作者:小牛呼噜噜 | https://xiaoniuhululu.com
計算機内功、JAVA底層、面試相關資料等更多精彩文章在公衆号「小牛呼噜噜 」
目錄
- 概念常識
- Java 語言有哪些特點?
- JVM、JRE和JDK的關系
- 什麼是位元組碼?
- 為什麼說 Java 語言是“編譯與解釋并存”?
- Oracle JDK 和OpenJDK的差別
- Java 和 C++ 的差別?
- 什麼是JIT?
- Java關鍵字
- final finally finalize差別
- 聊聊this、super和static關鍵字
- Java 有沒有 goto
- 基礎文法
- Java 中的基本資料類型有哪些?
- 包裝類型的緩存機制
- 什麼是自動類型轉換、強制類型轉換?
- Math.round(11.5) 等于多少?Math.round(-11.5)等于多少
- 用最有效率的方法計算 2 乘以 8
- 運算符 | 和 ||,& 和 && 的差別
- break ,continue ,return 的差別及作用?
- 什麼是自動拆箱/裝箱?
- Integer a= 127 與 Integer b = 127相等嗎
- 自增自減運算
- switch 是否能作⽤在 byte/long/String上?
- 靜态變量和執行個體變量差別
- 靜态變量與普通變量差別
- 面向對象
- 面向對象和面向過程的差別
- 面向對象的3大特性是什麼?
- 抽象類和接口的差別是什麼?
- 普通類和抽象類有哪些差別?
- 重載(overload)和重寫(override)的差別?
- 面向對象五大基本原則是什麼
- == 和 equals 的差別是什麼
- 為什麼重寫 equals 時必須重寫 hashCode ⽅法
- Java是值傳遞,還是引用傳遞?
- 深拷貝、淺拷貝、引用拷貝?
- Java 建立對象有哪⼏種⽅式
- String相關
- 字元型常量和字元串常量的差別
- String 是最基本的資料類型嗎
- 什麼是字元串常量池?
- String、StringBuffer、StringBuilder 的差別
- String s = new String("abc")建立了幾個對象 ?
- String str="abc"與 String str=new String("abc")一樣嗎?
- String有哪些特性
- String 類的常用方法都有那些?
- 在使用 HashMap 的時候,用 String 做 key 有什麼好處?
- 異常
- Exception 和 Error 有什麼差別?
- try-catch-finally 如何使用?
- IO
- Java 中 IO 流分為幾種?
- BIO,NIO,AIO 有什麼差別?
- 既然有了位元組流,為什麼還要有字元流?
- 擴充:重要知識點
- 什麼是反射?
- 聊聊你認識的注解?
- 動态代理的原理
概念常識
Java 語言有哪些特點?
- 簡單易學
Java 會讓你的工作變得更加輕松,使你把關注點放在主要業務邏輯上
尤其是Java語言沒有指針,并提供了自動的垃圾回收機制,使得程式員不必為記憶體管理而擔憂
- 面向對象
具有代碼擴充,代碼複用等功能,其三大核心概念:封裝,繼承,多态
詳情見:https://mp.weixin.qq.com/s/Q1hABlF4kBhcyf3vnLrtFQ
- 支援多平台
在一個平台上編寫的任何應用程式都可以輕松移植到另一個平台上, 是Java 虛拟機實作平台無關性
- 安全性
Java 被編譯成位元組碼,由 Java 運作時環境解釋。編譯後會将所有的代碼轉換為位元組碼,人類無法讀取。它使開發無病毒,無篡改的系統/應用成為可能
- 健壯性
Java 有強大的記憶體管理功能,在編譯和運作時檢查代碼,它有助于消除錯誤。
- 支援多線程
多線程是指允許一個應用程式同時存在兩個或兩個以上的線程,用于支援事務并發和多任務處理。
C++ 語言沒有内置的多線程機制,是以必須調用作業系統的多線程功能來進行多線程程式設計,而 Java 語言卻提供了多線程支援
Java除了内置的多線程技術之外,還定義了一些類、方法等來建立和管理使用者定義的多線程。
- 動态性
它具有适應不斷變化的環境的能力,Java程式需要的類能夠動态地被載入到運作環境,也可以通過網絡來載入所需要的類。它能夠支援動态記憶體配置設定,進而減少了記憶體浪費,提高了應用程式的性能。
- 分布式
Java 提供的功能有助于建立分布式應用。使用遠端方法調用(RMI),程式可以通過網絡調用另一個程式的方法并擷取輸出。您可以通過從網際網路上的任何計算機上調用方法來通路檔案。這是革命性的一個特點,對于當今的網際網路來說太重要了。
- 高性能
Java 最黑的科技就是位元組碼程式設計,Java 代碼編譯成的位元組碼可以輕松轉換為本地機器代碼。
如果解釋器速度不慢,Java可以在運作時直接将目标代碼翻譯成機器指令,翻譯目标代碼的速度與C/C++的性能沒什麼差別。通過 JIT 即時編譯器來實作高性能。
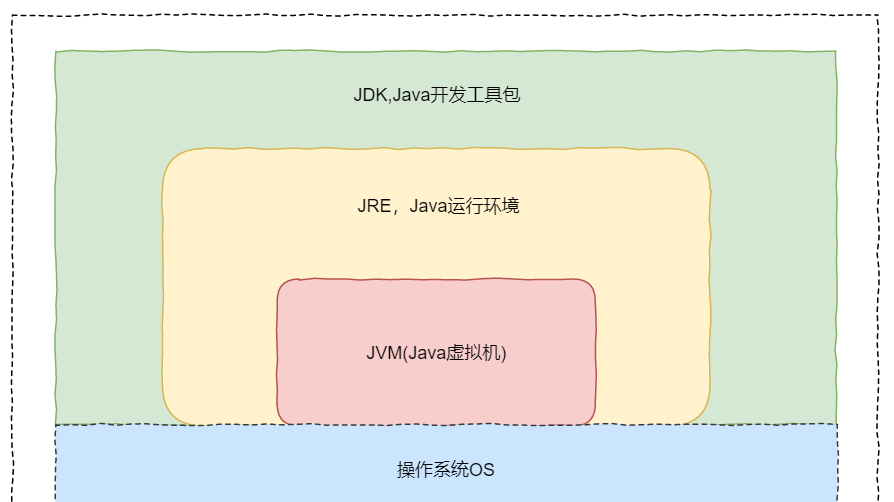
JVM、JRE和JDK的關系
- JVM
Java 虛拟機(JVM)是運作 Java 位元組碼的虛拟機,Java程式需要運作在虛拟機上,不同的平台有自己的虛拟機,JVM在執行位元組碼時,把位元組碼解釋成具體平台上的機器指令執行。這就是Java的能夠“一次編譯,到處運作”的原因。是以Java語言可以實作跨平台。
位元組碼和不同系統的 JVM 實作是 Java 語言“一次編譯,随處可以運作”的關鍵所在。
隻要滿足 JVM 規範,任何公司、組織或者個人都可以開發自己的專屬 JVM。
- JRE
JRE(Java Runtime Environment)是 Java 運作時環境。包括Java虛拟機和Java程式所需的核心類庫等。核心類庫主要是java.lang包:包含了運作Java程式必不可少的系統類,如基本資料類型、基本數學函數、字元串處理、線程、異常處理類等,但是系統預設加載這個包,不能用于建立新程式。
- JDK
Java Development Kit是提供給Java開發人員使用的,其中包含了Java的開發工具,也包括了JRE。是以安裝了JDK,就無需再單獨安裝JRE了。其中的開發工具:編譯工具(javac.exe),打包工具(jar.exe)等,它能夠建立和編譯程式。
什麼是位元組碼?
