錯誤方式
@Test
public void testDeserializeTest() throws IOException, ClassNotFoundException {
ByteArrayOutputStream baos = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(baos);
BigInteger bi = new BigInteger("0");
oos.writeObject(bi);
String str = baos.toString();
System.out.println(str);
ObjectInputStream ois = new ObjectInputStream(
new BufferedInputStream(new ByteArrayInputStream(str.getBytes())));
Object obj = ois.readObject();
assertEquals(obj.getClass().getName(), "java.math.BigInteger");
assertEquals(((BigInteger) obj).intValue(), 0);
} 正确方式
@Test
public void testDeserialize() throws IOException, ClassNotFoundException {
ByteArrayOutputStream baos = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(baos);
BigInteger bi = new BigInteger("0");
oos.writeObject(bi);
byte[] str = baos.toByteArray();
ObjectInputStream ois = new ObjectInputStream(new BufferedInputStream(new ByteArrayInputStream(str)));
Object obj = ois.readObject();
assertNotNull(obj);
assertEquals(obj.getClass().getName(), "java.math.BigInteger");
assertEquals(((BigInteger) obj).intValue(), 0);
} 原因是由于:
将字 ByteArrayOutputStream對象調用為toString轉為為字元串時,會将 ObjectOutputStream對象放置在對象流頭部的前兩個位元組(0xac)(0xed)序列化為兩個“?”
當這個字元串使用getByte()時會将兩個“?”變為(0x3f )(0x3f) 。然而這兩個字元并不構成有效的對象流頭。是以轉化對象時候會失敗。
測試代碼 單元測試無法輸出結果這裡用main測試
1 public static void main(String[] args) throws IOException {
2 ByteArrayOutputStream baos = new ByteArrayOutputStream();
3 ObjectOutputStream oos = new ObjectOutputStream(baos);
4 String s = "111";
5 oos.writeObject(s);
6 String str = baos.toString();
7 byte[] baStr = baos.toByteArray();
8 byte[] gbStr = str.getBytes();
9 byte[] testStr = baStr;
10 StringBuffer sb = new StringBuffer();
11 for (int i = 0; i < testStr.length; i++) {
12 sb.append(Integer.toBinaryString(testStr[i]) + " ");
13 }
14 System.out.println(sb.toString());
15 } 1.如果将6行的str直接列印在頁面上 則顯示如下結果
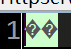
2.将第9行賦予baStr 則得到的二進制首兩位值為
11111111111111111111111110101100(0xac) 11111111111111111111111111101101(0xed)
3.将第9行賦予gbStr 則得到的二進制首兩位值為
11111111111111111111111111101111(0xef) 11111111111111111111111110111111(0xbf)
(由于字元集和英文原作者不一樣是以解析出來的結果也不一樣)
發現字元被改變了以至于ObjectOutputStream無法識别該字元數組是以抛出了java.io.StreamCorruptedException: invalid stream header: EFBFBDEF
是以筆者建議:
1.使用 toByteArray()代替toString() ,使用 ByteArrayInputStream(byte [])構造函數。
2.使用base64轉換為字元串
注:LZ出現這個問題是因為在maven打包項目的時候重新編譯了項目中的二進制檔案進而破壞了二進制檔案的完整性。是以該檔案無法反序列化。
附:maven打包跳過二進制檔案
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-resources-plugin</artifactId>
<configuration>
<!-- 防止二進制檔案被編譯 -->
<nonFilteredFileExtensions>
<nonFilteredFileExtension>dat</nonFilteredFileExtension>
<nonFilteredFileExtension>swf</nonFilteredFileExtension>
<nonFilteredFileExtension>xml</nonFilteredFileExtension>
</nonFilteredFileExtensions>
</configuration>
</plugin>
</plugins> 英文原文:
http://bugs.sun.com/bugdatabase/view_bug.do?bug_id=4968673
The provided test code serializes an object to a ByteArrayOutputStream, converts the generated byte array into a string using the ByteArrayOutputStream.toString() method, converts the string back into a byte array using the String.getBytes() method, and then attempts to deserialize the object from the byte array using a ByteArrayInputStream. This procedure will in most cases fail because of the transformations that take place within ByteArrayOutputStream.toString() and String.getBytes(): in order to convert the contained sequence of bytes into a string, ByteArrayOutputStream.toString() decodes the bytes according to the default charset in effect; similarly, in order to convert the string back into a sequence of bytes, String.getBytes() encodes the characters according to the default charset. Converting bytes into characters and back again according to a given charset is generally not an identity-preserving operation. As the javadoc for the String(byte[], int, int) constructor (which is called by ByteArrayOutputStream.toString()) states, "the behavior ... when the given bytes are not valid in the default charset is unspecified". In the test case provided, the first two bytes of the serialization stream, 0xac and 0xed (see java.io.ObjectStreamConstants.STREAM_MAGIC), both get mapped to the character '?' since they are not valid in the default charset (ISO646-US in the JDK I'm running). The two '?' characters are then mapped back to the byte sequence 0x3f 0x3f in the reconstructed data stream, which do not constitute a valid header. The solution, from the perspective of the test case, is to use ByteArrayOutputStream.toByteArray() instead of toString(), which will yield the raw byte sequence; this can then be fed directly to the ByteArrayInputStream(byte[]) constructor. 原文位址 http://blog.sina.com.cn/s/blog_61f4999d0100yi89.html