Python 作為一門解釋型語言,以代碼簡潔易懂著稱。我們可以直接對名稱指派,而不必聲明類型。名稱類型的确定、記憶體空間的配置設定與釋放都是由 Python 解釋器在運作時進行的。
Python 這一自動管理記憶體功能極大的減小了程式員負擔。對于 Python 這種進階别的語言,開發者完成可以不用關心其内部的垃圾回收機制。相輔相成的通過學習 Python 内部的垃圾回收機制,并了解其原理,可以使得開發者能夠更好的寫代碼,更加 Pythonista。
目錄
Python記憶體管理機制
Python的垃圾回收機制
2.1 引用計數(reference counting)
2.2 标記清除(Mark and Sweep)
2.3 分代回收(Generational garbage collector)
Python中的gc子產品
Python記憶體管理機制
在 Python 中,記憶體管理涉及到一個包含所有 Python 對象和資料結構的私有堆(heap)。這個私有堆的管理由内部的 Python 記憶體管理器(Python memory manager) 保證。Python 記憶體管理器有不同的元件來處理各種動态存儲管理方面的問題,如共享、分割、預配置設定或緩存。
在最底層,一個原始記憶體配置設定器通過與作業系統的記憶體管理器互動,確定私有堆中有足夠的空間來存儲所有與 Python 相關的資料。在原始記憶體配置設定器的基礎上,幾個對象特定的配置設定器在同一堆上運作,并根據每種對象類型的特點實作不同的記憶體管理政策。例如,整數對象在堆内的管理方式不同于字元串、元組或字典,因為整數需要不同的存儲需求和速度與空間的權衡。是以,Python 記憶體管理器将一些工作配置設定給對象特定配置設定器,但確定後者在私有堆的範圍内運作。
Python 堆記憶體的管理是由解釋器來執行,使用者對它沒有控制權,即使他們經常操作指向堆内記憶體塊的對象指針,了解這一點十分重要。
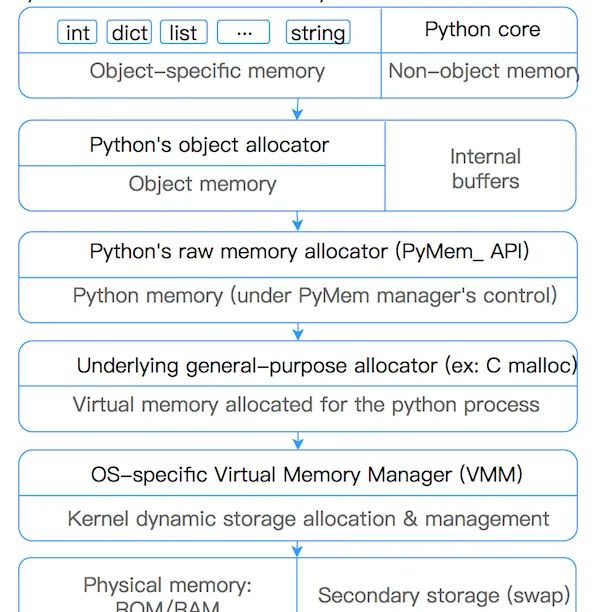
Python為了避免對于小對象(<=512bytes)出現數量過多的GC,導緻的性能消耗。Python對于小對象采用子配置設定 (記憶體池) 的方式進行記憶體塊的管理。對于大對象使用标準C中的allocator來配置設定記憶體。
Python對于小對象的allocator由大到小分為三個層級:arena、pool、block。
Block
Block是最小的一個層級,每個block僅僅可以容納包含一個固定大小的Python Object。大小從8-512bytes,以8bytes為步長,分為64類不同的block。
| Request in bytes | Size of allocated block | size class idx |
| 1-8 | 8 | |
| 9-16 | 16 | 1 |
| 17-24 | 24 | 2 |
| 25-32 | 32 | 3 |
| 33-40 | 40 | 4 |
| 41-48 | 48 | 5 |
| … | … | … |
| 505-512 | 512 | 63 |
Pool
Pool具有相同大小的block組成集合稱為Pool。通常情況下,Pool的大小為4kb,與虛拟記憶體頁的大小儲存一緻。限制Pool中block有固定的大小,有如下好處是: 當一個對象在目前Pool中的某個block被銷毀時,Pool記憶體管理可以将新生成的對象放入該block中。
/* Pool for small blocks. */
struct pool_header {
union { block *_padding;
uint count; } ref; /* number of allocated blocks */
block *freeblock; /* pool's free list head */
struct pool_header *nextpool; /* next pool of this size class */
struct pool_header *prevpool; /* previous pool "" */
uint arenaindex; /* index into arenas of base adr */
uint szidx; /* block size class index */
uint nextoffset; /* bytes to virgin block */
uint maxnextoffset; /* largest valid nextoffset */