位元組碼:Java源代碼編譯後産生的檔案(即擴充名為.class的檔案)。
.java源碼是給人類讀的,而.class位元組碼隻面向JVM(Java虛拟機)
采用位元組碼的好處:
- Java語言通過位元組碼的方式,在一定程度上解決了傳統解釋型語言執行效率低的問題,同時又保留了解釋型語言可移植的特點。是以Java程式運作時比較高效的(但和無需GC的語言 c、c++、rust等的運作效率還是有所差距)
- 由于位元組碼并不針對一種特定的機器,是以,Java 程式無須重新編譯便可在多種不同作業系統的計算機上運作。
一般Java程式運作的流程:
Java源代碼---->編譯器---->jvm可執行的Java位元組碼(即虛拟指令)---->jvm---->jvm中解釋器----->機器可執行的二進制機器碼---->程式運作

為什麼說 Java 語言是“編譯與解釋并存”?
由于計算機隻看得懂0100011機器碼,語言像C語言,是給人看的。我們通過這些語言編寫出來的代碼,需要先轉換成機器碼,然後計算機才能去執行。
- 編譯型 :先将源代碼一次性轉換成另一種相對來說更低級的語言(位元組碼,彙編,機器碼...),計算機再去執行。常見的編譯性語言有 C、C++、Go、Rust 等等。
注意這邊的機器碼 是代碼對應的平台計算機的機器碼
- 解釋型 :解釋器動态将代碼逐句解釋(interpret)為機器碼(編譯器自身的機器碼)并運作(邊解釋邊執行)。常見的解釋性語言有 Python、JavaScript、PHP 等等。
為什麼經常說java是解釋性語言也是編譯型語言?
JVM的類加載器首先加載位元組碼檔案,然後通過解釋器逐行解釋執行,每次執行都需要加載、解析,速度慢,還有熱點代碼重複加載問題。是以引進了JIT編譯器(運作時編譯),JIT完成一次編譯後會将位元組碼對應的機器碼儲存下來,下次直接執行。
解釋和編譯都隻是程式從源碼到運作時的一種動作,跟語言本身無關,是以我們無需過于糾結這個問題!
Oracle JDK 和OpenJDK的差別
Java最早由SUN公司(Sun Microsystems,發起于美國斯坦福大學,SUN是Stanford University Network的縮寫)發明,2006年SUN公司将Java開源,此時的JDK即為OpenJDK。
OpenJDK是Java SE的開源實作,他由SUN和Java社群提供支援,2009年Oracle收購了Sun公司,自此Java的維護方之一的SUN也變成了Oracle。
大多數JDK都是在OpenJDK的基礎上編寫實作的,比如IBM J9,Azul Zulu,Azul Zing和Oracle JDK。幾乎現有的所有JDK都派生自OpenJDK,
他們之間不同的是許可證:
- OpenJDK根據許可證GPL v2釋出。
- Oracle JDK根據Oracle二進制代碼許可協定獲得許可。
Oracle JDK 比 OpenJDK 更穩定。在響應性和JVM性能方面,Oracle JDK與OpenJDK相比提供了更好的性能
OpenJDK和Oracle JDK的代碼幾乎相同,但Oracle JDK有更多的類和一些錯誤修複。
OpenJDK 是一個參考模型并且是完全開源的,
但是Oracle JDK是OpenJDK的一個實作,并不是完全開源的
Java 和 C++ 的差別?
Java 和 C++ 都是面向對象的語言,都支援封裝、繼承和多态,但是它們還是有挺多不相同:
- Java 不提供指針來直接通路記憶體,程式記憶體更加安全
- Java 的類是單繼承的,C++ 支援多重繼承;雖然 Java 的類不可以多繼承,但是接口可以多繼承。
- Java 有自動記憶體管理垃圾回收機制(GC),不需要程式員手動釋放無用記憶體。
- 等等
什麼是JIT?
JIT是just in time的縮寫,也就是即時編譯。通過JIT技術,能夠做到Java程式執行速度的加速。
Java通過編譯器javac先将源程式編譯成與平台無關的Java位元組碼檔案(.class),再由JVM解釋執行位元組碼檔案,進而做到平台無關。 但是,有利必有弊。對位元組碼的解釋執行過程實質為:JVM先将位元組碼翻譯為對應的機器指令,然後執行機器指令。很顯然,這樣經過解釋執行,其執行速度必然不如直接執行二進制位元組碼檔案。
而為了提高執行速度,便引入了 JIT 技術。當JVM發現某個方法或代碼塊運作特别頻繁的時候,就會認為這是“熱點代碼”(Hot Spot Code)。然後JIT會把部分“熱點代碼”編譯成本地機器相關的機器碼,并進行優化,然後再把編譯後的機器碼緩存起來,以備下次使用。
Java關鍵字
final finally finalize差別
final可以修飾類、變量、方法
- 修飾類表示該類不能被繼承
- 修飾方法表示該方法不能被重寫
- 修飾變量表示該變量是一個常量,不可變,在編譯階段會存入常量池中
finally一般作用在try-catch代碼塊中,在處理異常的時候,通常我們将一定要執行的代碼方法finally代碼塊
中,表示不管是否出現異常,該代碼塊都會執行,一般用來存放一些關閉資源的代碼。
finalize是一個方法,屬于Object類的一個方法,而Object類是所有類的父類,該方法一般由垃圾回收器來調
用,當我們調用System.gc() 方法的時候,由垃圾回收器調用finalize(),回收垃圾,一個對象是否可回收的
最後判斷。
聊聊this、super和static關鍵字
- this關鍵字
this表示目前對象的引用:
this.屬性 差別成員變量和局部變量
this.() 調用本類的某個方法
this() 表示調用本類構造方法,隻能用在構造方法的第一行語句。
this關鍵字隻能出現在非static修飾的代碼中
public class Member {
String name;
public void setName(String name) {
this.name = name;
}
}
- super關鍵字
super可以了解為是指向自己超(父)類對象的一個"指針",而這個超類指的是離自己最近的一個父類。:
super.屬性 表示父類對象中的成員變量
super.方法()表示父類對象中定義的方法
super() 表示調用父類構造方法
可以指定參數,比如super("Nanjin");
任何一個構造方法的第一行預設是super();
可以寫上,如果未寫,會隐式調用super();
super()隻能在構造方法的第一行使用。
this()和super()都隻能在構造的第一行出現,是以隻能選擇其一。
寫了this()就不會隐式調用super()。
super 關鍵字在子類中顯式調用父類中被覆寫的非靜态成員方法和成員變量
class Father {
void message() {
System.out.println("This is Father");
}
}
class Son extends Father {
void message() {
System.out.println("This is son");
}
void display() {
message();
super.message();
}
}
class Main {
public static void main(String args[]) {
Son s = new Son();
s.display();
}
}
結果:
This is son
This is father
- static關鍵字
static的主要意義是在于建立獨立于具體對象的域變量或者方法。以緻于即使沒有建立對象,也能使用屬性和調用方法!
