程序和線程
一、程序
程序是程式的配置設定資源的最小單元;一個程式可以有多個程序,但隻有一個主程序;程序由程式、資料集、控制器三部分組成。
二、線程
線程是程式最小的執行單元;一個程序可以有多個線程,但是隻有一個主線程;線程切換分為兩種:一種是I/O切換,一種是時間切換(I/O切換:一旦運作I/O任務時便進行線程切換,CPU開始執行其他線程;時間切換:一旦到了一定時間,線程也進行切換,CPU開始執行其他線程)。
三、總結
一個程式至少有一個程序和一個線程;
程式的工作方式:
1.單程序單線程;2.單程序多線程;3.多程序多線程;
考慮到實作的複雜性,一般最多隻會采用單程序多線程的工作方式;
四、為什麼要使用多線程
我們在實際生活中,希望既能一邊浏覽網頁,一邊聽歌,一邊打遊戲。這時,如果隻開一個程序,為了滿足需求,CPU隻能快速切換程序,但是在切換程序時會造成大量資源浪費。是以,如果是多核CPU,可以在同時運作多個程序而不用進行程序之間的切換。
然而,在實際中,比如:你在玩遊戲的時候,電腦需要一邊顯示遊戲的動态,一邊你還得和同伴進行語音或語言進行溝通。這時,如果是單線程的工作方式,将會造成在操作遊戲的時候就無法給同伴溝通,在和同伴溝通的時候就無法操作遊戲。為了解決該問題,我們可以開啟多線程來共享遊戲資源,同時進行遊戲操作和溝通。
五、執行個體
場景一:并發依次執行
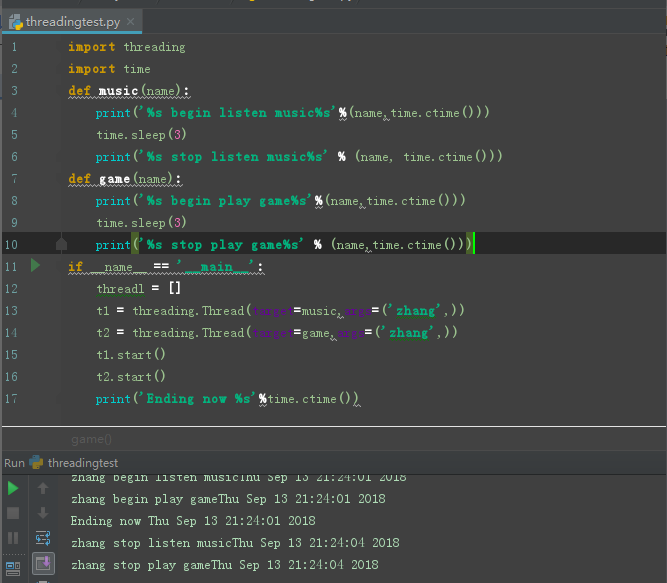
如上圖所示:有兩個簡單的函數,一個是聽音樂一個是打遊戲的函數。
如果按照之前的單線程方式,将會是先運作完聽音樂的函數再去運作打遊戲的函數,最後列印Ending。如下圖所示:

一共的運作時間是6秒。并且是隻能單一按照順序依次去執行。而使用多線時,運作時間是3秒,并且是并行執行。
該情況下的多線程運作方式是,先建立線程1,再建立線程2,然後去啟動線程1和線程2,并和主線程同時運作。此種情況下,若子線程先于主線程運作完畢,則子線程先關閉後主線程運作完畢關閉;若主線程先于子線程結束,則主線程要等待所有的子線程運作完畢後再關閉。
該部分代碼塊:
import threading
import time
def music(name):
print('%s begin listen music%s'%(name,time.ctime()))
time.sleep(3)
print('%s stop listen music%s' % (name, time.ctime()))
def game(name):
print('%s begin play game%s'%(name,time.ctime()))
time.sleep(3)
print('%s stop play game%s' % (name,time.ctime()))
if __name__ == '__main__':
# threadl = []
# t1 = threading.Thread(target=music,args=('zhang',))
# t2 = threading.Thread(target=game,args=('zhang',))
# t1.start()
# t2.start()
music('zhang')
game('zhang')
print('Ending now %s'%time.ctime()) 場景二:主線程等待某子線程結束後才能執行(join()函數的用法)
例如:在實際中,需要子線程在插入資料,主線程需要等待資料插入結束後才能進行查詢驗證操作(測試驗證資料)
該部分代碼塊為:
import threading
import time
def music(name):
print('%s begin listen music%s'%(name,time.ctime()))
time.sleep(5)
print('%s stop listen music%s' % (name, time.ctime()))
def game(name):
print('%s begin play game%s'%(name,time.ctime()))
time.sleep(3)
print('%s stop play game%s' % (name,time.ctime()))
if __name__ == '__main__':
threadl = [] #線程清單,用例存放線程
#産生線程的執行個體
t1 = threading.Thread(target=music,args=('zhang',)) #target是要執行的函數名(不是函數),args是函數對應的參數,以元組的形式;
t2 = threading.Thread(target=game,args=('zhang',))
threadl.append(t1)
threadl.append(t2)
#循環清單,依次執行各個子線程
for x in threadl:
x.start()
#将最後一個子線程阻塞主線程,隻有當該子線程完成後主線程才能往下執行
x.join()
