹的兩個解決方案,分别對應于上面這兩點。
3.8.3 基于volatile的解決方案
對于前面的基于雙重檢查鎖定來實作延遲初始化的方案(指DoubleCheckedLocking示例代碼),隻需要做一點小的修改(把instance聲明為volatile型),就可以實作線程安全的延遲初始化。請看下面的示例代碼。
public class SafeDoubleCheckedLocking {
private volatile static Instance instance;
public static Instance getInstance() {
if (instance == null) {
synchronized (SafeDoubleCheckedLocking.class) {
if (instance == null){
instance = new Instance();//instance為volatile,現在沒問題了
}
}
}
return instance;
}
}
注意 這個解決方案需要JDK 5或更高版本(因為從JDK 5開始使用新的JSR-133記憶體模型規範,這個規範增強了volatile的語義)。
當聲明對象的引用為volatile後,3.8.2節中的3行僞代碼中的2和3之間的重排序,在多線程環境中将會被禁止。上面示例代碼将按如下的時序執行,如圖3-39所示。
圖3-39 多線程執行時序圖
這個方案本質上是通過禁止圖3-39中的2和3之間的重排序,來保證線程安全的延遲初始化。
3.8.4 基于類初始化的解決方案
JVM在類的初始化階段(即在Class被加載後,且被線程使用之前),會執行類的初始化。在執行類的初始化期間,JVM會去擷取一個鎖。這個鎖可以同步多個線程對同一個類的初始化。
基于這個特性,可以實作另一種線程安全的延遲初始化方案(這個方案被稱之為Initialization On Demand Holder idiom)。
public class InstanceFactory {
private static class InstanceHolder {
public static Instance instance = new Instance();
}
public static Instance getInstance() {
return InstanceHolder.instance ;// 這裡将導緻InstanceHolder類被初始化
}
}
假設兩個線程并發執行getInstance()方法,下面是執行的示意圖,如圖3-40所示。
圖3-40 兩個線程并發執行的示意圖
這個方案的實質是:允許3.8.2節中的3行僞代碼中的2和3重排序,但不允許非構造線程(這裡指線程B)“看到”這個重排序。
初始化一個類,包括執行這個類的靜态初始化和初始化在這個類中聲明的靜态字段。根據Java語言規範,在首次發生下列任意一種情況時,一個類或接口類型T将被立即初始化。
1)T是一個類,而且一個T類型的執行個體被建立。
2)T是一個類,且T中聲明的一個靜态方法被調用。
3)T中聲明的一個靜态字段被指派。
4)T中聲明的一個靜态字段被使用,而且這個字段不是一個常量字段。
5)T是一個頂級類(Top Level Class,見Java語言規範的§7.6),而且一個斷言語句嵌套在T内部被執行。
在InstanceFactory示例代碼中,首次執行getInstance()方法的線程将導緻InstanceHolder類被初始化(符合情況4)。
由于Java語言是多線程的,多個線程可能在同一時間嘗試去初始化同一個類或接口(比如這裡多個線程可能在同一時刻調用getInstance()方法來初始化InstanceHolder類)。是以,在Java中初始化一個類或者接口時,需要做細緻的同步處理。
Java語言規範規定,對于每一個類或接口C,都有一個唯一的初始化鎖LC與之對應。從C到LC的映射,由JVM的具體實作去自由實作。JVM在類初始化期間會擷取這個初始化鎖,并且每個線程至少擷取一次鎖來確定這個類已經被初始化過了(事實上,Java語言規範允許JVM的具體實作在這裡做一些優化,見後文的說明)。
對于類或接口的初始化,Java語言規範制定了精巧而複雜的類初始化處理過程。Java初始化一個類或接口的處理過程如下(這裡對類初始化處理過程的說明,省略了與本文無關的部分;同時為了更好的說明類初始化過程中的同步處理機制,筆者人為的把類初始化的處理過程分為了5個階段)。
第1階段:通過在Class對象上同步(即擷取Class對象的初始化鎖),來控制類或接口的初始化。這個擷取鎖的線程會一直等待,直到目前線程能夠擷取到這個初始化鎖。