static修飾的變量稱之為靜态變量
被static修飾的變量或者方法是獨立于該類的任何對象,即這些變量和方法不屬于任何一個執行個體對象,而是被類的執行個體對象所共享。
static修飾的方法稱之為靜态方法
靜态方法屬于class而不屬于執行個體,是以,靜态方法内部,無法通路this變量,也無法通路執行個體字段,它隻能通路靜态字段
static修飾的代碼塊叫做靜态代碼塊。
被static修飾的變量或者方法是優先于對象存在的,也就是說當一個類加載完畢之後,即便沒有建立對象,也可以去通路。用法:“類.靜态變量”
- 能否在static環境中通路非static變量?
不能, static方法中不能使用this和super關鍵字,不能調用非static方法,隻能通路所屬類的靜态成員和靜态方法,因為當static方法被調用時,這個類的對象可能還沒被建立,即使已經被建立了,也無法确定調用哪個對象的方法。同理,static方法也不能通路非static類型的變量。 - this與super關鍵字的差別
- this 表示目前對象的引用,可以了解為指向對象本身的一個"指針",但是JAVA中是沒有指針這個概念的。
- super 表示自己超(父)類對象的引用,可以了解為是指向自己超(父)類對象的一個指針,而這個超類指的是離自己最近的一個父類。
- super()在子類中調用父類的構造方法,this()在本類内調用本類的其它構造方法。
- this和super不能同時出現在一個構造函數裡面,因為this必然會調用其它的構造函數,其它的構造函數必然也會有super語句的存在,是以在同一個構造函數裡面有相同的語句,就失去了語句的意義,編譯器也不會通過。
相同點:
super()和this()均需放在構造方法内第一行。
this()和super()都指的是對象,是以,均不可以在static環境中使用。包括:static變量,static方法,static語句塊。
拓展:https://mp.weixin.qq.com/s/tsbDfyYLqr3ctzwHirQ8UQ
Java 有沒有 goto
goto 是 Java 中的保留字,在目前版本的 Java 中沒有使用。
基礎文法
Java 中的基本資料類型有哪些?
Java 中有 8 種基本資料類型,分别為:
| 基本類型 | 位數 | 位元組 | 預設值 | 包裝類 | 取值範圍 |
|---|---|---|---|---|---|
| byte | 8 | 1 | Byte | -128 ~ 127 | |
| short | 16 | 2 | Short | -32768 ~ 32767 | |
| int | 32 | 4 | Integer | -2147483648 ~ 2147483647 | |
| long | 64 | 8 | 0L | Long | -9223372036854775808 ~ 9223372036854775807 |
| char | 16 | 2 | 'u0000' | Character | 0 ~ 65535 |
| float | 32 | 4 | 0f | Float | 1.4E-45 ~ 3.4028235E38 |
| double | 64 | 8 | 0d | Double | 4.9E-324 ~ 1.7976931348623157E308 |
| boolean | 1 | false | Boolean | true、false |
其中:
char a = 'hello'; 單引号
String a = "hello" ;雙引号
包裝類型的緩存機制
Java 基本資料類型的包裝類型的大部分都用到了緩存機制來提升性能:
Byte,Short,Integer,Long
這 4 種包裝類預設建立了數值 [-128,127] 的相應類型的緩存資料,如果超出對應範圍仍然會去建立新的對象。
另外兩種浮點數類型的包裝類
Float,Double
并沒有實作緩存機制。
Integer i1 = 10;
Integer i2 = 10;
Integer i3 = 200;
Integer i4 = 200;
System.out.println(i1 == i2);// 輸出 true
System.out.println(i3 == i4);// 輸出 false
什麼是自動類型轉換、強制類型轉換?