print('Ending now %s'%time.ctime()) import threading
import time
def music(name):
print('%s begin listen music%s'%(name,time.ctime()))
time.sleep(2)
print('%s stop listen music%s' % (name, time.ctime()))
def game(name):
print('%s begin play game%s'%(name,time.ctime()))
time.sleep(5)
print('%s stop play game%s' % (name,time.ctime()))
if __name__ == '__main__':
threadl = [] #線程清單,用例存放線程
#産生線程的執行個體
t1 = threading.Thread(target=music,args=('zhang',)) #target是要執行的函數名(不是函數),args是函數對應的參數,以元組的形式;
t2 = threading.Thread(target=game,args=('zhang',))
threadl.append(t1)
threadl.append(t2)
#循環清單,依次執行各個子線程
for x in threadl:
x.start()
#将子線程t1阻塞主線程,隻有當該子線程完成後主線程才能往下執行
t1.join()
print('Ending now %s'%time.ctime()) 六、線程守護(setDaemon()函數)
前面不管是不是用到了join()函數,主線程最後總是要得所有的子線程執行完成後且自己執行完才能關閉(以子線程為主來結束主線程)。下面,我們講述一種以主線程為主的方法來結束主線程。
圖1:無線程守護
圖2:t2線程守護
import threading
import time
def music(name):
print('%s begin listen music%s'%(name,time.ctime()))
time.sleep(2)
print('%s stop listen music%s' % (name, time.ctime()))
def game(name):
print('%s begin play game%s'%(name,time.ctime()))
time.sleep(5)
print('%s stop play game%s' % (name,time.ctime()))
if __name__ == '__main__':
threadl = [] #線程清單,用例存放線程
#産生線程的執行個體
t1 = threading.Thread(target=music,args=('zhang',)) #target是要執行的函數名(不是函數),args是函數對應的參數,以元組的形式;
t2 = threading.Thread(target=game,args=('zhang',))
threadl.append(t1)
threadl.append(t2)
#循環清單,依次執行各個子線程
t2.setDaemon(True) #t2線程守護
for x in threadl:
x.start()
#将子線程t1阻塞主線程,隻有當該子線程完成後主線程才能往下執行
print('Ending now %s'%time.ctime()) 所謂’線程守護’,就是主線程不管該線程的執行情況,隻要是其他子線程結束且主線程執行完畢,主線程都會關閉。也就是說:主線程不等待該守護線程的執行完再去關閉。
注意:setDaemon方法必須在start之前且要帶一個必填的布爾型參數
七、自定義的方式來産生多線程
import threading
import time
class mythread1(threading.Thread):
'自定義線程'
def __init__(self,name):
threading.Thread.__init__(self)
self.name=name
def run(self):
'定義每個線程要運作的函數,此處為music函數'
print('%s begin listen music, %s' % (self.name, time.ctime()))
time.sleep(5)
print('%s stop listen music, %s' % (self.name, time.ctime()))
class mythread2(threading.Thread):
'自定義線程'
def __init__(self,name):
threading.Thread.__init__(self)
self.name=name
def run(self):
'定義每個線程要運作的函數,此處為game函數'
print('%s begin play game, %s' % (self.name, time.ctime()))
time.sleep(2)