假設Class對象目前還沒有被初始化(初始化狀态state,此時被标記為state=noInitialization),且有兩個線程A和B試圖同時初始化這個Class對象。圖3-41是對應的示意圖。
圖3-41 類初始化——第1階段
表3-7是這個示意圖的說明。
表3-7 類初始化——第1階段的執行時序表
第2階段:線程A執行類的初始化,同時線程B在初始化鎖對應的condition上等待。
表3-8是這個示意圖的說明。
表3-8 類初始化——第2階段的執行時序表
圖3-42 類初始化——第2階段
第3階段:線程A設定state=initialized,然後喚醒在condition中等待的所有線程。
圖3-43 類初始化——第3階段
表3-9是這個示意圖的說明。
表3-9 類初始化——第3階段的執行時序表
第4階段:線程B結束類的初始化處理。
圖3-44 類初始化——第4階段
表3-10是這個示意圖的說明。
表3-10 類初始化——第4階段的執行時序表
圖3-45 多線程執行時序圖
線程A在第2階段的A1執行類的初始化,并在第3階段的A4釋放初始化鎖;線程B在第4階段的B1擷取同一個初始化鎖,并在第4階段的B4之後才開始通路這個類。根據Java記憶體模型規範的鎖規則,這裡将存在如下的happens-before關系。
這個happens-before關系将保證:線程A執行類的初始化時的寫入操作(執行類的靜态初始化和初始化類中聲明的靜态字段),線程B一定能看到。
第5階段:線程C執行類的初始化的處理。
圖3-46 類初始化——第5階段
表3-11是這個示意圖的說明。
表3-11 類初始化——第5階段的執行時序表
在第3階段之後,類已經完成了初始化。是以線程C在第5階段的類初始化處理過程相對簡單一些(前面的線程A和B的類初始化處理過程都經曆了兩次鎖擷取-鎖釋放,而線程C的類初始化處理隻需要經曆一次鎖擷取-鎖釋放)。
線程A在第2階段的A1執行類的初始化,并在第3階段的A4釋放鎖;線程C在第5階段的C1擷取同一個鎖,并在在第5階段的C4之後才開始通路這個類。根據Java記憶體模型規範的鎖規則,将存在如下的happens-before關系。
這個happens-before關系将保證:線程A執行類的初始化時的寫入操作,線程C一定能看到。
注意 這裡的condition和state标記是本文虛構出來的。Java語言規範并沒有硬性規定一定要使用condition和state标記。JVM的具體實作隻要實作類似功能即可。
注意 Java語言規範允許Java的具體實作,優化類的初始化處理過程(對這裡的第5階段做優化),具體細節參見Java語言規範的12.4.2節。
圖3-47 多線程執行時序圖
通過對比基于volatile的雙重檢查鎖定的方案和基于類初始化的方案,我們會發現基于類初始化的方案的實作代碼更簡潔。但基于volatile的雙重檢查鎖定的方案有一個額外的優勢:除了可以對靜态字段實作延遲初始化外,還可以對執行個體字段實作延遲初始化。
字段延遲初始化降低了初始化類或建立執行個體的開銷,但增加了通路被延遲初始化的字段的開銷。在大多數時候,正常的初始化要優于延遲初始化。如果确實需要對執行個體字段使用線程安全的延遲初始化,請使用上面介紹的基于volatile的延遲初始化的方案;如果确實需要對靜态字段使用線程安全的延遲初始化,請使用上面介紹的基于類初始化的方案。
3.9 Java記憶體模型綜述
前面對Java記憶體模型的基礎知識和記憶體模型的具體實作進行了說明。下面對Java記憶體模型的相關知識做一個總結。
3.9.1 處理器的記憶體模型
順序一緻性記憶體模型是一個理論參考模型,JMM和處理器記憶體模型在設計時通常會以順序一緻性記憶體模型為參照。在設計時,JMM和處理器記憶體模型會對順序一緻性模型做一些放松,因為如果完全按照順序一緻性模型來實作處理器和JMM,那麼很多的處理器和編譯器優化都要被禁止,這對執行性能将會有很大的影響。
根據對不同類型的讀/寫操作組合的執行順序的放松,可以把常見處理器的記憶體模型劃分為如下幾種類型。
·放松程式中寫-讀操作的順序,由此産生了Total Store Ordering記憶體模型(簡稱為TSO)。
·在上面的基礎上,繼續放松程式中寫-寫操作的順序,由此産生了Partial Store Order記憶體模型(簡稱為PSO)。
·在前面兩條的基礎上,繼續放松程式中讀-寫和讀-讀操作的順序,由此産生了Relaxed Memory Order記憶體模型(簡稱為RMO)和PowerPC記憶體模型。
注意,這裡處理器對讀/寫操作的放松,是以兩個操作之間不存在資料依賴性為前提的(因為處理器要遵守as-if-serial語義,處理器不會對存在資料依賴性的兩個記憶體操作做重排序)。
表3-12展示了常見處理器記憶體模型的細節特征如下。
