問題及答案來源自《Java程式員面試筆試寶典》第五章 Java Web 5.3 架構
11、什麼是IoC?
IoC:控制反轉(Inverse of Control, IoC),有時候也被稱為依賴注入,是一種降低對象之間耦合關系的一種設計思想
一般而言,在分層體系結構中,都是上層調用下層的接口,上層依賴于下層的執行,即調用者依賴于被調用者。
而通過Ioc方式,使得上層不再依賴于下層的接口,即通過一定的機制來選擇不同的下層實作,完成控制反轉,使得
由調用着決定被調用者。IoC通過注入一個執行個體化的對象來達到解耦合的目的
使用這種方法後,對象不會被顯式的調用,而是根據需求通過IoC容器(例如Spring)來提供。 采用IoC機制能夠提高系統
的可擴充性,如果對象之間通過顯式調用進行互動會導緻調用者與被調用者存在着非常緊密的聯系,其中一方的改動會
導緻程式出現很多的改動
實際案例如下:
要為一家茶店提供一套管理系統,在這家商店剛開業時隻賣綠茶,随着規模的擴大或者根據具體銷售量,未來可能會随時
改變茶的類型,例如紅茶等,傳統的實作方式會針對茶抽象化一個基類,綠茶類隻需要繼承自該基類即可,如下圖所示:
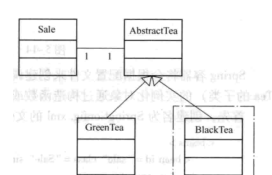
采用該實作方法後,在需要使用GreenTea時,隻需要執行以下代碼即可:AbstractTea t = new GreenTea(),當然,
這種方法是可以滿足目前設計要求的,但是該方法的可擴充性不好,存在着不恰當的地方,例如商家發現綠茶的銷售
并不好,決定開始銷售紅茶,那麼需要實作一個BlackTea類,并且讓這個類繼承自AbstractTea即可。但是,系統中用到
的AbstractTea t = new GreenTea()都需要改為AbstractTea t = new BlackTea(),而這種建立對象執行個體額方法往往會導緻
程式的改動量非常大。
那怎麼樣才能增強系統的可擴充性呢?– 可以采用設計模式中的工廠模式
此時可以使用設計模式中的工廠模式來把建立對象的行為包裝起來:

通過以上的方法,可以把建立對象的過程委托給TeaFactory來完成,在需要使用Tea對象時,隻需要調用Factory類的
getTea方法即可,具體建立對象的邏輯在TeaFactory中來實作,那麼當商家需要把綠茶替換為紅茶時,系統隻需要改動
TeaFactory中建立對象的邏輯即可,采用了工廠模式後,隻需要在一個地方做改動就可以滿足要求,這樣就增強了系統
的可擴充性。雖然采用工廠設計模式後,增強了系統的可擴充性,但是本質上來講,工程模式隻不過把程式中會變動的
邏輯移動到工廠類裡面了,當系統中類較多時,在系統擴充時需要經常改動工廠類中的代碼。而采用IoC設計思想後,程式
會有更好的擴充性
Spring架構IoC的實作方法:
spring架構在采用Ioc後的實作方法是将上面的TeaFactory通過Ioc容器通過配置檔案來加載被調用對象,同時把被調用的對象
的執行個體化對象通過構造函數或者set方法的形式注入到調用者對象中
12、什麼是AOP?
AOP:
面向切面程式設計(Aspect-oriented Programming,AOP)是對面向對象開發的一種補充,它允許開發人員在不改變原來模型的
基礎上動态的修改模型以滿足新的需求,例如,開發人員可以在不改變原來業務邏輯模型的基礎上可以動态的增加日志、
安全或異常處理的功能。
13、什麼是Spring架構?
