一、基本資料類型——數字
1、布爾型
- bool型隻有兩個值:True和False
- 之是以将bool值歸類為數字,是因為我們也習慣用1表示True,0表示False。
(1)布爾值是False的各種情況:
bool(0)
bool(None)
bool("")
bool(())
bool([])
bool({})
(2)布爾值python2與python3的差別
在Python2.7 中,True和False是兩個内建(built-in)變量,内建變量和普通自定義的變量如a, b, c一樣可以被重新指派,是以我們可以把這兩個變量進行任意的指派。
在Python3.x 中,終于把這個兩變量變成了關鍵字,也就是說再也沒法給這兩變量賦新的值了,從此True永遠指向真對象,False指向假對象,永不分離。
2、整型
Python中的整數屬于int類型,預設用十進制表示,此外也支援二進制,八進制,十六進制表示方式。
進制轉換
二進制前面以‘0b’标示,八進制前面以‘0o’标示,十六進制以‘0x’标示
1 >>> bin(10) # 轉換為二進制
2 '0b1010'
3 >>> oct(10) # 轉換為八進制
4 '0o12'
5 >>> hex(10) # 轉換為十六進制
6 '0xa' 運算
>>> 5%2 # 取餘
1
>>> 16%4
0
>>> 2+3 # 加法
5
>>> 2-3 # 減法
-1
>>> 2*3 # 乘法
6
>>> 3/2 # 除法
1.5
>>> 9//2 # 取整除
4
>>> divmod(16,3) # 傳回包含商和餘數的元組(a // b, a % b)
(5, 1)
>>> 2**3 # 幂
8 3、浮點數
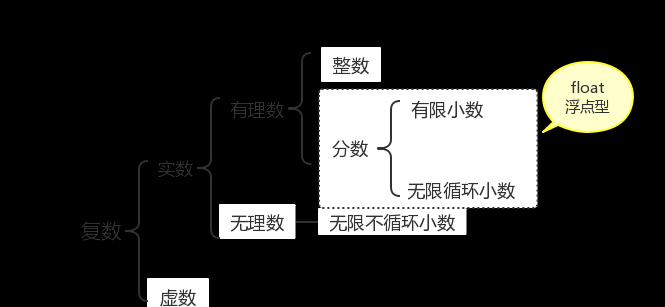
浮點數是屬于有理數中某特定子集的數的數字表示,在計算機中用以近似表示任意某個實數。具體的說,這個實數由一個整數或定點數(即尾數)乘以某個基數(計算機中通常是2)的整數次幂得到,這種表示方法類似于基數為10的科學計數法。
在python中,以雙精度(64)位來儲存浮點數,多餘的位會被截掉。
(1)關于小數不精準問題
Python預設的是17位精度,也就是小數點後16位,盡管有16位,但是這個精确度卻是越往後越不準的。
首先,這個問題不是隻存在在python中,其他語言也有同樣的問題
其次,小數不精準是因為在轉換成二進制的過程中會出現無限循環的情況,在約省的時候就會出現偏差。
比如:11.2的小數部分0.2轉換為2進制則是無限循環的00110011001100110011...
單精度在存儲的時候用23bit來存放這個尾數部分(前面9比特存儲指數和符号);同樣0.6也是無限循環的;
(2)計算需要使用更高的精度(超過16位小數)情況
#借助decimal子產品的“getcontext“和“Decimal“ 方法
>>> a = 3.141592653513651054608317828332
>>> a
3.141592653513651
>>> from decimal import *
>>> getcontext()
Context(prec=50, rounding=ROUND_HALF_EVEN, Emin=-999999, Emax=999999, capitals=1, clamp=0, flags=[FloatOperation], traps=[InvalidOperation, DivisionByZero, Overflow])
>>> getcontext().prec = 50
>>> a = Decimal(1)/Decimal(3)#注,在分數計算中結果正确,如果直接定義超長精度小數會不準确
>>> a
Decimal('0.33333333333333333333333333333333333333333333333333')
>>> a = '3.141592653513651054608317828332'
>>> Decimal(a)
Decimal('3.141592653513651054608317828332')
不推薦:字元串格式化方式,可以顯示,但是計算和直接定義都不準确,後面的數字沒有意義。
>>> a = ("%.30f" % (1.0/3))
>>> a
'0.333333333333333314829616256247'
4、複數
複數complex是由實數和虛數組成的要了解複數,其實關于複數還需要先了解虛數。
虛數(就是虛假不實的數):平方為複數的數叫做虛數。
