Chrome不是萬能的,使用快捷方法也需要自己好好檢查一遍!!
剛學爬蟲,在進行練習的時候。使用chrome擷取某個元素的xpath的時候,獲得的内容總是為空。如下圖:
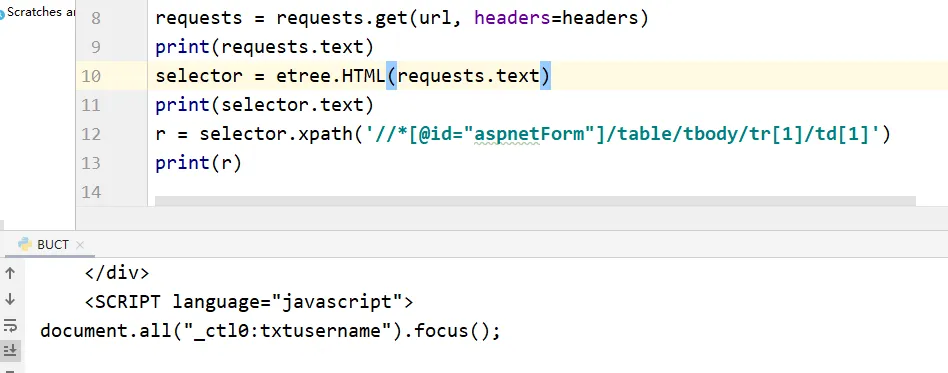
剛開始真的是百思不得其解,我以為是get除了問題,又以為是etree.html出了問題。結果搞了一下午都沒有解決,最後經過一個大哥指點,核對了一下xpath路徑,發現問題出現在chrome自動生成的xpath上!!
網頁部分源代碼:

chrome給出的xpath:
//*[@id=“aspnetForm”]/table/tbody/tr[1]/td[1]
經過仔細的核對,發現chrome浏覽器給xpath加上了一個tbody标簽!(我也不知道為什麼…)
把這個标簽删除之後,使用正确的xpath路徑
//*[@id=“aspnetForm”]/table/tr[1]/td[1]