首先,Shell是發明這個算法的人名,不是這個算法的思想或者特點。
希爾排序,也稱為增量遞減排序。基本思路,是把原來的序列,等效視為一個矩陣的形式。矩陣的列數,也稱為寬度或者增量,記為w。
假設數組A[n]以及矩陣B[][],對于兩者的對應關系,可以記為A[k]=B[k/w][k%w]。也就是說,A中的元素會按照先行後列的順序排列,即先左後右、先上後下的順序放入矩陣B中。
對于增量或者說矩陣的寬度w,會有許多政策進行選擇。假設w={1,2,4,8,16,32...}。從w的集合中選擇小于數組元素數量n的最大元素w[i],并且選取w[0]到w[i]之間的所有增量,從w[i]開始,按照矩陣B中的每一列進行排序。這裡的排序必須是輸入敏感的,通常采用插入排序。本次完成後,取下一個w,再按照每列進行排序。直到w=1,矩陣退化為向量,排序完成。
1 int max(int* H, int n, int size)
2 {
3 int i = 0;
4 while (i < n&&size > H[i]) i++;
5 return i - 1;
6 }
7 void shellSort(int* A, int lo, int hi)//[lo,hi)
8 {
9 int H[11] = { 1,5,19,41,109,209,505,929,2161,3905,8929 };
10 int size = hi - lo;
11 int gap = max(H,11,size);//選取小于規模的最大增量
12 for (int t = gap; t >= 0; t--)//從W[gap]一直到w=1,遞減增量
13 {
14 int w = H[t];//選取步長,w即增量也是寬度(列數)
1516 for (int k = 0; k < w; k++)//對于每一列
17 {
18 for (int i = lo + w; i < hi; i += w)//下面的循環即插入排序
19 {
20 int j = i - w;
21 int tmp = A[i];
22 while ((j >= lo) && (A[j] > tmp))
23 {
24 A[j + w] = A[j];
25 j -= w;
26 }
27 A[j + w] = tmp;
28 }//一列的插入排序結束
29 }//每列都進行插入排序
30 }
31 } 希爾排序的總體政策,就是通過按列排序,使得每次排序後的局部有序性增加,最後達到全序列排序的目的。具體的證明可以參考《資料結構C++語言版》,有比較詳細的h-有序和(g,h)-有序以及有序性增加的介紹。
下面是一個n=12,w{1,5}的過程。可以看到,w=5排序過後,有序性确實會有一定增加。
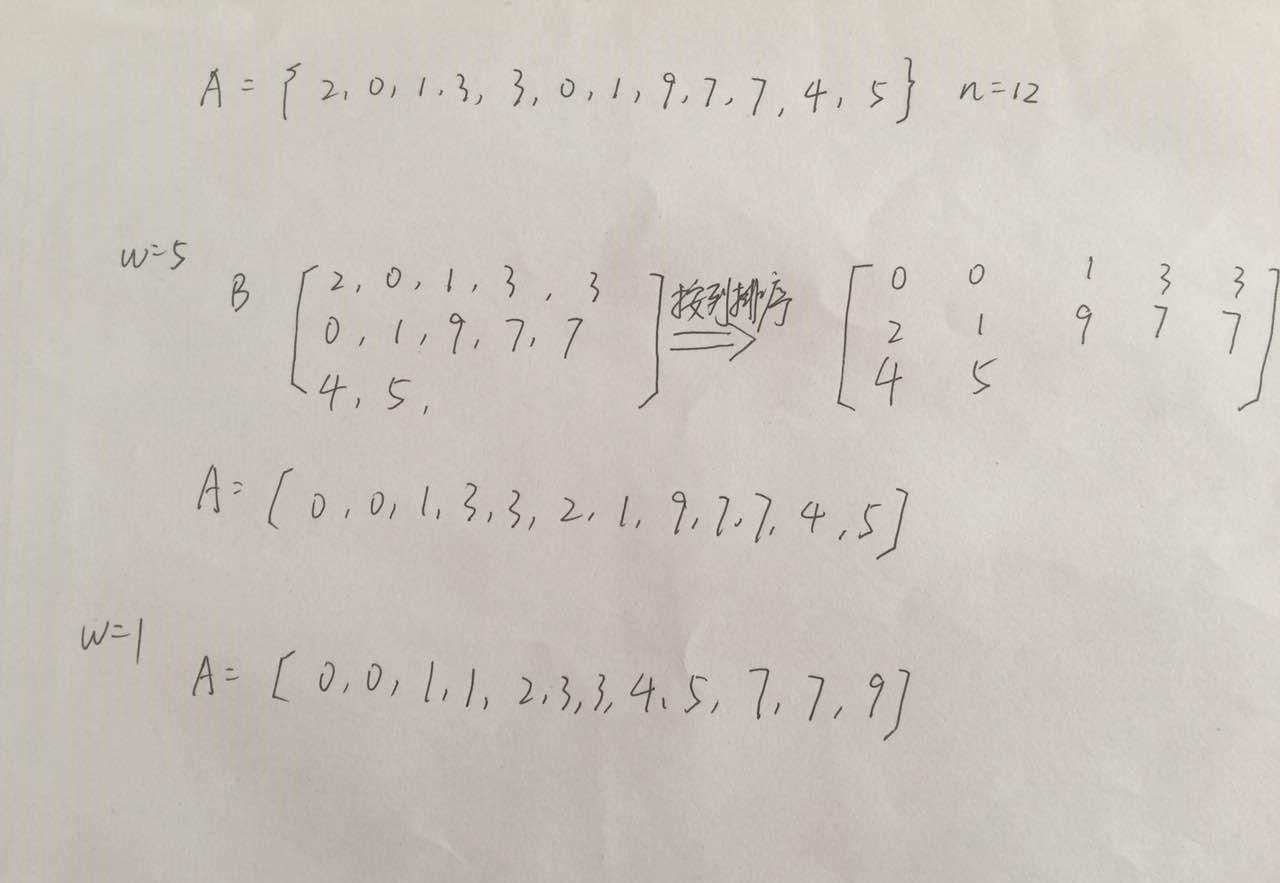
希爾排序的複雜度,取決于增量序列w的選擇。幾個比較優秀的序列,Pratt序列{1,2,3,4,6,8,9,12,..2^p*3^q,...}。這個序列的缺點很明顯,會造成排序疊代次數很多,不過時間複雜度可以達到O(nlog^2n)。Sedgewick序列{1,5,19,41,109,209,505,929,2161,3905,8929...}的時間扶再度在最壞情況下可以為O(n^(4/3)),最好情況下為O(n^(7/6).