複數是指能寫成如下形式的數a+bi,這裡a和b是實數,i是虛數機關(即-1開根)。在複數a+bi中,a稱為複數的實部,b稱為複數的虛部(虛數是指平方為負數的數),i稱為虛數機關。
當虛部等于零時,這個複數就是實數;當虛部不等于零時,這個複數稱為虛數。
注,虛數部分的字母j大小寫都可以。
二、基本資料類型——字元串
1、字元串定義
字元串是一個有序的字元的集合,用于存儲和表示基本的文本資訊,' '或'' ''或''' '''中間包含的内容稱之為字元串。
2、字元串特性
- 字元串是不可變類型。
- 按照從左到右的順序定義字元集合,下标從0開始順序通路,有序。
- 字元串的單引号和雙引号都無法取消特殊字元的含義,如果想讓引号内所有字元均取消特殊意義,在引号前面加r,如name=r'l\thf'
- unicode字元串與r連用必需在r前面,如name=ur'l\thf'
3、字元串操作
字元串格式化(format)
'''
1、使用位置參數
位置參數不受順序限制,且可以為{},參數索引從0開始,format裡填寫{}對應的參數值。
'''
>>> msg = "my name is {}, and age is {}"
>>> msg.format("hqs",22)
'my name is hqs, and age is 22'
>>> msg = "my name is {1}, and age is {0}"
>>> msg.format("hqs",23)
'my name is 23, and age is hqs'
# 傳入位置參數清單可用 *清單 的形式
>>> li = ['lary',18]
>>> 'my name is {} , age {}'.format(*li)
'my name is lary , age 18'
# 使用索引
>>> li = ['larry',12]
>>> 'my name is {0[0]}, age {0[1]}'.format(li)
'my name is larry, age 12'
'''
2、使用關鍵字參數
關鍵字參數值要對得上,可用字典當關鍵字參數傳入值,字典前加**即可
'''
>>> hash = {'name':'john' , 'age': 23}
>>> msg = 'my name is {name}, and age is {age}'
>>> msg.format(**hash)
'my name is john,and age is 23'
>>> msg.format(name="hqs",age=13)
'my name is hqs,and age is 13'
>>> msg.format(age = 33, name = "zr")
'my name is zr, and age is 33'
'''
3、填充與格式化
:[填充字元][對齊方式 <^>][寬度]
'''
>>> '{0:*<10}'.format(10) # 左對齊
'10********'
>>> '{0:*<10}'.format("hqs") # 左對齊
'hqs*******'
>>> '{0:*^10}'.format("hqs") # 居中對齊
'***hqs****'
>>> '{0:*>10}'.format(10) # 右對齊
'********10'
'''
4、精度與進制
'''
>>> '{0:.2f}'.format(1/3) # 浮點數
'0.33'
>>> '{0:b}'.format(18) # 二進制
'10010'
>>> '{0:o}'.format(18) # 八進制
'22'
>>> '{0:x}'.format(18) # 十六進制
'12'
>>> '{:,}'.format(13111313341313) # 千分位格式化
'13,111,313,341,313' 常用操作
#索引
s = 'hello'
>>> s[1]
'e'
>>> s[-1]
'o'
>>> s.index('e')
1
#查找
>>> s.find('e')
1
>>> s.find('i')
-1
#移除空白
s = ' hello,world! '
s.strip()
s.lstrip()
s.rstrip()
s2 = '***hello,world!***'
s2.strip('*')
#長度
>>> s = 'hello,world'
>>> len(s)
11
#替換
>>> s = 'hello world'
>>> s.replace('h','H')
'Hello world'
>>> s2 = 'hi,how are you?'
>>> s2.replace('h','H')
'Hi,How are you?'