print('%s stop play game, %s' % (self.name, time.ctime()))
if __name__ == '__main__':
threadl = []
t1 = mythread1('zhang')
t2 = mythread2('zhang')
threadl.append(t1)
threadl.append(t2)
for x in threadl:
x.start()
print('Ending now %s' % time.ctime()) 八、Threading的其他常用方法
getName() :擷取線程名稱
setName():設定線程名稱
run():用以表示線程活動的方法(見七中自定義線程的run方法)
rtart():啟動線程活動
is_alive():表示線程是否處于活動的狀态,結果為布爾值;
threading.active_count():傳回正在運作線程的數量
Threading.enumerate():傳回正在運作線程的清單
該部分代碼塊為;
import threading
import time
def music(name):
print('%s begin listen music%s'%(name,time.ctime()))
time.sleep(2)
print('%s stop listen music%s' % (name, time.ctime()))
def game(name):
print('%s begin play game%s'%(name,time.ctime()))
time.sleep(5)
print('%s stop play game%s' % (name,time.ctime()))
if __name__ == '__main__':
threadl = [] #線程清單,用例存放線程
#産生線程的執行個體
t1 = threading.Thread(target=music,args=('zhang',)) #target是要執行的函數名(不是函數),args是函數對應的參數,以元組的形式;
t2 = threading.Thread(target=game,args=('zhang',))
threadl.append(t1)
threadl.append(t2)
#循環清單,依次執行各個子線程
t2.setDaemon(True) #t2線程守護,setDaemon方法必須在start之前且要帶一個必填的布爾型參數
t1.setName('線程1') #設定線程的名字
for x in threadl:
print('線程為:',x.getName()) #擷取線程的名字
print('線程t1是否活動:',t1.is_alive()) #判斷線t1是否處于活動狀态
x.start()
print('正在運作線程的數量為:',threading.active_count()) #擷取正處于活動狀态線程的數量
print('正在運作線程的數量為:',threading.activeCount) #擷取正處于活動狀态線程的數量
print('正在運作線程的list為:',threading.enumerate()) #擷取正處于活動狀态線程的list
print('正在運作線程的list為:',threading._enumerate()) #擷取正處于活動狀态線程的list
#将子線程t1阻塞主線程,隻有當該子線程完成後主線程才能往下執行
print('正在運作的線程為:',threading.current_thread().getName()) #擷取目前線程的名字
print('Ending now %s'%time.ctime()) 九、GIL:cpython解釋器的’BUG’
首先需要明确的一點是GIL并不是Python的特性,它是在實作Python解析器(CPython)時所引入的一個概念。在其中的JPython就沒有GIL。然而因為CPython是大部分環境下預設的Python執行環境。是以在很多人的概念裡CPython就是Python,也就想當然的把GIL歸結為Python語言的缺陷。是以這裡要先明确一點:GIL并不是Python的特性,Python完全可以不依賴于GIL。
GIL:global interpreter lock,全局解釋器鎖。原文:
In CPython, the global interpreter lock, or GIL, is a mutex that prevents multiple native threads from executing Python bytecodes at once. This lock is necessary mainly because CPython’s memory management is not thread-safe. (However, since the GIL exists, other features have grown to depend on the guarantees that it enforces.)