};
具有相同大小的Pool通過雙向連結清單來連接配接,sidx用來辨別Block的類型。arenaindex辨別目前Pool屬于哪個Arena。ref.conut辨別目前Pool使用了多少個Block。freeblock:辨別目前Pools中可用block的指針。freeblock實際是單連結清單實作,當一塊block為空狀态時,則将該block插入到freeblock連結清單的頭部。
每個Pool都有三個狀态:
-
- used:部分使用,即Pool不滿,也不為空
- full:滿,即所有Pool中的Block都已被配置設定
- empty:空, 即所有Pool中的Block都未被配置設定
usedpool為了很好的高效的管理Pool,Python額外使用了array,usedpool來管理。即如下圖所示,usedpool按序存儲着每個特性大小的Pool的頭指針,相同大小的Pool按照雙向連結清單來連接配接。當配置設定新的記憶體空間時,建立一個特定大小的Pool,隻需要使用usedpools找到頭指針,周遊即可,當沒有記憶體空間時,隻需要在Pool的雙向連結清單的頭部插入新的Pool即可。

Arena
Pools和Blocks都不會直接去進行記憶體配置設定(allocate), Pools和Blocks會使用從arena那邊已經配置設定好的記憶體空間。Arena:是配置設定在堆上256kb的塊狀記憶體,提供了64個Pool。
struct arena_object {
uintptr_t address;
block* pool_address;
uint nfreepools;
uint ntotalpools;
struct pool_header* freepools;
struct arena_object* nextarena;
struct arena_object* prevarena;
};
所有的arenas也使用雙連結清單進行連接配接(prevarena, nextarena字段). nfreepools和ntotalpools存儲着目前可用pools的資訊。freepools指針指向目前可用的pools。arena結構簡單,職責即為按需給pools配置設定記憶體,當一個arena為空時,則将該arena的記憶體歸還給作業系統。
Python的垃圾回收機制
Python采用的是引用計數機制為主,标記-清除和分代收集兩種機制為輔的政策。
引用計數(reference counting)
Python語言預設采用的垃圾收集機制是“引用計數法 Reference Counting”,該算法最早George E. Collins在1960的時候首次提出,50年後的今天,該算法依然被很多程式設計語言使用。
引用計數法的原理是:每個對象維護一個ob_ref字段,用來記錄該對象目前被引用的次數,每當新的引用指向該對象時,它的引用計數ob_ref加1,每當該對象的引用失效時計數ob_ref減1,一旦對象的引用計數為0,該對象立即被回收,對象占用的記憶體空間将被釋放。
它的缺點是需要額外的空間維護引用計數,這個問題是其次的,不過最主要的問題是它不能解決對象的“循環引用”,是以,也有很多語言比如Java并沒有采用該算法做來垃圾的收集機制。
Python中一切皆對象,也就是說,在Python中你用到的一切變量,本質上都是類對象。實際上每一個對象的核心就是一個結構體PyObject,它的内部有一個引用計數器ob_refcnt,程式在運作的過程中會實時的更新ob_refcnt的值,來反映引用目前對象的名稱數量。當某對象的引用計數值為0,說明這個對象變成了垃圾,那麼它會被回收掉,它所用的記憶體也會被立即釋放掉。
typedef struct _object {
int ob_refcnt;//引用計數
struct _typeobject *ob_type;
} PyObject;
導緻引用計數+1的情況:
-
- 對象被建立,例如a=23
- 對象被引用,例如b=a
- 對象被作為參數,傳入到一個函數中,例如func(a)
- 對象作為一個元素,存儲在容器中,例如list1=[a,a]
導緻引用計數-1的情況
-
- 對象的别名被顯式銷毀,例如del a
- 對象的别名被賦予新的對象,例如a=24
- 一個對象離開它的作用域,例如f函數執行完畢時,func函數中的局部變量(全局變量不會)
- 對象所在的容器被銷毀,或從容器中删除對象
我們可以通過sys包中的getrefcount()來擷取一個名稱所引用的對象目前的引用計。sys.getrefcount()本身會使得引用計數加一.