Java 數值型變量經常需要進行互相轉換,當把⼀個表數
範圍⼩
的數值或變量直接賦給另⼀個表 數
範圍⼤
的變量時,可以進⾏
⾃動類型轉換
,即
隐式轉換
long l = 100;
int i = 200;
long ll = i;
反之,需要
強制類型轉換(顯式轉換)
short s = 199;
int i = s;// 199
double d = 10.24;
long ll = (long) d;// 10, 精度丢失
自動類型轉換規則如下:
- 數值型資料的轉換:byte→short→int→long→float→double。
- 字元型轉換為整型:char→int。
一些常見的易錯題:
-
float f=3.4;
3.4 是單精度數,将雙精度型(double)指派給浮點型(float)屬于下轉型會造成精度損失,是以需要強制類型轉換或 者寫成float f =(float)3.4;
float f =3.4F;
-
short s1 = 1; s1 = s1 + 1;
short s1 = 1; s1 += 1;
對于short s1 = 1; s1 = s1 + 1;
編譯出錯,由于 1 是 int 類型,是以 s1+1 運算結果也是 int型, 需要強制轉換類型才能指派給 short 型。
⽽
可以正确編譯,因為 s1+= 1;相當于short s1 = 1; s1 += 1;
其中有隐含的強 制類型轉換。s1 = (short(s1 + 1);
-
int count = 100000000; int price = 1999; long totalPrice = count * price;
不正确,編譯沒任何問題,但結果卻輸出的是負數,這是因為兩個 int 相乘得到的結果是 int, 相乘的結果超出了 int 的代表範圍。這種情況,一般把第一個資料轉換成範圍大的資料類型再和其他的資料進行運算。
Math.round(11.5) 等于多少?Math.round(-11.5)等于多少
四舍五入的原理是在參數上加 0.5 然後進行下取整。
- Math.round(11.5)的傳回值是 12
- Math.round(-11.5)的傳回值是-11
用最有效率的方法計算 2 乘以 8
2 << 3
(左移 3 位相當于乘以 2 的 3 次方,右移 3 位相當于除以 2 的 3 次方)。
運算符 | 和 ||,& 和 && 的差別
| 和 & 定義為位運算符。
|| 和 && 定義為邏輯運算符,
& 按位與操作,按二進制位進行"與"運算。運算規則:(有 0 則為 0)
| 按位或運算符,按二進制位進行"或"運算。運算規則:(有 1 則為 1)
A = 0011 1100
B = 0000 1101
-----------------
A&B = 0000 1100
A | B = 0011 1101
而&&運算符是短路與運算。當且僅當兩個為真,條件才真。如果&&左邊的表達式的值是 false,右邊的表達式會被直接短路掉,不會進行運算。很多時候我們可能都需要⽤&&⽽不是&。
||運算符是短路或運算,短路原理和&&同理
break ,continue ,return 的差別及作用?
- break 跳出整個循環,不再執⾏循環( 結束目前的循環體 )
- continue 跳出本次循環,繼續執⾏下次循環( 結束正在執⾏的循環 進⼊下⼀個循環條件 )
- return 程式傳回,不再執⾏下⾯的代碼( 結束目前的⽅法 直接傳回 )
什麼是自動拆箱/裝箱?
裝箱 :将基本類型⽤它們對應的引⽤類型包裝起來;
拆箱 :将包裝類型轉換為基本資料類型;
Java可以⾃動對基本資料類型和它們的包裝類進⾏裝箱和拆箱。
我們來看一下基本類型跟封裝類型之間的對應關系:
| 資料類型 | 封裝類 |
|---|---|
| byte | Byte |
| short | Short |
| int | Integer |
| long | Long |
| float | Float |
| double | Double |
| char | Character |
| boolean | Boolean |
我們來看一個例子:
// 自動裝箱
1. Integer a = 100;
// 自動拆箱
2. int b = a;
自動裝箱,相當于Java編譯器替我們執行了 Integer.valueOf(XXX);
自動拆箱,相當于Java編譯器替我們執行了Integer.intValue(XXX);
Integer a= 127 與 Integer b = 127相等嗎
對于對象引用類型:比較的是對象的記憶體位址。
對于基本資料類型:比較的是值。
如果整型字面量的值在-128到127之間,那麼自動裝箱時不會new新的Integer對象,而是直接引用常量池中的Integer對象,超過範圍 a1==b1的結果是false
public static void main(String[] args) {
Integer a = new Integer(3);
Integer b = 3; // 将3自動裝箱成Integer類型
int c = 3;
System.out.println(a == b); // false 兩個引用沒有引用同一對象
System.out.println(a == c); // true a自動拆箱成int類型再和c比較
System.out.println(b == c); // true
Integer a1 = 128;
Integer b1 = 128;
System.out.println(a1 == b1); // false
Integer a2 = 127;
Integer b2 = 127;
System.out.println(a2 == b2); // true
}
自增自減運算
++和--運算符可以放在變量之前,也可以放在變量之後。
當運算符放在變量之前時(字首),先⾃增/減,再指派;當運算符放在變量之後時(字尾),先賦 值,再⾃增/減。
int i = 1;
i = i++;
System.out.println(i);
結果為1
如果将
i++ 換成++i
, 則結果為:2
switch 是否能作⽤在 byte/long/String上?
Java5 以前 switch(expr)中,expr 隻能是 byte、short、char、int。
從 Java 5 開始,Java 中引⼊了枚舉類型, expr 也可以是 enum 類型。
從 Java 7 開始,expr還可以是字元串(String),但是長整型(long)在⽬前所有的版本中都是不可 以的。
靜态變量和執行個體變量差別
靜态變量: 靜态變量由于不屬于任何執行個體對象,屬于類的,是以在記憶體中隻會有一份,在類的加載過程中,JVM隻為靜态變量配置設定一次記憶體空間。
執行個體變量: 每次建立對象,都會為每個對象配置設定成員變量記憶體空間,執行個體變量是屬于執行個體對象的,在記憶體中,建立幾次對象,就有幾份成員變量。
靜态變量與普通變量差別
static變量也稱作靜态變量,靜态變量和非靜态變量的差別是:靜态變量被所有的對象所共享,在記憶體中隻有一個副本,它當且僅當在類初次加載時會被初始化。
而非靜态變量是對象所擁有的,在建立對象的時候被初始化,存在多個副本,各個對象擁有的副本互不影響。
面向對象
面向對象和面向過程的差別
- 面向過程:
- ⾯向過程就是分析出解決問題所需要的步驟,然後⽤函數把這些步驟⼀步⼀ 步實作,使⽤的時候再⼀個⼀個的⼀次調⽤就可以
- 優點:性能比面向對象高,因為類調用時需要執行個體化,開銷比較大,比較消耗資源;比如單片機、嵌入式開發、Linux/Unix等一般采用面向過程開發,性能是最重要的因素。
- 缺點:沒有面向對象易維護、易複用、易擴充
- 面向對象:
- ⾯向對象,把構成問題的事務分解成各個對象,⽽建⽴對象的⽬的也不是為 了完成⼀個個步驟,⽽是為了描述某個事件在解決整個問題的過程所發⽣的⾏為。 ⽬的是 為了寫出通⽤的代碼,加強代碼的重⽤,屏蔽差異性
- 優點:易維護、易複用、易擴充,由于面向對象有封裝、繼承、多态性的特性,可以設計出低耦合的系統,使系統更加靈活、更加易于維護
- 缺點:性能比面向過程低
面向對象的3大特性是什麼?