也就是說:無論有多少個CPU,開啟多少線程,每次隻能執行一個線程。
基于此設計原理上,我們會覺得python的多線程其實完全沒有用,如下圖不開多線程執行的時間:
如下圖開啟多線程執行的時間:
好吧,前者是0.3秒,後者是20秒,這個結果是不是無法接受...........
import threading
import time
def add(n):
sum=0
for x in range(1,n+1):
sum+=x
print('sum =',sum)
def accumulate(n):
mul=1
for x in range(1,n+1):
mul*=x
print('mul =',mul)
if __name__ == '__main__':
thread=[]
t1=threading.Thread(target=add,args=(10000001,))
t2=threading.Thread(target=accumulate,args=(100001,))
thread.append(t1)
thread.append(t2)
starttime=time.time()
for i in thread:
i.start()
for i in thread:
i.join()
# add(1000001)
# accumulate(10001)
endtime = time.time()
print('spendtime:', endtime-starttime) GIL原理:
前者是單線程,任務串行,執行完add函數後再執行accumulate函數,不用進行線程間的切換。而在後者中,線程add和線程accumulate及主線程三者需要不斷的切換來執行,其中切換線程需要消耗大量時間和資源。是以,我們看到是後者的時間是前者的7倍左右。
但是,我們在上面的music和game線程中卻發現多線程能大大的節省時間,提高效率,那又是為什麼呢?其實,主要要看任務的類型,我們把任務分為I/O密集型和計算密集型,而多線程在切換中又分為I/O切換和時間切換。如果任務屬于是I/O密集型,若不采用多線程,我們在進行I/O操作時,勢必要等待前面一個I/O任務完成後面的I/O任務才能進行,在這個等待的過程中,CPU處于等待狀态,這時如果采用多線程的話,剛好可以切換到進行另一個I/O任務。這樣就剛好可以充分利用CPU避免CPU處于閑置狀态,提高效率。但是如果多線程任務都是計算型,CPU會一直在進行工作,直到一定的時間後采取多線程時間切換的方式進行切換線程,此時CPU一直處于工作狀态,此種情況下并不能提高性能,相反在切換多線程任務時,可能還會造成時間和資源的浪費,導緻效能下降。這就是造成上面兩種多線程結果不能的解釋。
結論:I/O密集型任務,建議采取多線程,還可以采用多程序+協程的方式(例如:爬蟲多采用多線程處理爬取的資料);對于計算密集型任務,python此時就不适用了。
十、線程同步鎖
1.為什麼需要同步鎖
看下面例子,我們自定義一個減1的函數,初始指派100,使用多線程,開啟100個線程,那麼期望的結果是最終結果為0,看下圖:
#程序鎖
import threading
import time
def subtraction():
global sum
tmp=sum
time.sleep(0.001)
sum=tmp-1
sum=100
if __name__ == '__main__':
thread=[]
for x in range(100):
t=threading.Thread(target=subtraction)
thread.append(t)
t.start()
for x in thread:
t.join()
print('sum = ',sum) 上面現象産生的原因為:我們在開啟100個線程的時候,當100個線程在進行subtraction函數操作時,首先要擷取各自的sum(漏洞:共同的資料不能共享同時被多線程操作)和tmp,但是此時多線程會按照時間規則來進行切換,如果目前面某些線程在處理sum時未結束,後面的程序已經開始了(上面例子中的代碼增加了休眠時間來展現該效果),此時拿到的sum就不再是sum-1的期望結果了,而是拿到了sum的值。這樣就會導緻,此次的線程進行自減1的操作失效了。So,就會導緻上圖的現象了,下面就講述該如何通過加同步鎖來解決該問題。 2.增加同步鎖進行處理共同資料
如下圖:
該部分代碼塊如下:
#程序鎖
import threading
import time
l=threading.Lock()
def subtraction():
global sum
l.acquire()
tmp=sum
time.sleep(0.001)
sum=tmp-1
l.release()
sum=100
if __name__ == '__main__':
thread=[]
for x in range(100):
t=threading.Thread(target=subtraction)
thread.append(t)
t.start()
for x in thread:
t.join()
print('sum = ',sum) 難點:2.1何處加鎖?何處釋放鎖?簡單的原則就是:需要在引起多線程互相沖突的共同資料部分枷鎖,例如上面例子中的sum多個線程都要使用且後面線程期望使用的應該是前面線程減1的結果;還有在資料庫操作時,使用自增主鍵時,也要對插入的資料進行加鎖,否則将可能會導緻主鍵重複。
2.2加鎖的部分代碼相當于是單線程串行運作了。 #死鎖
import threading