循環引用
引用計數的另一個現象就是循環引用,相當于有兩個對象a和b,其中a引用了b,b引用了a,這樣a和b的引用計數都為1,并且永遠都不會為0,這就意味着這兩個對象永遠都不會被回收了,這就是循環引用 , a與b形成了一個引用循環 , 示例如下 :
a = [1, 2] # 計數為 1
b = [2, 3] # 計數為 1
a.append(b) # 計數為 2
b.append(a) # 計數為 2
del a # 計數為 1
del b # 計數為 1
除了上述兩個對象互相引用之外 , 還可以引用自身 :
list3 = [1,2,3]
list3.append(list3)
循環引用導緻變量計數永不為 0,造成引用計數無法将其删除。
引用計數法有其明顯的優點,如高效、實作邏輯簡單、具備實時性,一旦一個對象的引用計數歸零,記憶體就直接釋放了。不用像其他機制等到特定時機。将垃圾回收随機配置設定到運作的階段,處理回收記憶體的時間分攤到了平時,正常程式的運作比較平穩。引用計數也存在着一些缺點:
-
- 邏輯簡單,但實作有些麻煩。每個對象需要配置設定單獨的空間來統計引用計數,這無形中加大的空間的負擔,并且需要對引用計數進行維護,在維護的時候很容易會出錯。
- 在一些場景下,可能會比較慢。正常來說垃圾回收會比較平穩運作,但是當需要釋放一個大的對象時,比如字典,需要對引用的所有對象循環嵌套調用,進而可能會花費比較長的時間。
- 循環引用。這将是引用計數的緻命傷,引用計數對此是無解的,是以必須要使用其它的垃圾回收算法對其進行補充。
也就是說,Python 的垃圾回收機制,很大一部分是為了處理可能産生的循環引用,是對引用計數的補充。
标記清除(Mark and Sweep)
Python采用了“标記-清除”(Mark and Sweep)算法,解決容器對象可能産生的循環引用問題。(注意,隻有容器對象才會産生循環引用的情況,比如清單、字典、使用者自定義類的對象、元組等。而像數字,字元串這類簡單類型不會出現循環引用。作為一種優化政策,對于隻包含簡單類型的元組也不在标記清除算法的考慮之列)
跟其名稱一樣,該算法在進行垃圾回收時分成了兩步,分别是:
-
- 标記階段,周遊所有的對象,如果是可達的(reachable),也就是還有對象引用它,那麼就标記該對象為可達;
- 清除階段,再次周遊對象,如果發現某個對象沒有标記為可達,則就将其回收。
對象之間會通過引用(指針)連在一起,構成一個有向圖,對象構成這個有向圖的節點,而引用關系構成這個有向圖的邊。從root object出發,沿着有向邊周遊對象,可達的(reachable)對象标記為活動對象,不可達(unreachable)的對象就是要被清除的非活動對象。所謂 root object,就是一些全局變量、調用棧、寄存器,這些對象是不可被删除的。
我們把小黑圈視為 root object,從小黑圈出發,對象 1 可達,那麼它将被标記,對象 2、3可間接可達也會被标記,而 4 和 5 不可達,那麼 1、2、3 就是活動對象,4 和 5 是非活動對象會被 GC 回收。
如下圖所示,在标記清除算法中,為了追蹤容器對象,需要每個容器對象維護兩個額外的指針,用來将容器對象組成一個雙端連結清單,指針分别指向前後兩個容器對象,友善插入和删除操作。Python解釋器(Cpython)維護了兩個這樣的雙端連結清單,一個連結清單存放着需要被掃描的容器對象,另一個連結清單存放着臨時不可達對象。
在圖中,這兩個連結清單分别被命名為“Object to Scan”和“Unreachable”。圖中例子是這麼一個情況:link1,link2,link3組成了一個引用環,同時link1還被一個變量A(其實這裡稱為名稱A更好)引用。link4自引用,也構成了一個引用環。
從圖中我們還可以看到,每一個節點除了有一個記錄目前引用計數的變量ref_count還有一個gc_ref變量,這個gc_ref是ref_count的一個副本,是以初始值為ref_count的大小。
gc啟動的時候,會逐個周遊“Object to Scan”連結清單中的容器對象,并且将目前對象所引用的所有對象的gc_ref減一。(掃描到link1的時候,由于link1引用了link2,是以會将link2的gc_ref減一,接着掃描link2,由于link2引用了link3,是以會将link3的gc_ref減一……)像這樣将“Objects to Scan”連結清單中的所有對象考察一遍之後,兩個連結清單中的對象的ref_count和gc_ref的情況如下圖所示。這一步操作就相當于解除了循環引用對引用計數的影響。