Spring架構:
Spring是一個J2EE架構,這個架構提供了對輕量級IoC的良好支援,同時也提供了對AOP技術非常好的封裝。
相比其他架構,Spring架構的設計更加子產品化,架構内的每個子產品都能完成特定的工作,而且各個子產品可以獨立的
運作,不會互相牽制,是以,在使用Spring架構開發時,開發人員可以使用整個架構,也可以隻使用架構内的一部分
子產品,例如隻使用Spring AOP子產品來實作日志管理功能,而不需要使用其他子產品。
Spring架構主要由7個子產品組成,分别是Spring AOP、Spring ORM、Spring DAO、Spring Web、Spring Context、
Spring Web MVC、Spring Core等。
Spring架構圖:
下面是各子產品的作用:
Spring AOP:采用了面向切面程式設計的思想,使Spring架構管理的對象支援AOP,同時這個子產品也提供了事務管理,
可以不依賴具體的EJB元件,就可以将事務管理內建到應用程式中
Spring ORM:提供了對現有ORM架構的支援,例如Hibernate、JDO等
Spring DAO:提供了對資料通路對象(Data Access Object,DAO)模式和JDBC的支援。DAO可以實作把業務邏輯與
資料庫通路的代碼實作分離,進而降低代碼的耦合度。通過對JDBC的抽象,簡化了開發工作,同時簡化了對異常的
處理(可以很好的處理不同資料庫廠商抛出的異常)
Spring Web:提供了Servlet監聽器的Client和Web應用的上下文。同時還內建了一些現有的Web架構,例如Structs
Spring Context:擴充核心容器,提供了Spring上下文環境,給開發人員提供了很多有用的服務
Spring MVC:提供了一個構件Web應用程式的MVC的實作
Spring Core:Spring架構的核心容器,它提供了Spring架構的基本功能,這個子產品中最主要的一個元件為BeanFactory,
它使用工廠模式來建立所需的對象。同時BeanFactory使用IOC思想,通過讀取XML檔案的方式來執行個體化對象,可以說
BeanFactory提供了元件生命周期的管理,組建的建立、裝配、銷毀等功能
14、什麼是Hibernate?
Hibernate:
Hibernate是一個開放源代碼的對象關系映射(ORM)架構,它不僅可以允許在J2EE容器中,也可以運作在J2EE容器外
它對JDBC進行了輕量級封裝,任何可以使用JDBC的地方都可以用Hibernate代替
Hibernate實作了Java對象與關系資料庫記錄的映射關系,簡化了開發人員通路資料庫的流程,提高軟體開發效率
Hibernate的五個核心接口:
(1)Configuration接口:
作用:配置hibernate,啟動hibernate
hibernate應用通過Configuration執行關系-映射檔案的位置或者動态配置hibernate屬性,最後建立SessionFactory執行個體對象
在hibernate的hiberante.cfg.xml檔案配置中,會有這麼一句話:
<mapping resource="com/lanhuigu/hibernate/entity/Customer.hbm.xml" />
這句就是指定關系-映射檔案的位置。
(2)SessionFactory接口:
作用:初始化hibernate,一個SessionFactory對應一個執行個體資料源,建立session接口對象
SessionFactory特點:
- 線程安全,一個執行個體多個線程共享。
- 不能随意建立和銷毀,因為是重量級的。一個資料庫隻需建立一個SessionFactory執行個體,初始化時建立。如果同時通路多個資料庫,需要對應每個資料庫建立對應的執行個體。否則線程共享資料時,發生資料混亂。
(3)Session接口:
作用:負責資料的儲存,更新,删除,加載和查詢對象
Session接口的特點:
- 線程不安全,避免多個線程共享一個session。
- 是輕量級的,建立和銷毀消費資源少,被稱為持久化管理器
主要有5個方法對象以上操作:
- save():
- update():
- delete():
- load():
- find():
(4)Transaction接口:
作用:底層封裝JDBC,JTA,CORBA事務, 負責hibernate事務的管理。
(5)Query接口和Criteria接口:
作用:負責資料的查詢
Query封裝HQL(Hibernate Query Language)查詢語句,Criteria封裝基于字元串形式的查詢語句
上述五大接口之間關系如下:
Hibernate的使用過程:
- 應用程式通過Configuration類讀取配置檔案并建立SessionFactory對象
- 通過SessionFactory對象生成一個Sesssion對象
- 通過Session對象的beginTrancation方法建立一個事務
- 通過Session對象的get()、load()、save()、update()、delete()、saveOrUpdate()方法實作資料的增删改
- 通過Session生成一個Query對象,利用Query對象執行查詢操作
- 最後通過commit方法或者rollback方法完成事務操作
- 在完成所有持久化操作與事務操作後需關閉Session與SessionFactory
在使用Hibernate時如何提高性能?
