HBASE的叢集的搭建
HBASE的表設計
HBASE的底層存儲模型
HBase 是一個高可靠、高性能、面向列、可伸縮的分布式緩存系統、
利用HBase 技術可在廉價PC Server上搭建起大規模結構化存儲叢集
HBase利用hadoop hdfs作為起檔案存儲系統,利用hadoop mapreduce
來處理HBase中的海量資料,利用zookeeper作為協調工具。
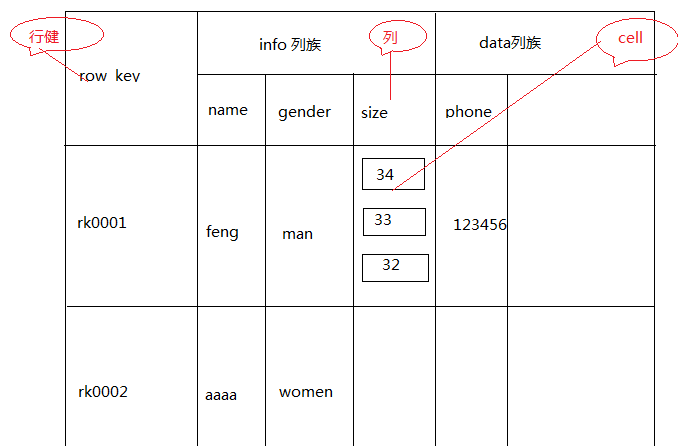
主鍵: Row Key
主鍵是用來減速記錄的主鍵,通路hbase table中的行,隻有3種方式
1. 通過單個row key 通路
2. 通過row key 的range
3. 全表掃描
列族: Column Family
列族在建立表的時候聲明,第一個列族可以包含多個列,列中的資料都是以二進制形式存在,沒有資料類型。
時間戳 timestamp
HBase 中通過row 和columns 确定的為一個存儲單元稱為cell。 每個cell都保持着同一份資料的多個版本,
版本通過時間戳來索引。
配置hbase
1. hbase-env.sh
export JAVA_HOME=/data/jdk/
2.vim hbase-site.xml
<configuration>
<property>
<name>hbase.rootdir</name>
<value>file:///data/hbase/data/</value>
</property>
</configuration>
3. 啟動hbase
/data/hbase/bin/start-hbase.sh
4.使用指令操作
[root@hbase1 bin]# ./hbase
Usage: hbase [<options>] <command> [<args>]
Commands:
Some commands take arguments. Pass no args or -h for usage.
shell Run the HBase shell
hbck Run the hbase 'fsck' tool
hlog Write-ahead-log analyzer
snapshot Create a new snapshot of a table
snapshotinfo Tool for dumping snapshot information
hfile Store file analyzer
zkcli Run the ZooKeeper shell
upgrade Upgrade hbase
master Run an HBase HMaster node
regionserver Run an HBase HRegionServer node
zookeeper Run a Zookeeper server
rest Run an HBase REST server
thrift Run the HBase Thrift server
thrift2 Run the HBase Thrift2 server
clean Run the HBase clean up script
classpath Dump hbase CLASSPATH
mapredcp Dump CLASSPATH entries required by mapreduce
pe Run PerformanceEvaluation
ltt Run LoadTestTool
canary Run the Canary tool
version Print the version
CLASSNAME Run the class named CLASSNAME
5. 運作hbase shell
[root@hbase1 bin]# ./hbase shell
6. 建立表,列族
hbase(main):001:0> help create (檢視資料庫幫組)
hbase(main):001:0> create 't1', {NAME => 'f1'}, {NAME => 'f2'}, {NAME => 'f3'} 建立t1表, 列祖為 f1,f2,f3
hbase(main):003:0> create 'people', {NAME => 'info',VERSIONS => 3},{NAME => 'data',VERSIONS => 1}
hbase(main):004:0> list 檢視hbase中所有的表
hbase(main):005:0> scan 'people' 檢視people 表中的資料
hbase(main):006:0> describe 'people 檢視people 表中的資料結構
hbase(main):007:0> put 'people', 'rk0001' ,'info:name','feng' 插入資料
表 row key 列族:列
hbase(main):020:0> scan 'people' 查詢結果全盤掃描
ROW COLUMN+CELL
rk0001 column=info:name, timestamp=1479361079185, value=feng
再次添加屬性
hbase(main):021:0> put 'people' ,'rk0001','info:gender','man'
再此查詢,顯示一行
hbase(main):022:0> scan 'people'
rk0001 column=info:gender, timestamp=1479361501486, value=man
rk0001 column=info:name, timestamp=1479361079185, value=feng
1 row(s) in 0.0200 seconds
hbase(main):026:0> put 'people','rk0001','info:size','34'
0 row(s) in 0.0150 seconds
hbase(main):028:0> scan 'people'
rk0001 column=info:size, timestamp=1479361885383, value=34
1 row(s) in 0.0210 seconds
在data列族,建立 phone列
hbase(main):030:0> put 'people','rk0001','data:phone','123456789'
0 row(s) in 0.0090 seconds
hbase(main):031:0> scan 'people'
rk0001 column=data:phone, timestamp=1479362039723, value=123456789
rk0001 column=info:size, timestamp=1479361885383, value=34
1 row(s) in 0.0190 seconds
建立新row key 列族
