文章目錄
-
- 1. JAVA虛拟機的記憶體劃分
- 2.HotSpot虛拟機的對象建立過程
- 3.記憶體溢出實踐
- 4.JAVA垃圾收集器
- 5.記憶體的配置設定政策
這幾天主要在學習java虛拟機的相關知識,在此談談自己的心得體會,如有不對之處,希望各位多多指出,謝謝。本次心得主要參考了《深入了解java虛拟機》第二和三章内容,也算是學習的一個總結。
1. JAVA虛拟機的記憶體劃分
在之前java的學習過程中,我也接觸過java記憶體配置設定的一些知識,看過一些博文,但是沒有系統的總結和劃分。這次借着學習java虛拟機的機會,正好做一次完整的總結。java程式執行的過程中,虛拟機會把記憶體主要劃分為以下幾個 部分:
1.程式計數器
2.虛拟機棧
3.本地方法棧
4.堆記憶體
5.方法區
其中,1,2,3為線程隔離的資料區,4,5為線程共享的資料區。那麼什麼是線程隔離呢,實際上就是每個線程都自己獨立建立了一塊資料區,獨立存儲相關資料,互不影響。就比如與别人合租,你的卧室就是你自己獨有的,而客廳則是共享。下面,我對每個區域的功能進行簡短的總結:
程式計數器: 用來存放目前線程所執行位元組碼的行号,此區域沒有規定任何記憶體溢出的情況。
虛拟機棧: 描述java方法執行的記憶體模型。随着方法的調用和執行,此區域會建立棧幀,進行入棧和出棧操作。并且棧幀大小在 編譯期就已經知道了。每個棧幀中存儲了局部變量表,操作數棧,動态連結,方法出口等資訊。其中,局部變量表存放了基本資料類型,對象的引用以及returnAddress類型。一般來說,當線程請求的區域過大時,會出現StackOverflowError異常,當無法擴充時,則會出現OutOfMemoryError異常。
本地方法棧: 與虛拟機棧結構一緻,隻是用來存放Native方法的,在目前我們使用的HotSpot虛拟機中,這兩個區域合二為一。
堆記憶體: 該區域就是用來存放對象執行個體的。也是垃圾回收的主要區域。目前使用的收集器是采用分代收集算法的,是以,我們可以将該區域劃分為新生代和老年代,并且新生代裡面可以劃分Eden,From Survivor和To Survivor區。這些概念在後面會被提及,大家先了解下即可,該區域記憶體不足時,會出現OutOfMemoryError異常。
方法區 該區域用來存放類資訊,常量以及靜态變量。該區域可以選擇不實作垃圾收集。該區域收集的主要目标也僅僅隻是常量池的回收以及類型的解除安裝。該區域一樣會出現OutOfMemoryError異常。
在方法區中有一個重要的部分就是運作時常量池,這塊區域主要是用來存放符号以及字面量的引用。
直接記憶體 該區域不是虛拟機運作時的資料區。JDK1.4中,NIO類的DirectBuffer對象存儲的資料不在存儲在堆記憶體中,而是存儲在計算機的實體記憶體中,但是該區域會受到本機記憶體的限制,也會出現OutOfMemoryError異常。
2.HotSpot虛拟機的對象建立過程
目前我們學習所使用的虛拟機為HotSpot,在這裡,我們以該虛拟機的對象建立過程為例子,對上面的記憶體區域各有一些了解。
public class Test1 {
public static int a=2; //靜态變量存儲在方法區中
public static void main(String[] args) {
String s="我愛學JAVA,哈哈哈"; // 該字元串為字面量,是以其引用放在常量池中。
int b =3; //基本資料類型,3直接放在局部變量表上
Test1 t =new Test1(); //放在堆中,本節重點以此為例,講述下,new的對象建立過程