表3-12 處理器記憶體模型的特征表
從表3-12中可以看到,所有處理器記憶體模型都允許寫-讀重排序,原因在第1章已經說明過:它們都使用了寫緩存區。寫緩存區可能導緻寫-讀操作重排序。同時,我們可以看到這些處理器記憶體模型都允許更早讀到目前處理器的寫,原因同樣是因為寫緩存區。由于寫緩存區僅對目前處理器可見,這個特性導緻目前處理器可以比其他處理器先看到臨時儲存在自己寫緩存區中的寫。
表3-12中的各種處理器記憶體模型,從上到下,模型由強變弱。越是追求性能的處理器,記憶體模型設計得會越弱。因為這些處理器希望記憶體模型對它們的束縛越少越好,這樣它們就可以做盡可能多的優化來提高性能。
由于常見的處理器記憶體模型比JMM要弱,Java編譯器在生成位元組碼時,會在執行指令序列的适當位置插入記憶體屏障來限制處理器的重排序。同時,由于各種處理器記憶體模型的強弱不同,為了在不同的處理器平台向程式員展示一個一緻的記憶體模型,JMM在不同的處理器中需要插入的記憶體屏障的數量和種類也不相同。圖3-48展示了JMM在不同處理器記憶體模型中需要插入的記憶體屏障的示意圖。
JMM屏蔽了不同處理器記憶體模型的差異,它在不同的處理器平台之上為Java程式員呈現了一個一緻的記憶體模型。
圖3-48 JMM插入記憶體屏障的示意圖
3.9.2 各種記憶體模型之間的關系
JMM是一個語言級的記憶體模型,處理器記憶體模型是硬體級的記憶體模型,順序一緻性記憶體模型是一個理論參考模型。下面是語言記憶體模型、處理器記憶體模型和順序一緻性記憶體模型的強弱對比示意圖,如圖3-49所示。
圖3-49 各種CPU記憶體模型的強弱對比示意圖
從圖中可以看出:常見的4種處理器記憶體模型比常用的3中語言記憶體模型要弱,處理器記憶體模型和語言記憶體模型都比順序一緻性記憶體模型要弱。同處理器記憶體模型一樣,越是追求執行性能的語言,記憶體模型設計得會越弱。
3.9.3 JMM的記憶體可見性保證
按程式類型,Java程式的記憶體可見性保證可以分為下列3類。
·單線程程式。單線程程式不會出現記憶體可見性問題。編譯器、runtime和處理器會共同確定單線程程式的執行結果與該程式在順序一緻性模型中的執行結果相同。
·正确同步的多線程程式。正确同步的多線程程式的執行将具有順序一緻性(程式的執行結果與該程式在順序一緻性記憶體模型中的執行結果相同)。這是JMM關注的重點,JMM通過限制編譯器和處理器的重排序來為程式員提供記憶體可見性保證。
·未同步/未正确同步的多線程程式。JMM為它們提供了最小安全性保障:線程執行時讀取到的值,要麼是之前某個線程寫入的值,要麼是預設值(0、null、false)。
注意,最小安全性保障與64位資料的非原子性寫并不沖突。它們是兩個不同的概念,它們“發生”的時間點也不同。最小安全性保證對象預設初始化之後(設定成員域為0、null或false),才會被任意線程使用。最小安全性“發生”在對象被任意線程使用之前。64位資料的非原子性寫“發生”在對象被多個線程使用的過程中(寫共享變量)。當發生問題時(處理器B看到僅僅被處理器A“寫了一半”的無效值),這裡雖然處理器B讀取到一個被寫了一半的無效值,但這個值仍然是處理器A寫入的,隻不過是處理器A還沒有寫完而已。最小安全性保證線程讀取到的值,要麼是之前某個線程寫入的值,要麼是預設值(0、null、false)。但最小安全性并不保證線程讀取到的值,一定是某個線程寫完後的值。最小安全性保證線程讀取到的值不會無中生有的冒出來,但并不保證線程讀取到的值一定是正确的。
圖3-50展示了這3類程式在JMM中與在順序一緻性記憶體模型中的執行結果的異同。
圖3-50 3類程式的執行結果的對比圖
隻要多線程程式是正确同步的,JMM保證該程式在任意的處理器平台上的執行結果,與該程式在順序一緻性記憶體模型中的執行結果一緻。
3.9.4 JSR-133對舊記憶體模型的修補
JSR-133對JDK 5之前的舊記憶體模型的修補主要有兩個。
·增強volatile的記憶體語義。舊記憶體模型允許volatile變量與普通變量重排序。JSR-133嚴格限制volatile變量與普通變量的重排序,使volatile的寫-讀和鎖的釋放-擷取具有相同的記憶體語義。
·增強final的記憶體語義。在舊記憶體模型中,多次讀取同一個final變量的值可能會不相同。為此,JSR-133為final增加了兩個重排序規則。在保證final引用不會從構造函數内逸出的情況下,final具有了初始化安全性。
3.10 本章小結
本章對Java記憶體模型做了比較全面的解讀。希望讀者閱讀本章之後,對Java記憶體模型能夠有一個比較深入的了解;同時,也希望本章可幫助讀者解決在Java并發程式設計中經常遇到的各種記憶體可見性問題。