- 封裝
封裝把客觀事物封裝成抽象的類,并且類可以把自己的資料和方法隻讓可信的類或者對象操作,對不可信的進行資訊隐藏。換句話說就是 把一個對象的屬性私有化,同時提供一些可以被外界通路的屬性的方法,如果屬性不想被外界通路,我們大可不必提供方法給外界通路。
- 繼承
**繼承 **就是子類繼承父類的特征和行為,使得子類對象(執行個體)具有父類的執行個體域和方法,或子類從父類繼承方法,使得子類具有父類相同的行為。
在 Java 中通過
extends 關鍵字
可以申明一個類是從另外一個類繼承而來的,一般形式如下:
class 父類 {
}
class 子類 extends 父類 {
}
繼承概念的實作方式有二類:
實作繼承
與
接口繼承
- 實作繼承是指直接使用基類的屬性和方法而無需額外編碼的能力
- 接口繼承是指僅使用屬性和方法的名稱、但是子類必須提供實作的能力
- 一般我們繼承基本類和抽象類用 extends 關鍵字,實作接口類的繼承用 implements 關鍵字。
注意點:
- 通過繼承建立的新類稱為“子類”或“派生類”,被繼承的類稱為“基類”、“父類”或“超類”。
- 繼承的過程,就是從一般到特殊的過程。要實作繼承,可以通過“繼承”(Inheritance)和“組合”(Composition)來實作。
- ⼦類擁有⽗類對象所有的屬性和⽅法(包括私有屬性和私有⽅法),但是⽗類中的私有屬 性和⽅法⼦類是⽆法通路,隻是擁有
- 子類可以擁有自己的屬性和方法, 即⼦類可以對⽗類進⾏擴充。
- 子類可以重寫覆寫父類的方法。
- JAVA 隻支援單繼承,即一個子類隻允許有一個父類,但是可以實作多級繼承,及子類擁有唯一的父類,而父類還可以再繼承。
使用
implements 關鍵字
可以變相的使java具有多繼承的特性,使用範圍為類繼承接口的情況,可以同時繼承多個接口(接口跟接口之間采用逗号分隔)。
# implements 關鍵字
public interface A {
public void eat();
public void sleep();
}
public interface B {
public void show();
}
public class C implements A,B {
}
- 多态
同一個行為具有多個不同表現形式或形态的能力就是 多态。網上的争論很多,筆者個人認同網上的這個觀點:重載也是多态的一種表現,不過多态主要指運作時多态。
Java 多态可以分為
重載式多态
和
重寫式多态
- 重載式多态,也叫編譯時多态。編譯時多态是靜态的,主要是指方法的重載overload,它是根據參數清單的不同來區分不同的方法。通過編譯之後會變成兩個不同的方法,在運作時談不上多态。也就是說這種多态再編譯時已經确定好了。
- 重寫式多态,也叫運作時多态。運作時多态是動态的,主要指繼承父類和實作接口override時,可使用
父類引用指向子類對象實作
這種多态通過
動态綁定(dynamic binding)
技術來實作,是指在
執行期間
判斷所引用對象的實際類型,根據其實際的類型調用其相應的方法。也就是說,
隻有程式運作起來
,你才知道調用的是哪個子類的方法。 這種多态可通過
函數的重寫以及向上轉型
來實作。
多态存在的三個必要條件(實作方式):
- 繼承
- 重寫
- 父類引用指向子類對象:
Parent p = new Child();
關于繼承如下 3 點請記住:
- 子類擁有父類非 private 的屬性和方法。
- 子類可以擁有自己屬性和方法,即子類可以對父類進行擴充。
- 子類可以用自己的方式實作父類的方法。
拓展: https://mp.weixin.qq.com/s/Q1hABlF4kBhcyf3vnLrtFQ
抽象類和接口的差別是什麼?
相同點:
- 都不能被執行個體化
- 都包含抽象方法,其子類都必須覆寫這些抽象方法
- 都位于繼承的頂端,用于被其他實作或繼承
不同點在于:
- 接口, 通常以interface來聲明
public interface UserIF() {
//定義
}
- 抽象類, 通常以abstract來聲明
public abstract class Employee {
private String name;
private String address;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getAddress() {
return address;
}
public void setAddress(String address) {
this.address = address;
}
// 無參構造
public Employee() {
}
// 有參構造
public Employee(String name, String address) {
this.name = name;
this.address = address;
}
// 抽象的方法
public abstract Integer num(Integer a, Integer b);
}
-
抽象類中可以進行方法的定義和實作; 在接口中,隻允許進行方法的定義,不允許有方法的實作
由于Java 8 可以用 default 關鍵字在接口中定義預設方法,是以2者都可以有預設實作的方法
- 接口中的成員變量隻能是 public static final 類型的,不能被修改且必須有初始值,而抽象類的成員變量預設 default,可在子類中被重新定義,也可被重新指派
- 變量:接口中定義的變量隻能是公共的靜态常量,抽象類中的變量是普通變量。
- Java中隻能
extends
implements
- 抽象級别不同:抽象程度由高到低依次是
接口 > 抽象類 > 類
-
類如果要實作一個接口,它必須要實作接口聲明的所有方法。但是,類可以不實作
抽象類聲明的所有方法,當然,在這種情況下,類也必須得聲明成是抽象的。
- Java 接口中聲明的變量預設都是 static 和 final 的。抽象類可以包含非 final 的變量
補充:抽象類能使用 final 修飾嗎?
不能,定義抽象類就是讓其他類繼承的,如果定義為 final 該類就不能被繼承,這樣彼此就會産生沖突,是以 final 不能修飾抽象類
普通類和抽象類有哪些差別?
普通類不能包含抽象方法,抽象類可以包含抽象方法。
抽象類不能直接執行個體化,普通類可以直接執行個體化。
重載(overload)和重寫(override)的差別?
