我們在做性能測試的目的是什麼,就是要測出一個系統的瓶頸在哪裡,到底是哪裡影響了我們系統的性能,找到問題,然後解決它。當然一個系統由很多東西一起組合到一起,應用程式、資料庫、伺服器、中中間件等等很多東西。那我們測試的時候上面這些東西裡面任何一個環節都可能會出問題,都可能會影響我們系統的性能。這篇部落客要講下mysql資料庫咱們在做性能測試的時候應該監控什麼東西,又有哪些需要優化的地方。
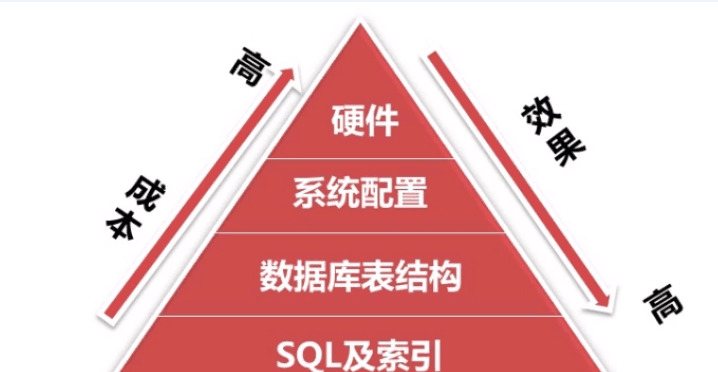
一、哪些東西會影響mysql的性能?
- 1.硬體
- 2.系統配置
- 3.資料庫表結構
- 4.SQL以及索引
硬體
硬體就指的是資料庫伺服器的配置,伺服器說白了就是一台電腦而已,如果電腦的配置高,cpu處理能力強,記憶體大,硬碟是ssd的,那肯定性能好。當然這種方式成本也是最高的,要花錢的嘛。
系統配置
系統配置一個指的是作業系統的配置,有一些作業系統的配置會影響mysql的性能,現在咱們大多數伺服器都是用的linux伺服器,linux上面一切東西都是基于檔案的,mysql資料裡面的表、資料等等都是檔案存在磁盤上的。
linux系統有一個系統配置是檔案打開的數量,預設是1024,也就是最多隻能打開1024個檔案,那在資料庫裡面表比較多、并發大的情況下,這1024就不夠用了,要想擷取資料就得打開檔案,但是打開檔案的數量最多就1024個,就會導緻有一些資料擷取不到,就得等待别的檔案關閉之後,才能打開。那就要修改系統的配置,在/etc/security/limits.conf檔案裡面可以修改最大打開檔案的數量。
| 1 2 3 | vi /etc/security/limits.conf * soft nofile 65536 * hard nofile 65536 |
還有一些mysql配置參數會影響mysql的性能。
sleep逾時時間
mysql的連接配接數是提前配置好的,如果程式裡面代碼寫的不好,有一些資料庫操作沒有及時關閉資料庫,那這個連結就不會釋放會一直占用連結,這樣子并發大的情況下,就會導緻資料庫連接配接數不夠用了,就連接配接不上資料庫了。mysql預設8小時不操作資料庫才會自動關閉連結,是以這個sleep的逾時時間會影響mysql的性能。
| set global wait_timeout=600; 設定sleep的逾時間,機關是秒 show variables like '%wait_timeout%'; 查詢逾時時間 |
獨立表空間設定
表空間是什麼呢,就是每個表存放資料的地方。
舉個例子,一個倉庫,你要往倉庫裡面放東西的話,你來一些東西你就随便扔到裡面,這樣東西一多,你要找到一個東西就很難找了。那怎麼辦呢,我在倉庫裡面放幾個貨架,每個貨架放同一個種類的東西,這樣的話,找一個東西就很友善了。
表空間呢就和這個貨架差不多,每個表我單獨管理的話,那找資料就比較友善了。
mysql5.6.6之前預設是共享的表空間,mysql5.6.6之後預設是開啟了獨立表空間的。
那什麼是共享表空間呢?
