将源碼中的字元分割成标記符(token)
将标記符組織成一棵抽象文法樹(AST)。抽象文法樹就是中間表示。
評估這棵抽象文法樹,并在最後列印這棵樹的狀态
将字元串分割成标記符的過程叫做「詞法分析」,通過一個詞法分析器完成。關鍵字是很短,易于了解的字元串,包含程式中最基本的部分,如數字、辨別符、關鍵字和操作符。詞法分析器會除去空格和注釋,因為它們都會被解釋器忽略。
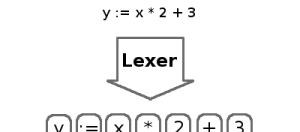
将标記符組織成抽象文法樹(AST)的過程稱為「解析過程」。解析器将程式的結構提取成一張我們可以評估的表格。

實際執行這個解析過的抽象文法樹的過程稱為評估。這實際上是這個解析器中最簡單的部分了。
本文會把重點放在詞法分析器上。我們将編寫一個通用的詞彙庫,然後用它來為IMP建立一個詞法分析器。下一篇文章将會重點打造一個文法分析器和評估電腦。
詞彙庫
詞法分析器的操作相當簡單。它是基于正規表達式的,是以如果你不熟悉它們,你可能需要讀一些資料。簡單來說,正規表達式就是一種能描述其他字元串的特殊的格式化的字元串。你可以使用它們去比對電話号碼或是郵箱位址,或者是像我們遇到在這種情況,不同類型的标記符。
詞法分析器的輸入可能隻是一個字元串。簡單起見,我們将整個輸入檔案都讀到記憶體中。輸出是一個标記符清單。每個标記符包括一個值(它代表的字元串)和一個标記(表示它是一個什麼類型的标記符)。文法分析器會使用這兩個資料來決定如何建構一棵抽象文法樹。
由于不論何種語言的詞法分析器,其操作都大同小異,我們将建立一個通用的詞法分析器,包括一個正規表達式清單和對應的标簽(tag)。對每一個表達式,它都會檢查是否和目前位置的輸入文本比對。如果比對,比對文本就會作為一個标記符被提取出來,并且被加上該正規表達式的标簽。如果該正規表達式沒有标簽,那麼這段文本将會被丢棄。這樣免得我們被諸如注釋和空格之類的垃圾字元幹擾。如果沒有比對的正規表達式,程式就要報錯并終止。這個過程會不斷循環直到沒有字元可比對。
下面是一段來自詞彙庫的代碼:
Python
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
import sys
import re
def lex(characters, token_exprs):
pos = 0
tokens = []
while pos < len(characters):
match = None
for token_expr in token_exprs:
pattern, tag = token_expr
regex = re.compile(pattern)
match = regex.match(characters, pos)
if match:
text = match.group(0)
if tag:
token = (text, tag)
tokens.append(token)
break
if not match:
sys.stderr.write('Illegal character: %sn' % characters[pos])
sys.exit(1)
else:
pos = match.end(0)
return tokens
注意,我們周遊正規表達式的順序很重要。lex會周遊所有的表達式,然後接受第一個比對成功的表達式。這也就意味着,當使用詞法分析器時,我們應當首先考慮最具體的表達式(像那些比對算子(matching operator)和關鍵詞),其次才是比較一般的表達式(像辨別符和數字)。
詞法分析器
給定上面的lex函數,為IMP定義一個詞法分析器就非常簡單了。首先我們要做的就是為标記符定義一系列的标簽。IMP隻需要三個标簽。RESERVED表示一個保留字或操作符。INT表示一個文字整數。ID代表辨別符。
Python
1
2
3
4
5
import lexer
RESERVED = 'RESERVED'
INT = 'INT'
ID = 'ID'
接下來定義詞法分析器将會用到的标記符表達式。前兩個表達式比對空格和注釋。它們沒有标簽,是以 lex 會丢棄它們比對到的所有字元。
Python
1
2
3
token_exprs = [
(r'[ nt]+', None),
(r'#[^n]*', None),
然後,隻剩下所有的操作符和保留字了。記住,每個正規表達式前面的“r”表示這個字元串是“raw”;Python不會處理任何轉義字元。這使我們可以在字元串中包含進反斜線,正規表達式正是利用這一點來轉義操作符比如“+”和“*”。
Python
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
(r':=', RESERVED),
(r'(', RESERVED),
(r')', RESERVED),
(r';', RESERVED),
(r'+', RESERVED),
(r'-', RESERVED),
(r'*', RESERVED),
(r'/', RESERVED),
(r'<=', RESERVED),
(r'<', RESERVED),
(r'>=', RESERVED),
(r'>', RESERVED),
(r'=', RESERVED),
(r'!=', RESERVED),
(r'and', RESERVED),
(r'or', RESERVED),
(r'not', RESERVED),
(r'if', RESERVED),
(r'then', RESERVED),
(r'else', RESERVED),
(r'while', RESERVED),
(r'do', RESERVED),
(r'end', RESERVED),
最後,輪到整數和辨別符的表達式。要注意的是,辨別符的正規表達式會比對上面的所有的保留字,是以它一定要留到最後。
Python
1
2
3
(r'[0-9]+', INT),
(r'[A-Za-z][A-Za-z0-9_]*', ID),
]
既然正規表達式已經定義好了,我們還需要建立一個實際的lexer函數。
Python
1
2
def imp_lex(characters):
return lexer.lex(characters, token_exprs)
如果你對這部分感興趣,這裡有一些驅動代碼可以測試輸出:
Python
1
2
3
4
5
6
7
8
9
10
11
import sys
from imp_lexer import *
if __name__ == '__main__':
filename = sys.argv[1]
file = open(filename)
characters = file.read()
file.close()
tokens = imp_lex(characters)
for token in tokens:
print token
繼續……
在本系列的下一篇文章中,我會讨論解析器組合,然後描述如何使用他們從lexer中生成的标記符清單建立抽象文法樹。
如果你對于實作IMP解釋器很感興趣,你可以從這裡下載下傳全部的源碼。
在源碼包含的示例檔案中運作解釋器:
Python
1
python imp.py hello.imp
運作單元測試:
Python
1
python test.py