接着,gc會再次掃描所有的容器對象,如果對象的gc_ref值為0,那麼這個對象就被标記為GC_TENTATIVELY_UNREACHABLE,并且被移至“Unreachable”連結清單中。下圖中的link3和link4就是這樣一種情況。
如果對象的gc_ref不為0,那麼這個對象就會被标記為GC_REACHABLE。同時當gc發現有一個節點是可達的,那麼他會遞歸式的将從該節點出發可以到達的所有節點标記為GC_REACHABLE,這就是下圖中link2和link3所碰到的情形。
除了将所有可達節點标記為GC_REACHABLE之外,如果該節點目前在“Unreachable”連結清單中的話,還需要将其移回到“Object to Scan”連結清單中,下圖就是link3移回之後的情形。
第二次周遊的所有對象都周遊完成之後,存在于“Unreachable”連結清單中的對象就是真正需要被釋放的對象。如上圖所示,此時link4存在于Unreachable連結清單中,gc随即釋放之。
上面描述的垃圾回收的階段,會暫停整個應用程式,等待标記清除結束後才會恢複應用程式的運作。
标記清除的優點在于可以解決循環引用的問題,并且在整個算法執行的過程中沒有額外的開銷。缺點在于當執行标記清除時正常的程式将會被阻塞。另外一個缺點在于,标記清除算法在執行很多次數後,程式的堆空間會産生一些小的記憶體碎片。
分代回收(Generational garbage collector)
分代回收技術是上個世紀80年代初發展起來的一種垃圾回收機制,也是Java 垃圾回收的核心算法。分代回收是基于這樣的一個統計事實,對于程式,存在一定比例的記憶體塊的生存周期比較短;而剩下的記憶體塊,生存周期會比較長,甚至會從程式開始一直持續到程式結束。
生存期較短對象的比例通常在 80%~90% 之間。是以,簡單地認為:對象存在時間越長,越可能不是垃圾,應該越少去收集。這樣在執行标記-清除算法時可以有效減小周遊的對象數,進而提高垃圾回收的速度,是一種以空間換時間的方法政策。
-
- Python 将所有的對象分為 0,1,2 三代;
- 所有的建立對象都是 0 代對象;
- 當某一代對象經曆過垃圾回收,依然存活,就被歸入下一代對象。
那麼,按什麼标準劃分對象呢?是否随機将一個對象劃分到某個代即可呢?答案是否定的。實際上,對象分代裡頭也是有不少學問的,好的劃分标準可顯著提升垃圾回收的效率。
Python 内部根據對象存活時間,将對象分為 3 代,每個代都由一個 gc_generation 結構體來維護(定義于 Include/internal/mem.h):
struct gc_generation {
PyGC_Head head;
int threshold; /* collection threshold */
int count; /* count of allocations or collections of younger generations */
};
其中:
-
- head,可收集對象連結清單頭部,代中的對象通過該連結清單維護
- threshold,僅當 count 超過本閥值時,Python 垃圾回收操作才會掃描本代對象
- count,計數器,不同代統計項目不一樣
Python 虛拟機運作時狀态由 Include/internal/pystate.h 中的 pyruntimestate 結構體表示,它内部有一個 _gc_runtime_state ( Include/internal/mem.h )結構體,儲存 GC 狀态資訊,包括 3 個對象代。這 3 個代,在 GC 子產品( Modules/gcmodule.c ) _PyGC_Initialize 函數中初始化:
struct gc_generation generations[NUM_GENERATIONS] = {
/* PyGC_Head, threshold, count */
{{{_GEN_HEAD(0), _GEN_HEAD(0), 0}}, 700 0},
{{{_GEN_HEAD(1), _GEN_HEAD(1), 0}}, 10, 0},
{{{_GEN_HEAD(2), _GEN_HEAD(2), 0}}, 10, 0},
};
為友善讨論,我們将這 3 個代分别稱為:初生代、中生代 以及 老生代。當這 3 個代初始化完畢後,對應的 gc_generation 數組大概是這樣的:
每個 gc_generation 結構體連結清單頭節點都指向自己,換句話說每個可收集對象連結清單一開始都是空的,計數器字段 count 都被初始化為 0,而閥值字段 threshold 則有各自的政策。這些政策如何了解呢?