就是說這個空間是所有的表都共享的,所有的表的資料都存在一個地方的。
你想一下,所有的貨架都存在一個倉庫裡面的話,快遞員去拿貨的時候,人一多,可能進出都要排隊,拿貨的時候就比較慢了。
是以說共享表空間如果在資料量和并發量比較大的情況下,對IO的消耗是比較大的,影響性能。
共享表空間還有一個缺點就是不能自動收縮,自動收縮是什麼意思呢,剛建表的時候,表裡面資料很少,就1條資料,可能占用空間就幾kb,到後來資料多了,占用了10個G的空間,然後發現有一些資料都是垃圾資料,删了5個G,那這個時候表空間就不會自動減小了,它還是10個G,浪費空間。
而獨立表空間就是每個表的表空間都是獨享的,用倉庫這個例子就是每個貨架都單獨在一個房間裡頭,這樣的話快遞員去拿哪個東西,直接去那個房間裡就好了,不用都擠在一個倉庫裡了。
而使用了獨立的表空間,每個表都有自己的表空間,删了資料也會自動收縮,就不會有上面的問題了。
| set global innodb_file_per_table =ON; 設定獨立表空間打開 show variables like '%per_table%'; #查詢是否打開獨立表空間 |
讀/寫程序數配置
在mysql5.5之後讀、寫的程序數是可以配置的。預設讀和寫的程序數都是4個。
當然我們都知道,人多好幹活嘛。程序多就是幹活的人多,具體配置根據cpu的核數和業務邏輯來配置這兩個值。
假如cpu是32核的,那麼就是同時可以有32個程序在運作,就可以把這兩個值給調大。
假如說是系統是一個内容類的網站,大多數操作都是讀操作,那麼就可以把讀的程序數設定大一點,寫的程序數設定的小一點。
怎麼修改呢,找到mysql的配置檔案,在[mysqld]節點下加入下面參數的即可
| innodb_read_io_threads =5 讀程序數 innodb_write_io_threads =3 寫程序數 |
緩存配置
在說緩存配置之前咱們先了解清楚,計算機在處理任務的時候是怎麼處理的,先從磁盤上讀取資料,然後放到記憶體裡面,cpu去記憶體裡面拿資料,然後處理。
在寫的時候正好相反,cpu處理完之後,把資料放到記憶體裡面,記憶體再放到磁盤裡。
那從上面,我們發現,如果資料直接從記憶體裡面拿的話,那速度就快很多了,我們看下面的圖,讀1M的資料,記憶體裡面比從磁盤上快多少。
從上面這個圖我們發現從記憶體裡面讀資料比從磁盤裡面取資料快了N倍。
那到mysql裡面,如果取資料的時候,mysql先把一些資料緩存到記憶體裡面的話,取資料直接從記憶體裡面取不就快很多了。
咱們在說mysql緩存之前,先說下mysql在執行一條查詢語句的時候都做了什麼。
從上面的圖我們發現,mysql是有兩個地方檢查了記憶體的。如果記憶體裡面找到我們想要的資料,那麼就不去磁盤上查詢資料了。那麼這兩個緩存都是什麼,怎麼配置呢。
qcache配置
- 緩存完整的SELECT語句和查詢結果,當查詢命中緩存,MySQL會立刻傳回結果,跳過解析、優化和執行階段。
- 查詢緩存會跟蹤系統中的每張表,如果這些表發生變化,那麼和這張表相關的所有查詢緩存全部失效。
- 在檢查查詢緩存的時候,MySQL不會對SQL進行任何處理,它精确的使用用戶端傳來的查詢(select),隻要字元大小寫,或者注釋有一點點不同,查詢緩存就認為是不同的查詢。
- 任何一個包含不确定的函數(比如now(),current_date())的查詢不會被緩存。
- MySQL查詢緩存可以改善性能,但是在使用的時候也有一些問題需要注意:
開啟查詢緩存對于讀寫都增加了額外的開銷。對于讀,在查詢開始前需要先檢查緩存;對于寫,在寫入後需要更新緩存。
一般情況這些開銷相對較小,是以查詢緩存一般還是有好處的。但也要根據業務特征權衡是否需要開啟查詢緩存。
怎麼配置呢,找到mysql的配置檔案,在[mysqld]節點下加入下面參數的即可
| 4 5 6 7 8 | query_cache_size = 200M 配置設定給查詢緩存的總記憶體,一般建議不超過256M query_cache_limit = 1M 這個選項限制了MySQL存儲的最大結果。如果查詢的結果比這個大,那麼就不會被緩存。 下面是檢視qcache的狀态的語句 SHOW VARIABLES LIKE '%query_cache%';#檢視qcache狀态 |
innodb_buffer_pool配置
mysql裡面還有一個緩存配置就是innodb_buffer_pool的配置,innodb是現在mysql的預設存儲引擎,存儲引擎說白了就mysql存資料的時候到底是怎麼存的。
就是一個倉庫裡面怎麼擺放貨物的。
buffer pool是innodb存儲引擎帶的一個緩存池,查詢資料的時候,它首先會從記憶體中查詢,如果記憶體中存在的話,直接傳回,進而提高查詢響應時間。