⽅法的重載和重寫都是實作多态的⽅式,差別在于前者實作的是編譯時的多态性,⽽後者實
現的是運⾏時的多态性。
重載發⽣在⼀個類中,同名的⽅法如果有不同的參數清單(參數類型不同、參數個數不同
或者⼆者都不同)則視為重載;
重寫發⽣在⼦類與⽗類之間,重寫要求⼦類被重寫⽅法與⽗類被重寫⽅法有相同的傳回類
型,⽐⽗類被重寫⽅法更好通路,不能⽐⽗類被重寫⽅法聲明更多的異常(⾥⽒代換原
則)。
⽅法重載的注意事項:
- ⽅法名⼀緻,參數清單中參數的順序,類型,個數不同。
- 重載與⽅法的傳回值⽆關,存在于⽗類和⼦類,同類中。
- 可以抛出不同的異常,可以有不同修飾符。
面向對象五大基本原則是什麼
- 單一職責原則SRP(Single Responsibility Principle)
類的功能要單一,不能包羅萬象,跟雜貨鋪似的。
- 開放封閉原則OCP(Open-Close Principle)
一個子產品對于拓展是開放的,對于修改是封閉的,想要增加功能熱烈歡迎,想要修改,哼,一萬個不樂意。
- 裡式替換原則LSP(the Liskov Substitution Principle LSP)
子類可以替換父類出現在父類能夠出現的任何地方。比如你能代表你爸去你外婆家幹活。哈哈~~
- 依賴倒置原則DIP(the Dependency Inversion Principle DIP)
高層次的子產品不應該依賴于低層次的子產品,他們都應該依賴于抽象。抽象不應該依賴于具體實作,具體實作應該依賴于抽象。就是你出國要說你是中國人,而不能說你是哪個村子的。比如說中國人是抽象的,下面有具體的xx省,xx市,xx縣。你要依賴的抽象是中國人,而不是你是xx村的。
- 接口分離原則ISP(the Interface Segregation Principle ISP)
設計時采用多個與特定客戶類有關的接口比采用一個通用的接口要好。就比如一個手機擁有打電話,看視訊,玩遊戲等功能,把這幾個功能拆分成不同的接口,比在一個接口裡要好的多。
== 和 equals 的差別是什麼
- 關于 ==
== 比較的是變量(棧)記憶體中存放的對象的(堆)記憶體位址,用來判斷兩個對象的位址是否相同,即是否是指相同一個對象。比較的是真正意義上的指針操作。
對于基本類型和引用類型 == 的作用效果是不同的:
- 基本類型:比如 byte, short, char, int, long, float, double, boolean, 他們比較的是他們的值;
- 引用類型:比較的是他們在記憶體中的存放位址,更準确的說,是堆記憶體位址
如果是具體的阿拉伯數字的比較,值相等則為true,如:
int a=10 與 long b=10L 與 double c=10.0
都是相同的(為true),因為他們都指向位址為10的堆。
- 關于 equals
equals一般意義上是比較的是兩個對象的内容是否相等,如String類中equals。但是由于所有的類都是繼承自java.lang.Object類的,是以适用于所有對象,如果沒有對該方法進行重寫的話,調用的仍然是Object類中的方法,而Object中的equals方法傳回的卻是==的判斷。
String s="abcd"
是一種非常特殊的形式,和new 有本質的差別。
它是java中唯一不需要new 就可以産生對象的途徑。以
String s="abcd";
形式指派在java中叫直接量,它是在常量池中而不是象new一樣放在壓縮堆中。這種形式的字元串,在JVM内部發生字元串拘留,即當聲明這樣的一個字元串後,JVM會在常量池中先查找有有沒有一個值為
"abcd"
的對象,如果有,就會把它賦給目前引用.即原來那個引用和現在這個引用指點向了同一對象,如果沒有,則在常量池中新建立一個"abcd",下一次如果有
String s1 = "abcd"
;又會将s1指向"abcd"這個對象,即以這形式聲明的字元串,隻要值相等,任何多個引用都指向同一對象.
而
String s = new String("abcd");
和其它任何對象一樣.每調用一次就産生一個對象,隻要它們調用。
補充:任何非空的引用值X,x.equals(null)的傳回值一定為false 。
來看個例子:
public class test1 {
public static void main(String[] args) {
String a = new String("abcd"); // a 為一個引用
String b = new String("abcd"); // b為另一個引用,對象的内容一樣
String aa = "abcd"; // 放在常量池中
String bb = "abcd"; // 從常量池中查找
if (aa == bb) // true
System.out.println("aa==bb");
if (a == b) // false,非同一對象
System.out.println("a==b");
if (a.equals(b)) // true
System.out.println("aEQb");
}
}
詳情見:https://mp.weixin.qq.com/s/zbhftxnvnoTFY-RSegTjRQ
為什麼重寫 equals 時必須重寫 hashCode ⽅法
- 什麼是HashCode?
hashCode() 的作⽤是擷取哈希碼,也稱為散列碼;它實際上是傳回⼀個 int 整數,定義在 Object 類中,這個⽅法通常⽤來将對象的記憶體位址轉換為整數之後傳回。這也意味着Java中的任何類都包含有hashCode()函數。
- 為什麼要有 hashCode ?
哈希碼主要在哈希表這類集合映射的時候⽤到,哈希表存儲的是鍵值對(key-value),它的特點 是:能根據“鍵”快速的映射到對應的“值”。 比如HashMap怎麼把key映射到對應的value上呢?⽤的就是哈希取餘法,也就是拿哈希碼和存 儲元素的數組的長度取餘,擷取key對應的value所在的下标位置
- 為什麼重寫 quals 時必須重寫 hashCode ⽅法?
- 如果兩個對象相等,則hashcode一定也是相同的
- 兩個對象相等,對兩個對象分别調用equals方法都傳回true
- 兩個對象有相同的hashcode值,它們也不一定是相等的(哈希碰撞)
hashCode()
的預設⾏為是對堆上的對象産⽣獨特值,如果沒有重寫
hashCode()
,則該class 的 兩個對象⽆論如何都不會相等(即使這兩個對象指向相同的資料)。因 此,
equals()
⽅法被覆寫過,則
hashCode()
⽅法也必須被覆寫。
Java是值傳遞,還是引用傳遞?
傳遞的過程的參數一般有2種情況值傳遞和引用傳遞。
- 值傳遞:調用函數時将實際參數複制一份傳遞到函數中,函數内部對參數内部進行修改不會影響到實際參數,即
建立副本,不會影響原生對象
- 引用傳遞 :方法接收的是實際參數所引用的位址,不會建立副本,對形參的修改将影響到實參,即
不建立副本,會影響原生對象
在Java中有2種資料類型,其中主要有基本資料類型和引用資料類型,除了8中基本資料類型以外都是引用資料類型,8中基本資料類型分别是
byte,short,int,long,char,boolean,float,double
** Java隻有值傳遞**,參數如果是基本資料類型,複制的是具體值;如果參數是引用類型,把位址當成值,複制的是位址;還有String類是一個非常特殊的類,她是不可變的。
詳情可見:https://mp.weixin.qq.com/s/6qRspyLAsoBxttGwGtxsAA
深拷貝、淺拷貝、引用拷貝?
- 引用拷貝:引用拷貝會在棧上生成一個新的對象引用位址,但是兩個最終指向依然是堆中同一個對象
- 淺拷貝:淺拷貝會在堆上建立一個新對象,新對象和原對象本身沒有任何關系,新對象和原對象不等,但是新對象的屬性和老對象相同。
具體可以看如下差別:
- 如果屬性是基本類型(int,double,long,boolean等),拷貝的就是基本類型的值;
- 如果屬性是引用類型,拷貝的就是記憶體位址(即複制引用但不複制引用的對象),也就是說拷貝對象和原對象共用同一個内部對象。是以如果其中一個對象改變了這個位址,就會影響到另一個對象。
- 深拷貝 :深拷貝會完全複制整個對象,包括這個對象所包含的内部對象,堆中的對象也會拷貝⼀ 份
淺拷貝如何實作呢?