lockA = threading.Lock()
lockB = threading.Lock()
class Mythread(threading.Thread):
'自定義線程類'
def actionA(self):
'actionA函數中運作actionB函數,運作actionB函數前加鎖,運作actionB函數結束後釋放鎖'
lockA.acquire()
print(self.name,'運作actionA')
self.actionB()
lockA.release()
def actionB(self):
'actionB函數中運作actionA函數,運作actionA函數前加鎖,運作actionA函數結束後釋放鎖'
lockB.acquire()
print(self.name,'運作actionB')
self.actionA()
lockB.release()
def run(self):
'運作函數'
self.actionA()
self.actionB()
if __name__ == '__main__':
thread = []
for x in range(3):
t = Mythread()
thread.append(t)
print('以啟動線程:', t.getName())
t.start()
for t in thread:
t.join()
print('ending......') import threading,time
l=[1,3,4,6,8]
def pop(l):
a=l[-1]
print(a)
time.sleep(0.001)
l.remove(a)
if __name__ == '__main__':
th=[]
for x in range(3):
t = threading.Thread(target=pop, args=(l,))
th.append(t)
print(t.getName())
t.start()
for x in th:
x.join()
# pop(l)
print('l = ',l) 此處由于多線程在操作時可能拿到相同的最後一個元素值,此時若前者的線程已經删除了該元素,則後面線程的函數則無法删除該元素(remove是按元素來進行删除的)。為了解決此次共享資料導緻的多線程問題,我們可以利用前面的程序同步鎖來處理,我們可以在擷取和删除資料的時候加鎖,代碼如下: import threading,time
lock = threading.Lock()
l=[1,3,4,6,8]
def pop(l):
# lock.acquire()
a=l[-1]
print(a)
time.sleep(0.001)
l.remove(a)
# lock.release()
if __name__ == '__main__':
th=[]
for x in range(3):
t = threading.Thread(target=pop, args=(l,))
th.append(t)
print(t.getName())
t.start()
for x in th:
x.join()
# pop(l)
print('l = ',l) 在該部分,我們引入新的子產品queue(線程隊列)來解決該問題,如下圖所示:

該部分代碼塊如下: import threading,time
import queue #線程隊列
l=[1,3,4,6,8]
def pop(l):
a=l[-1]
print('a = ',a)
time.sleep(0.001)
l.remove(a)
if __name__ == '__main__':
q = queue.Queue()
for x in range(3):
t = threading.Thread(target=pop, args=(l,))
q.put(t)
while not q.empty():
data = q.get()
print('目前執行的線程:', data.getName())
data.run()
print('l = ',l) import queue #線程隊列
num=5
#num用例限制隊列中插入元素的個數,可不填
q1 = queue.Queue(num) #三種存取資料的順序,1.先進先出(FIFO,不指明方式則預設該方式);2.先進後出(LIFO);3.按優先級進出()
q1.put(123)
q1.put('you')
q1.put({'name':'zhangzhou'})
q2 = queue.LifoQueue(num)
q2.put(123)
q2.put('you')
q2.put({'name':'zhangzhou'})
q3 = queue.PriorityQueue()
q3.put([2,123])
q3.put([3,'you'])
q3.put([1,{'name':'zhangzhou'}])
if __name__ == '__main__':
while not q1.empty():
data = q1.get()
print('------------',data,'------------')
while not q2.empty():
data = q2.get()
print('------------',data,'------------')
while not q3.empty():
data = q3.get()
print('------Priority=',data[0],'value=',data[1],'-------')