innodb buffer pool和qcache的差別是:qcacche緩存的是sql語句對應的結果集,buffer pool中緩存的是表中的資料。buffer pool一般設定為伺服器實體記憶體的70%。
| innodb_buffer_pool_size=50M #Innodb_buffer_pool的大小 innodb_buffer_pool_dump_now=on #停止MySQL服務時,InnoDB将InnoDB緩沖池中的熱資料儲存到本地硬碟。 innodb_buffer_pool_load_at_startup =on #啟動MySQL服務時,MySQL将本地熱資料加載到InnoDB緩沖池中。 SHOW VARIABLES LIKE '%innodb_buffer_pool%';#檢視buffer_pool的大小 |
mysql架構上的優化
讀寫分離
多點寫入
資料庫表結構優化
當然系統在設計表結構的時候,一般都是架構師和一幫開發已經把表結構設計好了,咱們沒達到那個級别架構上的東西咱也不懂,就在設計表結構的時候需要注意的一些東西。
1、使用可以存下你的資料的最小資料類型
2、使用簡單的資料類型,int類型和varchar類型上,mysql處理int類型更簡單
3、盡可能的使用not null定義字段,可以為空的字段加上預設值
因為如果不限制not null的話,字段值是可以為空的,預設為空就是null,如果是not null的話字段值寫空的話,就要寫'',一個空的字元串。
null它在mysql裡面也是要占用空間的,也不能利用索引,而空的字元串在mysql是不占用空間的,也可以利用索引。
4、時間類型的,用UNIX_TIMESTAMP,因為是int類型的
mysql索引優化
索引是什麼呢,就和字典的目錄一樣。有目錄了,那咱們查資料就快了。
最适合建索引的列是出現在where子句後面的列。
唯一索引的效果最好,因為是唯一的。
利用最左字首。
索引并不是越多越好。
mysql索引有4種類型
1、普通索引
最普通的索引,所有列都可以加
| create index index_name on table_name (col); |
2、主鍵索引
建表的時候加的主鍵
3、組合索引
| create index index_name on table_name (col,col2); |
4、唯一索引
| CREATE UNIQUE INDEX index_name ON table_name (column_name); |
去除重複、備援索引
因為每個開發的水準都不一樣,不可避免的的會出現一些重複索引的問題。那我們怎麼來查找有一些備援的索引呢。
就要借助percona-toolkit這個工具了,它裡面有pt-duplicate-key-checker這個工具可以幫咱們找出來哪些表裡面有備援的索引,并給出修改索引的語句。
| pt-duplicate-key-checker -uroot -pxxx -dxx#-u指的是使用者 -p是密碼 -d是資料庫 |
這個能幫咱們找出來重複的索引,那還有一些根本就沒有必要用的索引,雖然索引建立的并不是重複,但是實際上并沒用查詢語句用到它,怎麼辦呢,percona-toolkit這個工具裡還有一個工具是pt-index-usage,它可以讀取慢查詢日志,幫咱們找到那些沒用的索引。
| pt-index-usage /opt/data/slow.log #後面是慢查詢日志 |
慢查詢日志
什麼是慢查詢日志呢,它這個就是個神器了,對咱們測試特别有幫助,它會記錄執行時間長的sql語句,這樣咱們找問題的時候就比較友善了。
| set global slow_query_log=on;#打開慢查詢日志 set global long_query_time=1;#設定記錄查詢超過多長時間的sql set global slow_query_log_file='/tmp/slow_query.log';#設定mysql慢查詢日志路徑,此路徑需要有寫權限 set global log_queries_not_using_indexes=ON; #設定沒有使用索引的sql記錄下來 SHOW VARIABLES LIKE '%slow%';#檢視慢查詢配置 |
mysql記錄的日志裡面,咱們看着比較不清晰,咱們使用pt-query-digest這個工具幫咱們解析慢查詢日志,它會把所有的sql的執行時間以及具體sql,執行了多少次都幫咱們統計出來。
下面是pt-query-digest的用法