}
}
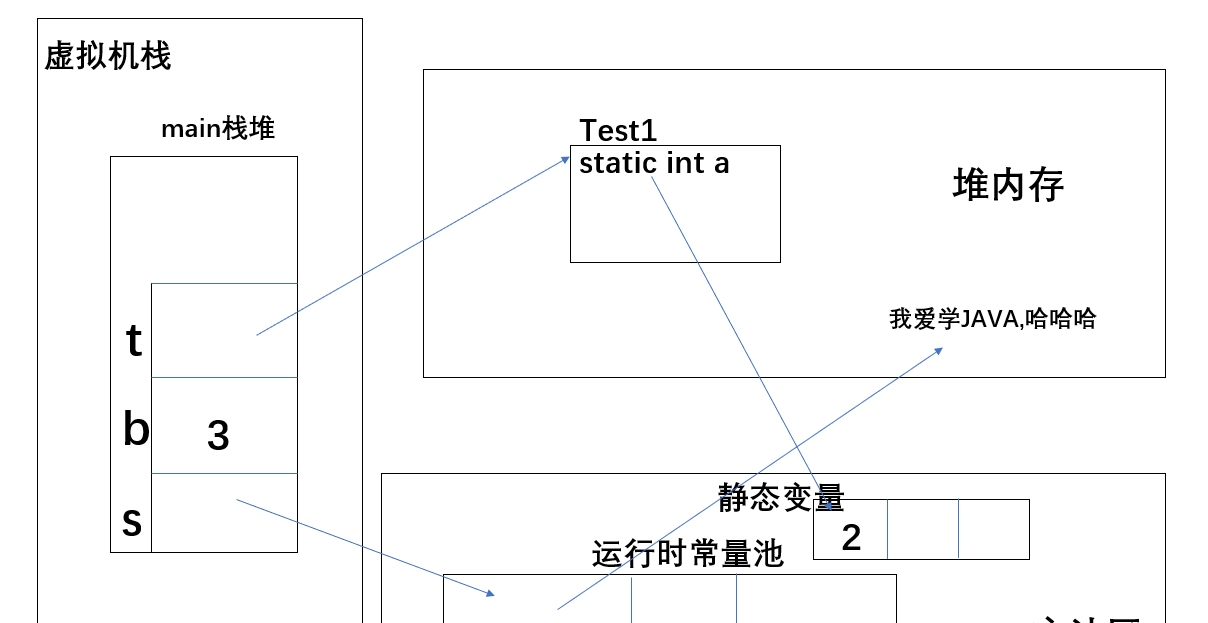
如上圖所示,當虛拟機執行main方法時,在java虛拟棧中建立一個main方法的棧幀,進行入棧操作,該棧中存放了局部變量表,分别為s,b和t,其中,b為基本資料類型,直接存儲在棧中,而s對應的字元串是字面量,是以其引用存儲在運作時常量池中,t為對象的引用,存儲在堆記憶體中,因為a是靜态變量,是以建立t之後,其需要到方法去中去引用2。下面重點談談new建立對象的過程。
當使用new方法建立對象時,虛拟機首先檢查指令的參數是否在常量池中定位到一個類的符号引用,并且檢測該類是否被加載,如果沒有先進行加載。
之後開始進行對象的記憶體配置設定工作,這裡有兩種方法,一種為指針碰撞法,另一種為空閑清單法。指針碰撞要求記憶體是規整的,指針可以往空閑方向移動一塊區域;而空閑清單則在清單中記錄有哪些空閑的區域,按照清單進行空間配置設定,并更新清單資料。
當然劃分的過程中會出現同步的問題。這時候就有兩種解決方案, 一種采用CAS樂觀鎖來保證劃分的原子性,另外一種則采用本地線程緩沖機制,即給每個線程分别預留一塊TLAB記憶體,供該線程進行配置設定。
在配置設定完記憶體之後,虛拟機将記憶體進行初始化,對于對象進行 必要設定,這裡主要是對象頭的設定,其一般根據對象的狀态進行複用。這裡不進行詳細叙述,有興趣可以自己百度下複用表。(如果是數組,頭對象中還應該有數組的長度資訊)之後就可以開始執行< init >方法,按照我們的構造函數進行初始化了。
這裡補充一個對象的引用方式,其主要有兩種方式,一種是直接引用,另一種是采用句柄通路,因為方法區中含有對象的類型資料,如果采用直接引用,則對象的執行個體資料中需要包含對象資料類型的指針(這部分資訊存儲在對象頭中),下面用2張圖表示兩種方式的差別。直接引用速度快,而句引用在對象被移動時不需要修改引用指針。

3.記憶體溢出實踐
由于本書上的實踐例子較多,在這裡我就列舉兩個例子,給大家體會下如果設定一些虛拟機參數,到達我們想要看到的記憶體溢出問題
1.堆記憶體溢出
public class HeapOOM {
static class OOMObject{
}
public static void main(String[] args) {
List<OOMObject> list=new ArrayList<OOMObject>();
while(true){
list.add(new OOMObject());
}
}
}
虛拟機參數:-Xms20m -Xmx20m -XX:+HeapDumpOnOutOfMemoryError
結果:
上述例子将java的對記憶體設定為了20M,通過運作我們可以看到,控制台上出現了OutOfMemoryError異常,并且溢出的是對記憶體。
2. 虛拟機棧記憶體溢出
public class JavaVMStackSOF {
private int stackLength=1;
public void stackLeak(){
stackLength++;
stackLeak();
}
public static void main(String[] args) {
JavaVMStackSOF oom =new JavaVMStackSOF();
try{
oom.stackLeak();
}catch(Throwable e){
System.out.println("Stack length:"+oom.stackLength);
throw e;
}
}
}
虛拟機設定參數:-Xss128k.