hbase(main):032:0> put 'people','rk0002','info:name','laomao'
0 row(s) in 0.0110 seconds
hbase(main):036:0> scan 'people'
rk0002 column=info:name, timestamp=1479362256298, value=laomao
2 row(s) in 0.0320 seconds
hbase(main):037:0> put 'people','rk0002','info:book','.國'
hbase(main):038:0> scan 'people'
rk0002 column=info:book, timestamp=1479363113630, value=\xE4\xB8\xAD\xE5\x9B\xBD
2 row(s) in 0.0150 seconds
############################################################
在 info:size 列 插入資料
1. put 'people' ,'rk0001','info:size','33'
2. put 'people' ,'rk0001','info:size','32'
rk0001 column=info:size, timestamp=1479361885383, value=32
由于建立列族時,使用了version=3 ,是以保留了3個版本
scan 'people',{COLUMNS => 'info:size',VERSIONS => 3}
再次插入資料,隻保留3個versions,記憶體中還沒有删除
put 'people' ,'rk0001','info:size','31'
scan 'people', {RAW => true, VERSIONS => 10}
hbase 叢集配置
192.168.20.190 hmaster1 HMaster
192.168.20.191 hmaster2 HMaster
192.168.20.194 hregionserver1 hregionserver
192.168.20.195 hregionserver2 hregionserver
[root@hbase1 conf]# vim hbase-env.sh
export HBASE_MANAGES_ZK=false
[root@hbase1 conf]# vim hbase-site.xml
<!-- 指定hbase 在HDFS上存儲路徑---->
<value>hdfs://ns1/hbase/</value>
<!-- 指定hbase是分布式-->
<name>hbase.cluster.distributed</name>
<value>true</value>
<!--指定zk的位址, 多個用"," 分隔 -->
<name>hbase.zookeeper.quorum</name>
<value>zookeeper1:2181,zookeeper2:2181,zookeeper3:2181</value>
配置hbase(hmster) 小弟
[root@hbase1 conf]# vim regionservers
hregionserver1
hregionserver2
拷貝hadoop的 core-site.xml 和 hdfs-site.xml 到 hbase的 conf目錄
[root@hmaster1 conf]# cp /data/hadoop/etc/hadoop/core-site.xml /data/hbase/conf/
[root@hmaster1 conf]# cp /data/hadoop/etc/hadoop/hdfs-site.xml /data/hbase/conf/
從hmaster1 拷貝hbase 到其他節點
[root@hmaster1 data]# scp -r hbase 192.168.20.191:/data/
[root@hmaster1 data]# scp -r hbase 192.168.20.194:/data/
[root@hmaster1 data]# scp -r hbase 192.168.20.195:/data/
設定hbase權限,使用者名為hadoop
[root@hmaster1 data]# chown -R hadoop.hadoop /data/hbase
[root@hmaster2 data]# chown -R hadoop.hadoop /data/hbase
[root@hregionserver1 data]# chown -R hadoop.hadoop /data/hbase
[root@hregionserver2 data]# chown -R hadoop.hadoop /data/hbase
在hmaster1上設定免登陸,用于啟動hregionserver 程序
[hadoop@hmaster1 bin]$ ssh-keygen -t rsa
[hadoop@hmaster1 bin]$ ssh-copy-id -i .ssh/id_rsa.pub hadoop@hregionserver1
[hadoop@hmaster1 bin]$ ssh-copy-id -i .ssh/id_rsa.pub hadoop@hregionserver2
在hmaster2上設定免登陸,用于啟動hregionserver 程序
[hadoop@hmaster2 bin]$ ssh-keygen -t rsa
[hadoop@hmaster2 bin]$ ssh-copy-id -i .ssh/id_rsa.pub hadoop@hregionserver1
[hadoop@hmaster2 bin]$ ssh-copy-id -i .ssh/id_rsa.pub hadoop@hregionserver2
在hmaster1上 使用hadoop的使用者啟動 hbase 程序
[hadoop@hmaster1 bin]$ ./start-hbase.sh
[hadoop@hmaster1 bin]$ jps
7186 Jps
6696 HMaster
[root@hregionserver1 ~]# jps
4242 Jps
3740 HRegionServer
[root@hregionserver2 ~]# jps
4164 Jps
3686 HRegionServer
打開hmaster1 通路頁面
http://192.168.20.190:60010
在hmaster2上 使用hadoop的使用者啟動 hbase 程序
[hadoop@hmaster2 bin]$ ./hbase-daemon.sh start master
HBase 常用Shell指令
進入hbase shell console
$HBASE_HOME/bin/hbase shell