Object類提供的clone()⽅法可以⾮常簡單地實作對象的淺拷貝。
深拷貝如何實作呢?
- 重寫克隆⽅法:重寫克隆⽅法,引⽤類型變量單獨克隆,這⾥可能會涉及多層遞歸。
- 序列化:可以先講原對象序列化,再反序列化成拷貝對象
擴充:https://mp.weixin.qq.com/s/M4--Btn24NIggq8UBdWvAw
Java 建立對象有哪⼏種⽅式
| 建立對象方式 | 是否調用了構造器 |
|---|---|
| new關鍵字 | 是 |
| Class.newInstance | 是 |
| Constructor.newInstance | 是 |
| Clone | 否 |
| 反序列化 | 否 |
String相關
字元型常量和字元串常量的差別
- 形式上: 字元常量是單引号引起的一個字元 字元串常量是雙引号引起的若幹個字元
- 含義上: 字元常量相當于一個整形值(ASCII值),可以參加表達式運算 字元串常量代表一個位址值(該字元串在記憶體中存放位置)
- 占記憶體大小 字元常量隻占一個位元組 字元串常量占若幹個位元組(至少一個字元結束标志)
String 是最基本的資料類型嗎
不是。Java 中的基本資料類型隻有 8 個 :byte、short、int、long、float、double、char、boolean;除了基本類型(primitive type),剩下的都是引用類型(referencetype)
由于String 類使⽤ final 修飾,不可變,無法被繼承
什麼是字元串常量池?
字元串常量池位于堆記憶體中,專門用來存儲字元串常量,可以提高記憶體的使用率,避免開辟多塊空間存儲相同的字元串,在建立字元串時 JVM 會首先檢查字元串常量池,如果該字元串已經存在池中,則傳回它的引用,如果不存在,則執行個體化一個字元串放到池中,并傳回其引用。
String、StringBuffer、StringBuilder 的差別
String:String 的值被建立後不能修改,任何對 String 的修改都會引發新的 String 對象的⽣ 成,: 适用操作少量的資料
StringBuilder:StringBuffer 的⾮線程安全版本,性能上更⾼⼀些 ,适合單線程操作字元串緩沖區下操作大量資料
StringBuffer:跟 String 類似,但是值可以被修改,使⽤ synchronized 來保證線程安全。适合多線程操作字元串緩沖區下操作大量資料
String s = new String("abc")建立了幾個對象 ?
⼀個或兩個
如果字元串常量池已經有“abc”,則是⼀個;
否則,兩個。 當字元創常量池沒有 “abc”,此時會建立如下兩個對象: ⼀個是字元串字⾯量 "abc" 所對應的、字元串常量池中的執行個體 另⼀個是通過 new String() 建立并初始化的,内容與"abc"相同的執行個體,在堆中。
String str="abc"與 String str=new String("abc")一樣嗎?
不一樣,因為記憶體的配置設定方式不一樣。
String str="abc"
的方式,java 虛拟機會将其配置設定到常量池中;而
String str=new String("abc")
則會被分到堆記憶體中。
String有哪些特性
- 不變性:String 是隻讀字元串,是一個典型的 immutable 對象,對它進行任何操作,
其實都是建立一個新的對象,再把引用指向該對象
- 常量池優化:String 對象建立之後,會在字元串常量池中進行緩存,如果下次建立同樣的對象時,會直接傳回緩存的引用。
其中 不可變是由于:
- 儲存字元串的數組被 final 修飾且為私有的,并且String 類沒有提供/暴露修改這個字元串的方法。
- String 類被 final 修飾導緻其不能被繼承,進而避免了子類破壞 String 不可變。
String 類的常用方法都有那些?
- indexOf():傳回指定字元的索引。
- charAt():傳回指定索引處的字元。
- replace():字元串替換。
- trim():去除字元串兩端空白。
- split():分割字元串,傳回一個分割後的字元串數組。
- getBytes():傳回字元串的 byte 類型數組。
- length():傳回字元串長度。
- toLowerCase():将字元串轉成小寫字母。
- toUpperCase():将字元串轉成大寫字元。
- substring():截取字元串。
- equals():字元串比較。
在使用 HashMap 的時候,用 String 做 key 有什麼好處?
HashMap 内部實作是通過 key 的 hashcode 來确定 value 的存儲位置,因為字元串是不可變的,是以當建立字元串時,它的 hashcode 被緩存下來,不需要再次計算,是以相比于其他對象更快。
異常
Exception 和 Error 有什麼差別?
在 Java 中, Throwable 是 所有錯誤或異常的基類。Throwable 又分為 Error 和 Exception :
- Exception :程式本身可以處理的異常,可以通過 catch 來進行捕獲。Exception 又可以分為 Checked Exception (受檢查異常,必須處理) 和 Unchecked Exception (不受檢查異常,可以不處理)
- CheckedException受檢異常:編譯器會強制檢查并要求處理的異常。
- RuntimeException運⾏時異常:程式運⾏中出現異常,⽐如我們熟悉的空指針、數組下标 越界等等
- Error :Error 屬于程式無法處理的錯誤 ,不建議通過catch捕獲 。例如 Java 虛拟機運作錯誤(Virtual MachineError)、虛拟機記憶體不夠錯誤(OutOfMemoryError)、類定義錯誤(NoClassDefFoundError)
try-catch-finally 如何使用?