結果:
通過不斷運作可以看到,控制台上出現了StackOverflowError異常。
4.JAVA垃圾收集器
虛拟機對于垃圾進行回收時,首先需要進行垃圾進行判斷,這裡就要提到兩種算法。
1 引用計數法(基本不用的方法)
簡單來說,就是堆記憶體的一個對象,一旦被引用了就在計數器上+1,引用釋放就-1,計數器為0就認為該記憶體是垃圾,但是當兩個java對象互相引用時,此方法就無法進行标記。
2 可達性分析法
從GCRoots 出發,進行搜尋,搜尋不到的我們認為是垃圾。我們認為可以作為GCRoots 的對象為:虛拟機棧中的引用對象,方法區中靜态屬性引用的對象,方法區中常量引用的對象,本地方法棧中Native方法引用的對象。
在判斷之後,我們需要對垃圾對象進行回收了,這裡需要提及一下,并不是說垃圾就立即就被回收了,一般如果沒有重寫finalize()方法或者說虛拟機調用過該對象的finalize()方法,那麼該對象會被放在一個低優先級的Finalizer線程中進行執行,在此過程中,如果對象重新與引用鍊上的任意一個對象發生關聯,就可以不被清除,逃脫成功。但是一個逃脫成功的對象再次進入Finalizer線程中,無論如何不能再次逃脫。
下面介紹一下垃圾收集算法:
1 标記-清除法:
此方法如其名字一樣,先對回收對象進行标記,然後進行清除。但是此種方法有兩個缺點:1 清除效率低 2 由于隻進行清除操作,那麼記憶體空間會被分割成很多不連續的記憶體碎片,這樣配置設定大對象時則需要再次垃圾收集,效率不高。
2.複制算法:
它将可用記憶體按容量劃分為大小相等的兩塊,每次隻使用其中的一塊。當這一塊的記憶體用完了,就将還存活着的對象複制到另外一塊上面,然後再把已使用過的記憶體空間一次清理掉。這樣做的缺點是我始終隻使用了一般的記憶體。在目前的虛拟機對此進行改進,将記憶體分為Eden,From Survivor和To Survivor區,其中Eden和survior的比例為8:1,每次隻使用一塊survior進行存活對象的存儲,将Eden和另一快survior進行清除。從這個特性,我們可以知道,這種算法适合用在垃圾回收率較高的區域,也就是新生代中。與新生代對應的,老年代的記憶體中,基本不發生垃圾回收。當有時候存活的對象多于10%時,有時需要和老年代進行配置設定擔保工作。
3.标記-整理算法:
此算法先進行标記,然後把沒有标記的對象移到一邊,剩下的進行清除。
從上面的算法特性,我們可以總結出,1,3算法适合老年代,而2算法則适合新生代。
下面簡單介紹下幾種主流的垃圾收集器:
用于新生代的垃圾收集器:
Serial收集器: 采用複制算法;單線程收集; 進行垃圾收集時,必須暫停所有工作線程,直到完成;即會"Stop The World",可與CMS配合使用。
ParNew收集器: 采用複制算法;多線程收集;進行垃圾收集時,必須暫停所有工作線程,直到完成;即會"Stop The World",可與CMS配合使用。
Parallel收集器: 基本與ParNew相同,但是可以進行吞吐量的控制以及最大垃圾停頓時間的控制,屬于吞吐量優先收集器。
用于老年代的垃圾收集器:
CMS收集器: 采用标記清除算法,多線程收集,可以并發處理,停頓時間低的收集器。但是,對于CPU資源敏感,無法處理浮動垃圾,空間碎片過多。
最厲害的收集器:
G1收集器: 并發處理,空間整合算法,可預測停頓。
這裡的空間整合算法,依然是将記憶體劃分為新生代和老年代,但是兩者之間不在實體隔離。 将記憶體化整為零,變為多個大小相等的獨立區域,盡可能提高收集效率,但是這樣存在一個問題,即一個對象配置設定在Region中,它并非隻被本Region中的其他對象引用,而是有可能被其它區域中的對象引用。
G1收集器采用了Remember Set來解決這一問題,主要程式在對引用類型進行寫操作時,會檢測引用對象是否處在不同的區域中,如果是,則把引用資訊記錄到對象所屬的區域的Remember Set表中來保證收集操作的實行。
5.記憶體的配置設定政策
java記憶體配置設定政策相對比較簡單,可以用幾句話進行總結,(這裡的記憶體配置設定不包括棧上配置設定技術):
1.對象優先配置設定在Eden區:
當Eden區不夠配置設定,會采用配置設定擔保,“借”記憶體,并且擔保的順序為Survior區,老年代。
2.大對象直接配置設定在老年代:
這裡可以采用-XX:PretenureSizeThreshold參數進行設定,當對象大于設定值時會直接存入老年代中。
3.長期存活的對象将進入老年代:
這裡可以采用-XX:MaxTenuringThreshold參數進行設定,當對象存活次數大于設定值時會直接存入老年代中。
4.動态對象年齡判定:
當Survivor區中的同齡對象大于該區域總和的一般,則将大于等于該年齡的對象送入老年區。
以上為我對此的一些總結,路漫漫其修遠兮,繼續加油!!!