回顧
上回我們把彙編裡涉及到的寄存器和記憶體通路相關的内容說了。先來梳理一下:
- 寄存器是一些超級小的臨時存儲器,在CPU裡面,存放CPU馬上就要用到的資料或者剛處理完的結果
- 要處理的資料太多,寄存器裝不下了,需要更多寄存器,但是這玩意貴啊
- 記憶體可以解決上述問題,但是記憶體相比寄存器要慢,優點是相對便宜,容量也大
插曲:C語言與彙編語言的關系
還有一些疑慮,先暫時解釋一下。首先,C語言裡程式設計裡,我們從來沒有關心過寄存器。彙編語言裡突然冒出這麼一個東西,學起來好難受。接下來的内容,我們先把C語言和彙編語言的知識,來一次大一統,幫助了解。
首先我們來看一個C語言程式:
int x, y, z;
int main() {
x = 2;
y = 3;
z = x + y;
return z;
} 考慮到我們的彙編教程才剛開始,我這裡盡可能先簡化C程式,這樣稍後涉及到等價的彙編内容時所需的知識都是前面介紹過的。
儲存為test01.c檔案,先編譯運作這個程式:
(注意,這裡的gcc帶了一個參數-m32,因為我們要編譯出32位(x86)的可執行檔案)
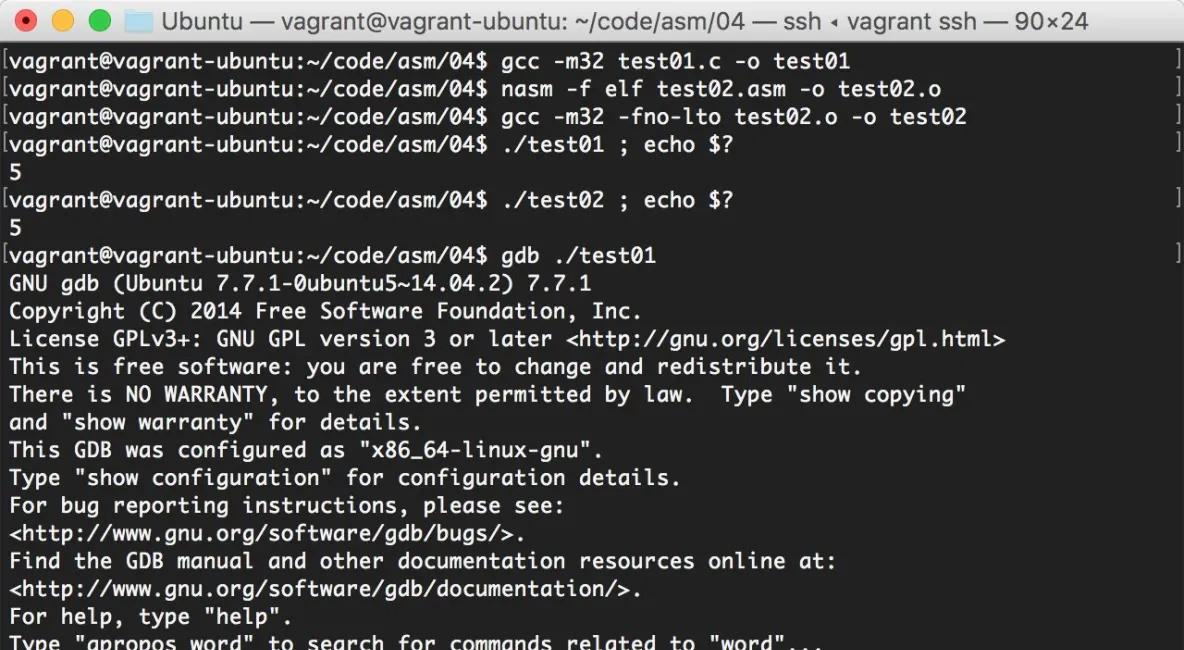
$ gcc -m32 test01.c -o test01
$ ./test01 ; echo $?
5 好了,在這裡,我們的程式傳回了一個值:5。
好的,接下來我們看看如果我們要用彙編實作幾乎相同的過程,該怎麼做?