延遲加載:當Hibernate從資料庫中擷取某個對象的值時通過建立代理對象把對象的屬性設定為預設值,當使用這些
資料時才會從資料庫中加載
緩存技術:Hibernate中提供了一級緩存和二級緩存。合理的利用緩存可以提高系統性能
優化查詢語句:通過優化查詢語句來提高系統性能
15、什麼是Hibernate的二級緩存?
什麼是緩存:
緩存的目的是為了通過減少應用程式對實體資料源通路的次數來提高程式運作的效率,原理是把目前或接下來一段時間
内可能會被用到的資料儲存到記憶體中,在使用時直接從記憶體中讀取,而不是從硬碟中讀取
Hibernate中的緩存:
在Hibernate中,緩存用來把從資料庫中查詢出來的和使用過的對象儲存到記憶體中,以便後期需要用到這個對象時可以直接
從緩存中擷取這個對象,隻有對象在緩存中不存在時才會去資料庫中查詢,緩存避免了大量發送SQL語句造成的性能損耗
另外Hibernate中的緩存分為一級緩存和二級緩存,一級緩存由Session管理,二級緩存由SessionFactory管理,一級緩存
必不可少,二級緩存可有可無
Hibernate中的一級緩存:
當用Session查詢資料時,首先在該Session内部查找該對象是否存在,若存在直接傳回,否則就到資料庫中查詢,并将
查詢的結果緩存起來以便後期使用。一級緩存的缺點是當使用Session來表示一次會話時,它的生命周期較短,而且它是
線程不安全的,不能被多個線程共享,是以在實際使用中其對效率的提升不是很明顯
Hibernate中的二級緩存:
二級緩存用來為Hibernate配置一種全局的緩存,以便實作多個線程與事務共享,在使用了二級緩存之後,當查詢資料時會
首先在内部緩存中查找,如果不存在,接着在二級緩存中查找,最後才到資料庫查找
另外二級緩存是獨立于Hibernate的軟體部件,屬于第三方産品,常見的産品有EhCache、OSCache和JbossCache等
Hibernate3之後預設使用的産品是EhCache
16、Hibernate中session的update()和saveOrUpdate()、load()和get()有什麼差別?
Hibernate的對象有3種狀态,分别為:瞬時态(Transient)、持久态(Persistent)和脫管态(Detached)
saveOrUpdate方法(同時包含save方法和update方法的功能):
- 如果對象已經在本session中持久化了,不做任何操作,直接傳回
- 如果傳入的對象與session中另一個對象有相同的辨別符,抛出一個異常
- 如果對象沒有持久化辨別(identifier)屬性,對其調用save()
- 如果對象的持久辨別(identifier)表明其是一個新執行個體化的對象,對其調用save()
- 如果對象是附帶版本資訊的(通過<version>或<timestamp>) 并且版本屬性的值表明其是一個新執行個體化的對象,對其調用save()
- 否則update() 這個對象
get方法和load方法的差別:
- 如果資料庫中不存在該對象,load方法抛出ObjectNotFoundException異常,而get方法傳回null
- get方法首先查詢Session内部緩存,若不存在接着查詢二級緩存,最後查詢資料庫
- load方法首先查詢Session内部緩存,若不存在建立代理對象,實際使用資料時再去查詢二級緩存和資料庫
- get方法永遠傳回實體類,load方法可以傳回實體類的代理類執行個體
19、什麼是SSH?
SSH:Structs + Spring + Hibernate
- 表示層(視圖層):JSP
- 業務邏輯層:Spring
- 資料持久化層:Hibernate
補充:什麼是SSM?
SSM:Spring+SpringMVC+MyBatis
架構原理:
頁面發送請求給控制器,控制器調用業務層處理邏輯,邏輯層向持久層發送請求,持久層與資料庫互動,後将結果傳回給業務層,
業務層将處理邏輯發送給控制器,控制器再調用視圖展現資料
too young too simple sometimes native!