其實昨天晚上就想寫部落格的,但是有個東西一直沒搞明白,弄到了十點才從實驗室走,希望今天能把他搞明白。現在是2020/9/28 10:12,剛剛裝好Redmi的顯示器,真香。等等還要去上課的我(除了早上一二節沒課,剩下的滿課,嗚嗚嗚),先随便寫寫了。(還有昨天LGD打得真菜,雖然我是一個打LOL不超過十局的人,但是我看了挺多比賽哈哈。
學了啥
首先就是eat pytorch in 20 days的進度了
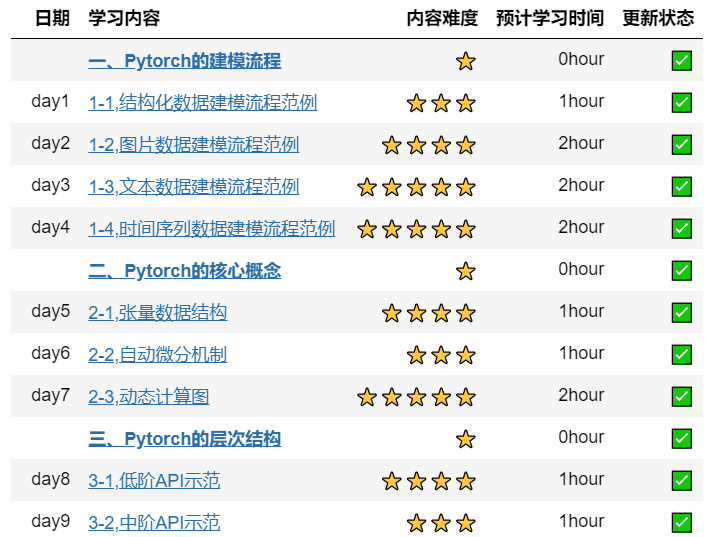
上一篇部落格是day4,也就是1-4,截至昨天學到了day9,也就是3-2,但是中間還是有一些東西我還不是很了解的,等等會做個梳理。今天努力把day10的學完。不行了,先去上課了。
現在是16:54下課剛剛回來,到實驗室,把這個寫完再開始學習
問題1:backward()的反向傳播機制
先上代碼:
下面是标量反向傳播
import numpy as np
import torch
# f(x) = a*x**2 + b*x + c的導數
x = torch.tensor(0.0,requires_grad = True) # x需要被求導
a = torch.tensor(1.0)
b = torch.tensor(-2.0)
c = torch.tensor(1.0)
y = a*torch.pow(x,2) + b*x + c
y.backward()
# 這裡沒有傳參數
dy_dx = x.grad
print(dy_dx)
接着的是非标量的反向傳播
import numpy as np
import torch
# f(x) = a*x**2 + b*x + c
x = torch.tensor([[0.0,0.0],[1.0,2.0]],requires_grad = True) # x需要被求導
a = torch.tensor(1.0)
b = torch.tensor(-2.0)
c = torch.tensor(1.0)
y = a*torch.pow(x,2) + b*x + c
gradient = torch.tensor([[1.0,1.0],[1.0,1.0]])
print("x:\n",x)
print("y:\n",y)
y.backward(gradient = gradient)
# 為什麼這裡需要傳gradient參數
x_grad = x.grad
print("x_grad:\n",x_grad)
兩個代碼的對比,我不明白非标量為什麼需要y.backward()中需要傳gradient這個參數,并且不清楚這個參數的作用。最後在某篇博文找到了答案
鍊式求導法則,本質上是求解y的各分量對自變量的導數,然後乘上y對自己分量的梯度。其實這裡的1.0可以了解成y對y求導,其結果是1.0。如果把這個tensor改成0.2或者2.3等等的數字,那相當于是這樣子的效果。
-
**A = 0.2y[0] + 2.3y[1]**
順便留兩張向量,矩陣求導的公式

問題2:torch.autograd.Function的了解
說是Function的了解,其實是Function的新舊版本執行個體化方式。
a = F.apply(args)
f = F()
a = f(args)
的差別
第一塊代碼是新版本的執行個體化方式,第二塊代碼是舊版的。我犯的錯誤是用舊版本的去執行個體化新版本的class,就發生了報錯。因為新舊版本的class寫法是不一樣的。具體看這個連結。
問題3:是關于python的,先上代碼
print(X)
print(torch.squeeze(model.forward(X)>=0.5))
print(torch.squeeze(model.forward(X)<0.5))
temp1 = X[torch.squeeze(model.forward(X)>=0.5)]
temp2 = X[torch.squeeze(model.forward(X)<0.5)]
print(temp1)
print(temp2)
print(X.shape)
print(temp1.shape)
print(temp2.shape)
下面是代碼的結果
一直弄不明白X的下标取True or False的時候,會得到什麼,最後隻要列印出來,看結果是mask,但是我也不是很确定,但目前還沒找到答案。
結束啦
今天就到這裡吧,雖然說買了顯示器,但是我的電腦是超極本,轉接口還沒到,還是智能看着這個13寸的小螢幕寫部落格,嗚嗚嗚。其實它中午的時候到菜鳥驿站了,但是因為上課沒法去拿,等等去拿一下,然後給大家上個照片hhh