首先,三個全局變量:
int x, y, z;
總得有吧。(這裡之是以會用全局變量,是考慮到局部變量相關的彙編知識還未介紹,先将就一下,後續再說局部變量的内容)
首先,在C語言裡,你可以認為每個變量都會占用一定的記憶體空間,也就是說,這裡的x、y、z分别都占用了一個“整型”也就是4位元組的存儲空間。
上次我們介紹過在彙編裡面通路記憶體的知識,當然,我們也知道了怎麼在資料區劃出一定的空間,這次我們就照搬前面提及的方法:
global main
main:
mov eax, 0
ret
section .data
x dw 0
y dw 0
z dw 0 這個程式就等價于下面的C代碼:
int x, y, z;
int main() {
return 0;
} 也就是現在有了三個全局變量,隻是現在彙程式設計式什麼都沒做,僅僅傳回了0而已。
這裡的C代碼和上述彙編代碼從某種程度上來說,就是完全等價的。甚至,我們的C語言編譯器就可以直接把C代碼,翻譯成上述的彙編代碼,餘下的工作交給nasm再編譯一次,把彙編轉化為可執行檔案,就能夠得到最後的程式了。當然,理論上可以這麼做,實際上有的編譯器也就是這麼做的,隻是人家生成的彙編格式不是nasm,而是其它的類型,但是道理都差不多。
也就是說,一個足夠精簡的C編譯器,隻需要能夠把C代碼翻譯成彙編代碼,剩下的交給彙編器完成,也就能實作完整的C語言編譯器了,也就能得到最後的可執行檔案了。實際上C編譯器是完全可以這麼做的,甚至有的就是這麼做的。
好了,先不扯這些,我們先把前面的程式補充完整,達到和最前面的C代碼等價為止。接下來,我們要關注這個:
x = 2;
y = 3; 也就是要把數字2和3,分别放到x和y對應的記憶體區域中去。很簡單,我們可以這麼做:
mov eax, 2
mov [x], eax
mov eax, 3
mov [y], eax 也就是先把2扔到寄存器eax中去,然後把eax中的内容放回到x對應的記憶體中。同理,y也這樣處理。
好了,接下來的加法語句:
z = x + y; 也可以做了:
mov eax, [x]
mov ebx, [y]
add eax, ebx
mov [z], eax 好了,這段代碼應該可以看懂吧,簡單說一下思路:
- 把x和y對應的記憶體中的内容分别放到eax和ebx中去
- 進行形如eax = eax + ebx的加法,最終的和存放在eax中
- 再将eax中的内容存放到z對應的記憶體中去
最後,我們還有一個事情需要處理,也就是傳回語句:
return z; 這個也很好辦,按照約定,eax中的值,就是函數的傳回值:
mov eax, [z]
ret 整個程式就算完了,我們已經完整地将C代碼的彙編語言等價形式寫出來了,最終的代碼是這樣的:
global main
main:
mov eax, 2
mov [x], eax
mov eax, 3
mov [y], eax
mov eax, [x]
mov ebx, [y]
add eax, ebx
mov [z], eax
mov eax, [z]
ret
section .data
x dw 0
y dw 0
z dw 0 來先儲存成檔案test02.asm,編譯運作看看效果:
$ nasm -f elf test02.asm -o test02.o
$ gcc -m32 test02.o -o test02
$ ./test02 ; echo $?