- try塊 : 用于捕獲異常。其後可接零個或多個 catch 塊,如果沒有 catch 塊,則必須跟一個 finally 塊。
- catch塊 : 用于處理 try 捕獲到的異常。
- finally 塊 : 無論是否捕獲或處理異常,finally 塊裡的語句都會被執行。當在 try 塊或 catch 塊中遇到 return 語句時,finally 語句塊将在方法傳回之前被執行。
我們來看看幾個常見的題目:
- 題目(1)
public class TestReflection2 {
public static void main(String[] args) {
System.out.println(test());
}
public static int test() {
try {
return 1;
} catch (Exception e) {
return 2;
} finally {
System.out.print("3");
}
}
}
結果:
31
,在 return 前會先執⾏ finally 語句塊,是以是先輸出 finally ⾥ 的 3,再輸出 return 的 1。
- 題目(2)
public static void main(String[] args) {
System.out.println(test());
}
public static int test() {
try {
return 1;
} catch (Exception e) {
return 2;
} finally {
return 3;
}
結果:
3
。 try在return傳回前先執⾏ finally,結果 finally 裡不按套路出牌,直接 return 了,⾃然也就⾛不到 try ⾥⾯的 return 了 ,注意實際開發中不能在finally中直接return
- 題目(3)
try {
System.out.println("Try to do something");
throw new RuntimeException("RuntimeException");
} catch (Exception e) {
System.out.println("Catch Exception" );
} finally {
System.out.println("Finally");
}
結果:
Try to do something
Catch Exception
Finally
沒有return的話,try -catch-finally 依次執行
- 題目(4)
public class TestReflection2 {
public static void main(String[] args) {
System.out.println(test1());
}
public static int test1() {
int i = 0;
try {
i = 2;
return i;
} finally {
i = 3;
}
}
}
結果:
2
, 在執⾏ finally 之前,JVM 會先将 i 的結果暫存起來,然後 finally 執⾏完畢後,會返 回之前暫存的結果,⽽不是傳回 i,是以即使 i 已經被修改為 3,最終傳回的還是之前暫存起 來的結果 2
- 題目(5)
try {
System.out.println("Try to do something");
throw new RuntimeException("RuntimeException");
} catch (Exception e) {
System.out.println("Catch Exception" );
// 終止目前正在運作的Java虛拟機
System.exit(1);
} finally {
System.out.println("Finally");
}
結果:
ry to do something
Catch Exception
我們可以發現,finally 中的代碼一般是一定會執行的,除了 2 種特殊情況下,finally 塊的代碼也不會被執行:
程式所在的線程死亡、關閉 CPU
。
IO
Java 中 IO 流分為幾種?
- 按照流的流向分,可以分為輸入流和輸出流;
- 按照操作單元劃分,可以劃分為位元組流和字元流;
- 按照流的角色劃分為節點流和處理流。
BIO,NIO,AIO 有什麼差別?
BIO:Block IO 同步阻塞式 IO,就是我們平常使用的傳統 IO,它的特點是模式簡單使用友善,并發處理能力低。
就是傳統的IO,同步阻塞,伺服器實作模式為⼀個連接配接⼀個線程,即客 戶端有連接配接請求時伺服器端就需要啟動⼀個線程進⾏處理,如果這個連接配接不做任何事情會造 成不必要的線程開銷,可以通過連接配接池機制改善(實作多個客戶連接配接伺服器)
BIO⽅式适⽤于連接配接數⽬⽐較⼩且固定的架構,這種⽅式對伺服器資源要求⽐較⾼,并發局限 于應⽤中,JDK1.4 以前的唯⼀選擇,程式簡單易了解
NIO:Non IO 同步非阻塞 IO,是傳統 IO 的更新,用戶端和伺服器端通過 Channel(通道)通訊,實作了多路複用。
NIO的資料是⾯向緩沖區Buffer的,必須從Buffer中讀取或寫⼊ ,支援阻塞和非阻塞兩種模式。阻塞模式使用就像傳統中的支援一樣,比較簡單,但是性能和可靠性都不好;非阻塞模式正好與之相反。對于低負載、低并發的應用程式,可以使用同步阻塞I/O來提升開發速率和更好的維護性;對于高負載、高并發的(網絡)應用,應使用 NIO 的非阻塞模式來開發
AIO:Asynchronous IO 是 NIO 的更新,也叫 NIO2,實作了異步非堵塞 IO ,異步 IO 的操作基于事件和回調機制。
當有事件觸發時,伺服器端得到通 知,進⾏相應的處理,完成後才通知服務端程式啟動線程去處理,⼀般适⽤于連接配接數較多且 連接配接時間較長的應⽤
既然有了位元組流,為什麼還要有字元流?
其實字元流是由 Java 虛拟機将位元組轉換得到的,問題就出在這個過程還⽐較耗時,并且,如 果我們不知道編碼類型就很容易出現亂碼問題。
是以, I/O 流就⼲脆提供了⼀個直接操作字元的接⼜,⽅便我們平時對字元進⾏流操作。如 果⾳頻⽂件、圖⽚等媒體⽂件⽤位元組流⽐較好,如果涉及到字元的話使⽤字元流⽐較好
擴充:重要知識點
什麼是反射?
JAVA反射機制是在運作狀态中,對于任意一個類,都能夠知道這個類的所有屬性和方法;對于任意一個對象,都能夠調用它的任意一個方法和屬性;這種動态擷取的資訊以及動态調用對象的方法的功能稱為java語言的反射機制。
常見的場景:①我們在使用JDBC連接配接資料庫時使用Class.forName()通過反射加載資料庫的驅動程式;②Spring架構也用到很多反射機制,最經典的就是xml的配置模式。Spring 通過 XML 配置模式裝載 Bean 的過程:1) 将程式内所有 XML 或 Properties 配置檔案加載入記憶體中; 2)Java類裡面解析xml或properties裡面的内容,得到對應實體類的位元組碼字元串以及相關的屬性資訊; 3)使用反射機制,根據這個字元串獲得某個類的Class執行個體; 4)動态配置執行個體的屬性
反射的原理? 我們都知道Java程式的執⾏分為編譯和運⾏兩步,編譯之後會⽣成位元組碼(.class)⽂件,JVM進 ⾏類加載的時候,會加載位元組碼⽂件,将類型相關的所有資訊加載進⽅法區,反射就是去獲 取這些資訊,然後進⾏各種操作。
拓展: https://mp.weixin.qq.com/s/_n8HTIjkw7Emcunpb4-Iwg
聊聊你認識的注解?
注解(Annotation ), 是 Java5 開始引入的新特性,是放在Java源碼的類、方法、字段、參數前的一種特殊“注釋”,是一種标記、标簽。
注釋往往會被編譯器直接忽略,能夠被編譯器打包進入class檔案,并執行相應的處理。
詳情:https://mp.weixin.qq.com/s/2tmeI_rFY7mn6xdDs9eMxg
動态代理的原理
動态代理無需聲明式的建立java代理類,而是在運作過程中動态生成"代理類",即編譯完成後**沒有實際的class檔案**,而是在**運作時動态生成 類位元組碼**,并加載到JVM中。
進而避免了靜态代理那樣需要聲明大量的代理類。
詳情:https://mp.weixin.qq.com/s/1nDO2gQxwjBGPYP-694fSA
本篇文章到這裡就結束啦,很感謝你能看到最後,附上小福利,小牛已經本篇文章打包成PDF,公衆号【小牛呼噜噜】回複:"我愛學習",即可免費擷取pdf最新版