#切片
>>> s = 'abcdefghigklmn'
>>> s[0:7]
'abcdefg'
>>> s[7:14]
'higklmn'
>>> s[:7]
'abcdefg'
>>> s[7:]
'higklmn'
>>> s[:]
'abcdefghigklmn'
>>> s[0:7:2]
'aceg'
>>> s[7:14:3]
'hkn'
>>> s[::2]
'acegikm'
>>> s[::-1]
'nmlkgihgfedcba' 首尾操作及統計字元
1 >>> name = "HuangQiuShi"
2 >>> name.capitalize() # 首字母大寫
3 'Huangqiushi'
4 >>> name.endswith("Li") # 判斷字元串是否以 Li結尾
5 False
6 >>> name.endswith("hi") # 判斷字元串是否以 hi結尾
7 True
8
9 >>> name.center(50,'-') # 字元串居中顯示
10 '-------------------HuangQiuShi--------------------'
11 >>> name.rjust(50,'-')
12 '---------------------------------------HuangQiuShi'
13 >>> name.ljust(50,'-')
14 'HuangQiuShi---------------------------------------'
15
16 >>> name.count("shi") # 統計'shi'出現次數
17 0
18 >>> name.count("i")
19 2 zfill(width)方法: 傳回指定長度的字元串,原字元串右對齊,前面填充0
width --指定字元串的長度。原字元串右對齊,前面填充0
>>> str = "example showing how to use zfill"
>>> print(str.zfill(20))
example showing how to use zfill
>>> print(str.zfill(40))
00000000example showing how to use zfill
>>> print(str.zfill(50))
000000000000000000example showing how to use zfill 三、基本資料類型——清單
定義清單:[]内以逗号分隔,按照索引,存放各種資料類型,每個位置代表一個元素。
1、清單特性
1.可存放多個值
2.按照從左到右的順序定義清單元素,下标從0開始順序通路,有序
3.可修改指定索引位置對應的值,可變
2、清單操作
建立清單
# 清單建立(把逗号分隔的不同的資料項使用方括号括起來即可)
list_test = ['阿福','收稅','snake'] 切片:取多個元素
>>> names = ["Alex","Tenglan","Eric","Rain","Tom","Amy"]
>>> names[1:4] #取下标1至下标4之間的數字,包括1,不包括4
['Tenglan', 'Eric', 'Rain']
>>> names[1:-1] #取下标1至-1的值,不包括-1
['Tenglan', 'Eric', 'Rain', 'Tom']
>>> names[0:3]
['Alex', 'Tenglan', 'Eric']
>>> names[:3] #如果是從頭開始取,0可以忽略,跟上句效果一樣
['Alex', 'Tenglan', 'Eric']
>>> names[3:] #如果想取最後一個,必須不能寫-1,隻能這麼寫
['Rain', 'Tom', 'Amy']
>>> names[3:-1] #這樣-1就不會被包含了
['Rain', 'Tom']
>>> names[0::2] #後面的2是代表,每隔一個元素,就取一個
['Alex', 'Eric', 'Tom']
>>> names[::2] #和上句效果一樣
['Alex', 'Eric', 'Tom'] 追加、插入
>>> list_test.append(2017)
>>> list_test
['阿福', '收稅', 'snake', 2017]
>>> list_test.insert(2,"強行從snake前面插入")
>>> list_test
['阿福', '收稅', '強行從snake前面插入', 'snake', 2017]
>>> list_test.insert(0,"強行插入最前")
>>> list_test
['強行插入最前', '阿福', '收稅', '強行從snake前面插入', 'snake', 2017] 修改
>>> list_test = ['強行插入最前', '阿福', '收稅', '強行從snake前面插入', 'snake', 2017]
>>> list_test[2] = "換了一個人"
>>> list_test
['強行插入最前', '阿福', '換了一個人', '強行從snake前面插入', 'snake', 2017] 删除
# 删除指定位置元素
>>> del list_test[2]
>>> list_test
['強行插入最前', '阿福', '強行從snake前面插入', 'snake', 2017]
# 删除指定元素
>>> list_test.remove("snake")
>>> list_test
['強行插入最前', '阿福', '強行從snake前面插入', 2017]
# 删除清單最後一個值
>>> list_test.pop()
2017
>>> list_test
['強行插入最前', '阿福', '強行從snake前面插入'] 擴充
>>> b = [1,3,"asdad"]
>>> list_test.extend(b)
>>> list_test
['強行插入最前', '阿福', '強行從snake前面插入', 1, 3, 'asdad'] 拷貝
>>> list_test_copy = list_test.copy()
>>> list_test_copy
['強行插入最前', '阿福', '強行從snake前面插入', 1, 3, 'asdad'] 統計
>>> list_test.append("阿福")
>>> list_test.count("阿福")
2
>>> list_test
['強行插入最前', '阿福', '強行從snake前面插入', 1, 3, 'asdad', '阿福'] 排序&翻轉
>>> list_test.sort() # 不同資料類型不能一起排序
Traceback (most recent call last):
File "<input>", line 1, in <module>
TypeError: '<' not supported between instances of 'int' and 'str'
>>> list_test[-3] = '3' # 修改為字元串
>>> list_test[-4] = '1'
>>> list_test
['強行從snake前面插入', '強行插入最前', '阿福', '1', '3', 'asdad', '阿福']
>>> list_test.sort()
>>> list_test
['1', '3', 'asdad', '強行從snake前面插入', '強行插入最前', '阿福', '阿福']
>>> list_test.reverse() # 翻轉
>>> list_test
['阿福', '阿福', '強行插入最前', '強行從snake前面插入', 'asdad', '3', '1'] 擷取下标
>>> list_test
['阿福', '阿福', '強行插入最前', '強行從snake前面插入', 'asdad', '3', '1']
>>> list_test.index("阿福")
0
>>> list_test.index("asdad")
4