5 搞定。結果完全和前面的C代碼一緻。
揭開C程式的廬山真面目
你以為自己YY出等價的彙編代碼就完事兒了?圖樣,接下來我們繼續用工具一探究竟,玩真的。
先說一下準備工作,首先有下面兩個檔案:
test01.c test02.asm 其中一個為上面提到的完整C代碼,一個為上述完整的彙編代碼。然後按照前面的訓示,都編譯成可執行檔案,編譯完成後是這樣的:
$ gcc -m32 test01.c -o test01
$ nasm -f elf test02.asm -o test02.o
$ gcc -m32 -fno-lto test02.o -o test02
$ ls
test01 test01.c test02 test02.asm test02.o (注意,要按照這裡的編譯指令來做)
其中的test01是C代碼編譯出來的,test02是彙編代碼編譯出來的。
祭出gdb
好,接下來有請我們的大将軍gdb登場。
先來看看我們的C編譯後的程式,反彙編之後是什麼鬼樣子:
gdb ./test01 然後輸入指令檢視反彙編代碼:
(gdb) set disassembly-flavor intel
(gdb) disas main
Dump of assembler code for function main:
0x080483ed <+0>: push ebp
0x080483ee <+1>: mov ebp,esp
0x080483f0 <+3>: mov DWORD PTR ds:0x804a024,0x2
0x080483fa <+13>: mov DWORD PTR ds:0x804a028,0x3
0x08048404 <+23>: mov edx,DWORD PTR ds:0x804a024
0x0804840a <+29>: mov eax,ds:0x804a028
0x0804840f <+34>: add eax,edx
0x08048411 <+36>: mov ds:0x804a020,eax
0x08048416 <+41>: mov eax,ds:0x804a020
0x0804841b <+46>: pop ebp
0x0804841c <+47>: ret
End of assembler dump.
(gdb) quit
$ 好,别急,先退出,我們再看看我們彙程式設計式的反彙編代碼:
gdb ./test02
(gdb) set disassembly-flavor intel
(gdb) disas main
0x080483f0 <+0>: mov eax,0x2
0x080483f5 <+5>: mov ds:0x804a01c,eax
0x080483fa <+10>: mov eax,0x3
0x080483ff <+15>: mov ds:0x804a01e,eax
0x08048404 <+20>: mov eax,ds:0x804a01c
0x08048409 <+25>: mov ebx,DWORD PTR ds:0x804a01e
0x0804840f <+31>: add eax,ebx
0x08048411 <+33>: mov ds:0x804a020,eax
0x08048416 <+38>: mov eax,ds:0x804a020
0x0804841b <+43>: ret
0x0804841c <+44>: xchg ax,ax
0x0804841e <+46>: xchg ax,ax
End of assembler dump.
(gdb) quit 好了,我們都看到反彙編代碼了。先來檢查一下這裡test02的反彙編代碼,和我們寫的彙編代碼是不是一緻的:
0x080483f0 <+0>: mov eax,0x2
0x080483f5 <+5>: mov ds:0x804a01c,eax
0x080483fa <+10>: mov eax,0x3
0x080483ff <+15>: mov ds:0x804a01e,eax
0x08048404 <+20>: mov eax,ds:0x804a01c
0x08048409 <+25>: mov ebx,DWORD PTR ds:0x804a01e
0x0804840f <+31>: add eax,ebx
0x08048411 <+33>: mov ds:0x804a020,eax
0x08048416 <+38>: mov eax,ds:0x804a020
0x0804841b <+43>: ret 直接和前面寫的彙編進行比對便是,由于格式問題,裡面的部分位址和标簽已經面目全非,但是我們隻要能夠辨識出來就行了,不需要全部都搞得明明白白。這是前面的彙編代碼:
mov eax, 2
mov [x], eax
mov eax, 3
mov [y], eax
mov eax, [x]
mov ebx, [y]
add eax, ebx
mov [z], eax
mov eax, [z]
ret 數一下行數就知道,是相同的。再仔細看看每一條指令,基本也是差不多的。當然x、y、z這些東西不見了,變成了一些奇奇怪怪的符号,在此暫不深究。
我們再看看C程式的彙編代碼:
0x080483ed <+0>: push ebp
0x080483ee <+1>: mov ebp,esp
0x080483f0 <+3>: mov DWORD PTR ds:0x804a024,0x2
0x080483fa <+13>: mov DWORD PTR ds:0x804a028,0x3
0x08048404 <+23>: mov edx,DWORD PTR ds:0x804a024
0x0804840a <+29>: mov eax,ds:0x804a028
0x0804840f <+34>: add eax,edx
0x08048411 <+36>: mov ds:0x804a020,eax
0x08048416 <+41>: mov eax,ds:0x804a020
0x0804841b <+46>: pop ebp
0x0804841c <+47>: ret 這裡,先撇開下面幾個指令(這幾個指令本身是有用的,但是在這個例子裡,可以暫時先去掉,具體它們是幹啥的,後面說),去掉它們:
push ebp
mov ebp, esp
....