如果有kerberos認證,需要事先使用相應的keytab進行一下認證(使用kinit指令),認證成功之後再使用hbase shell進入可以使用whoami指令可檢視目前使用者
hbase(main)> whoami
表的管理
1)檢視有哪些表
hbase(main)> list
2)建立表
# 文法:create <table>, {NAME => <family>, VERSIONS => <VERSIONS>}
# 例如:建立表t1,有兩個family name:f1,f2,且版本數均為2
hbase(main)> create 't1',{NAME => 'f1', VERSIONS => 2},{NAME => 'f2', VERSIONS => 2}
3)删除表
分兩步:首先disable,然後drop
例如:删除表t1
hbase(main)> disable 't1'
hbase(main)> drop 't1'
4)檢視表的結構
# 文法:describe <table>
# 例如:檢視表t1的結構
hbase(main)> describe 't1'
5)修改表結構
修改表結構必須先disable
# 文法:alter 't1', {NAME => 'f1'}, {NAME => 'f2', METHOD => 'delete'}
# 例如:修改表test1的cf的TTL為180天
hbase(main)> disable 'test1'
hbase(main)> alter 'test1',{NAME=>'body',TTL=>'15552000'},{NAME=>'meta', TTL=>'15552000'}
hbase(main)> enable 'test1'
權限管理
1)配置設定權限
# 文法 : grant <user> <permissions> <table> <column family> <column qualifier> 參數後面用逗号分隔
# 權限用五個字母表示: "RWXCA".
# READ('R'), WRITE('W'), EXEC('X'), CREATE('C'), ADMIN('A')
# 例如,給使用者‘test'配置設定對表t1有讀寫的權限,
hbase(main)> grant 'test','RW','t1'
2)檢視權限
# 文法:user_permission <table>
# 例如,檢視表t1的權限清單
hbase(main)> user_permission 't1'
3)收回權限
# 與配置設定權限類似,文法:revoke <user> <table> <column family> <column qualifier>
# 例如,收回test使用者在表t1上的權限
hbase(main)> revoke 'test','t1'
表資料的增删改查
1)添加資料
# 文法:put <table>,<rowkey>,<family:column>,<value>,<timestamp>
# 例如:給表t1的添加一行記錄:rowkey是rowkey001,family name:f1,column name:col1,value:value01,timestamp:系統預設
hbase(main)> put 't1','rowkey001','f1:col1','value01'
用法比較單一。
2)查詢資料
a)查詢某行記錄
# 文法:get <table>,<rowkey>,[<family:column>,....]
# 例如:查詢表t1,rowkey001中的f1下的col1的值
hbase(main)> get 't1','rowkey001', 'f1:col1'
# 或者:
hbase(main)> get 't1','rowkey001', {COLUMN=>'f1:col1'}
# 查詢表t1,rowke002中的f1下的所有列值
hbase(main)> get 't1','rowkey001'
b)掃描表
# 文法:scan <table>, {COLUMNS => [ <family:column>,.... ], LIMIT => num}
# 另外,還可以添加STARTROW、TIMERANGE和FITLER等進階功能
# 例如:掃描表t1的前5條資料
hbase(main)> scan 't1',{LIMIT=>5}
c)查詢表中的資料行數
# 文法:count <table>, {INTERVAL => intervalNum, CACHE => cacheNum}
# INTERVAL設定多少行顯示一次及對應的rowkey,預設1000;CACHE每次去取的緩存區大小,預設是10,調整該參數可提高查詢速度
# 例如,查詢表t1中的行數,每100條顯示一次,緩存區為500
hbase(main)> count 't1', {INTERVAL => 100, CACHE => 500}
3)删除資料
a )删除行中的某個列值
# 文法:delete <table>, <rowkey>, <family:column> , <timestamp>,必須指定列名
# 例如:删除表t1,rowkey001中的f1:col1的資料
hbase(main)> delete 't1','rowkey001','f1:col1'
注:将删除改行f1:col1列所有版本的資料
b )删除行
# 文法:deleteall <table>, <rowkey>, <family:column> , <timestamp>,可以不指定列名,删除整行資料
# 例如:删除表t1,rowk001的資料
hbase(main)> deleteall 't1','rowkey001'
c)删除表中的所有資料
# 文法: truncate <table>
# 其具體過程是:disable table -> drop table -> create table
# 例如:删除表t1的所有資料
hbase(main)> truncate 't1'
Region管理
1)移動region
# 文法:move 'encodeRegionName', 'ServerName'
# encodeRegionName指的regioName後面的編碼,ServerName指的是master-status的Region Servers清單
# 示例
hbase(main)>move '4343995a58be8e5bbc739af1e91cd72d', 'db-41.xxx.xxx.org,60020,1390274516739'
2)開啟/關閉region
# 文法:balance_switch true|false
hbase(main)> balance_switch
3)手動split
![如果你的夢想是成為一名程式員,那可能需要看看這篇文章![圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)