| pt-query-digest --filter='$event->{fingerprint} =~ m/^select/i' slow.log #檢視包含select語句的慢查詢 pt-query-digest --since=12h slow.log #最近12小時的 pt-query-digest --since '2017-12-01 09:30:00' --until '2017-12-02 10:00:00' --filter='$event->{fingerprint} =~ m/^select/i' slow.log #指定時間段 |
如果想實時的擷取有沒有執行時間長的sql,用下面這個sql語句
| select id,`user`,`host`,DB,command,`time`,state,info from information_schema.PROCESSLIST where TIME>=60; |
explain
通過慢查詢日志我們可以找到有問題的sql語句,那我們怎麼看這個sql哪有問題呢,就要使用explain了,隻要在你要執行sql語句前面加上explain即可
all<index<range<ref<eq_ref<const,system sql執行type列裡最差到最優
sql優化時候需要注意的
查詢條件使用索引列,排序使用索引列
避免select *,一般select * 都會造成全表掃描
盡量避免子查詢,MySQL 的子查詢執行計劃一直存在較大的問題,雖然這個問題已經存在多年,但是到目前已經釋出的所有穩定版本中都普遍存在,一直沒有太大改善。雖然官方也在很早就承認這一問題,并且承諾盡快解決,但是至少到目前為止我們還沒有看到哪一個版本較好的解決了這一問題。
事物
銀行存錢例子。
鎖
表級鎖、行級鎖。
SELECT * FROM information_schema.INNODB_TRX\G
mysql性能測試工具
mysqlslap是mysql自帶的一個性能測試工具。它可以模拟各種并發,以及使用哪種sql,生成多少資料,運作多久,産生報告。
常用的選項
| 9 10 11 | --concurrency 并發數量,多個可以用逗号隔開 --engines 要測試的引擎,可以有多個,用分隔符隔開,如--engines=myisam,innodb --auto-generate-sql 用系統自己生成的SQL腳本來測試 --auto-generate-sql-load-type 要測試的是讀還是寫還是兩者混合的(read,write,update,mixed) --number-of-queries 總共要運作多少次查詢。每個客戶運作的查詢數量可以用查詢總數/并發數來計算 --debug-info 額外輸出CPU以及記憶體的相關資訊 --number-int-cols 建立測試表的int型字段數量 --number-char-cols 建立測試表的chat型字段數量 --create-schema 測試的database --query 自己的SQL 腳本執行測試 --only-print 如果隻想列印看看SQL語句是什麼,可以用這個選項 |
下面是使用的例子
| 100并發,運作1000次,寫操作和讀操作都有,自動生成sql,int類型字段2個,char類型10個, mysqlslap -h127.0.0.1 -uroot -p123456 --concurrency=100 --auto-generate-sql --auto-generate-sql-load-type=mixed --engine=innodb --auto-generate-sql-add-autoincrement --number-int-cols=2 --number-char-cols=10 --number-of-queries=10 100并發,運作5000次,besttest這個資料庫上執行sql mysqlslap -h127.0.0.1 -uroot -p123456 --concurrency=100 --query='select * from stu;' -create-schema=besttest --engine=innodb --number-of-queries=5000 --debug-info 100并發,運作5000次,besttest這個資料庫上執行指定的sql檔案 mysqlslap -h127.0.0.1 -uroot -p123456 --concurrency=100 --query=/tmp/besttest.sql -create-schema=besttest --engine=innodb --number-of-queries=5000 --debug-info |