pop ebp 于是C程式反彙編變成了這樣子:
0x080483f0 <+3>: mov DWORD PTR ds:0x804a024,0x2
0x080483fa <+13>: mov DWORD PTR ds:0x804a028,0x3
0x08048404 <+23>: mov edx,DWORD PTR ds:0x804a024
0x0804840a <+29>: mov eax,ds:0x804a028
0x0804840f <+34>: add eax,edx
0x08048411 <+36>: mov ds:0x804a020,eax
0x08048416 <+41>: mov eax,ds:0x804a020
0x0804841c <+47>: ret 還是看起來不太明朗,怎麼辦?我們追蹤裡面的數字2、3和add指令,把那些稀奇古怪的符号換成我們認識的标簽x、y、z再看看:
0x080483f0 <+3>: mov [x],0x2
0x080483fa <+13>: mov [y],0x3
0x08048404 <+23>: mov edx,[x]
0x0804840a <+29>: mov eax,[y]
0x0804840f <+34>: add eax,edx
0x08048411 <+36>: mov [z],eax
0x08048416 <+41>: mov eax,[z]
0x0804841c <+47>: ret 對比前面我們自己寫的彙編代碼看看呢?是不是基本是八九不離十了?僅僅有兩個地方不一樣:1. 使用的寄存器順序不太一樣,但是這個無妨;2. 有兩條彙編指令,在C編譯後的反彙編代碼中對應的是一條指令。
這裡我們發現了,原來
mov eax, 2
mov [x], eax 可以被精簡為一條語句:
mov [x], 2 好的,按照C編譯器給我們提供的資訊,我們的彙程式設計式還可以簡化成這樣:
global main
main:
mov [x], 0x2
mov [y], 0x3
mov eax, [x]
mov ebx, [y]
add eax, ebx
mov [z], eax
mov eax, [z]
ret
section .data
x dw 0
y dw 0
z dw 0 然而,當我們把彙編寫成這樣自己編譯的時候,卻出錯了,這裡并不能完全這麼寫,得做一些小修改,把前兩條指令改成:
mov dword [x], 0x2
mov dword [y], 0x3 這樣再編譯,就沒有問題了。通過研究,我們用彙編寫出了和前面的C程式編譯後代碼等價的彙程式設計式:
global main
main:
mov dword [x], 0x2
mov dword [y], 0x3
mov eax, [x]
mov ebx, [y]
add eax, ebx
mov [z], eax
mov eax, [z]
ret
section .data
x dw 0
y dw 0
z dw 0 總結
好了,到這裡,我們通過nasm、gcc和gdb,将一個簡單的C程式,用彙編語言等價地實作出來了。
說一下這一段内容的重點:
- C程式在編譯階段,在邏輯上,會被轉化成等價的彙程式設計式
- 彙程式設計式經過編譯器内置(或外置)的彙編器,編譯成機器指令(到可執行檔案的過程中還有一個連結階段,後面再提)
- 我們可以通過gdb反彙編得知一個C程式的彙編形式
其實,學習彙編語言的目的,并非主要是為了今後用彙編語言程式設計,而是借助于對彙編語言的了解,進一步地去了解進階語言在底層的一些細節,一個C語言的指派語句,一個C語言的加法表達式,在編譯後運作的時候,到底在做些什麼。也就是通過彙編認識到計算機中,程式執行的時候到底在做些什麼,CPU到底在幹什麼,借助于此,了解計算機程式在CPU眼裡的本質。
後續通過這個,結合各種資料學習彙編語言,将是一個非常不錯的選擇。在對彙編進行實踐和了解的過程中,也能更清楚地知道C語言裡的各種寫法,到底代表什麼含義,加深對C語言的認識。
![C語言-----初階指針詳解[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)