-
- Python 調用 _PyObject_GC_Alloc 為需要跟蹤的對象配置設定記憶體時,該函數将初生代 count 計數器加1,随後對象将接入初生代對象連結清單,當 Python 調用 PyObject_GC_Del 釋放垃圾對象記憶體時,該函數将初生代 count 計數器,1,_PyObject_GC_Alloc 自增 count 後如果超過閥值(700),将調用 collect_generations 執行一次垃圾回收( GC )。
- collect_generations 函數從老生代開始,逐個周遊每個生代,找出需要執行回收操作(,count>threshold )的最老生代。随後調用 collect_with_callback 函數開始回收該生代,而該函數最終調用 collect 函數。
- collect 函數處理某個生代時,先将比它年輕的生代計數器 count 重置為 0,然後将它們的對象連結清單移除,與自己的拼接在一起後執行 GC 算法,最後将下一個生代計數器加1。
于是:
-
- 系統每新增 701 個需要 GC 的對象,Python 就執行一次 GC 操作
- 每次 GC 操作需要處理的生代可能是不同的,由 count 和 threshold 共同決定
- 某個生代需要執行 GC ( count>hreshold ),在它前面的所有年輕生代也同時執行 GC
- 對多個代執行 GC,Python 将它們的對象連結清單拼接在一起,一次性處理
- GC 執行完畢後,count 清零,而後一個生代 count 加 1
下面是一個簡單的例子:初生代觸發 GC 操作,Python 執行 collect_generations 函數。它找出了達到閥值的最老生代是中生代,是以調用 collection_with_callback(1),1 是中生代在數組中的下标。
collection_with_callback(1) 最終執調用 collect(1) ,它先将後一個生代計數器加一;然後将本生代以及前面所有年輕生代計數器重置為零;最後調用 gc_list_merge 将這幾個可回收對象連結清單合并在一起:
最後,collect 函數執行标記清除算法,對合并後的連結清單進行垃圾回收。
這就是分代回收機制的全部秘密,它看似複雜,但隻需略加總結就可以得到幾條直白的政策:
-
- 每新增 701 個需要 GC 的對象,觸發一次新生代 GC
- 每執行 11 次新生代 GC ,觸發一次中生代 GC
- 每執行 11 次中生代 GC ,觸發一次老生代 GC (老生代 GC 還受其他政策影響,頻率更低)
- 執行某個生代 GC 前,年輕生代對象連結清單也移入該代,一起 GC
- 一個對象建立後,随着時間推移将被逐漸移入老生代,回收頻率逐漸降低
Python 中的 gc 子產品
gc 子產品是我們在Python中進行記憶體管理的接口,一般情況Python程式員都不用關心自己程式的記憶體管理問題,但是有的時候,比如發現自己程式存在記憶體洩露,就可能需要用到gc子產品的接口來排查問題。
有的 Python 系統會關閉自動垃圾回收,程式自己判斷回收的時機,據說 instagram 的系統就是這樣做的,整體運作效率提高了10%。
常用函數:
-
- set_debug(flags) :設定gc的debug日志,一般設定為gc.DEBUG_LEAK可以看到記憶體洩漏的對象。
- collect([generation]) :執行垃圾回收。會将那些有循環引用的對象給回收了。這個函數可以傳遞參數,0代表隻回收第0代的的垃圾對象、1代表回收第0代和第1代的對象,2代表回收第0、1、2代的對象。如果不傳參數,那麼會使用2作為預設參數。
- get_threshold() :擷取gc子產品執行垃圾回收的門檻值。傳回的是個元組,第0個是零代的門檻值,第1個是1代的門檻值,第2個是2代的門檻值。
- set_threshold(threshold0[, threshold1[, threshold2]) :設定執行垃圾回收的門檻值。
- get_count() :擷取目前自動執行垃圾回收的計數器。傳回一個元組。第0個是零代的垃圾對象的數量,第1個是零代連結清單周遊的次數,第2個是1代連結清單周遊的次數。
參考連結:
-
- 聊聊Python記憶體管理 (https://andrewpqc.github.io/2018/10/08/python-memory-management/)
- gc — 垃圾回收器接口 (https://docs.python.org/zh-cn/3/library/gc.html)
作者:錢魏Way
https://www.biaodianfu.com/garbage-collector.html
技術交流
目前開通了技術交流群,群友已超過2000人,添加時最好的備注方式為:來源+興趣方向,友善找到志同道合的朋友
方式、發送如下圖檔至微信,長按識别,背景回複:加群;
- 方式、微信搜尋公衆号:Python學習與資料挖掘,背景回複:加群