原文位址
簡單易用,Storm讓大資料分析變得輕而易舉。
如今,公司在日常運作中經常會産生TB(terabytes)級的資料。資料來源包括從網絡傳感器捕獲的,到Web,社交媒體,交易型業務資料,以及其他業務環境中建立的資料。考慮到資料的生成量,實時計算(real-time computation )已成為很多組織面臨的一個巨大挑戰。我們已經有效地使用了一個可擴充的實時計算系統——開源的 Storm 工具,它是有 Twitter 開發,通常被稱為“實時 Hadoop(real-time Hadoop)”。然而,Storm 遠遠比 Hadoop 簡單,因為它并不需要掌握新技術處理大資料。
本文介紹了如何使用 Storm。示例項目稱之為“超速警報系統(Speeding Alert System),”分析實時資料,當車速超過一個預定義的門檻值(threshold)時,觸發一個 trigger,相關資料就會儲存到資料庫中。
什麼是Storm
Hadoop 依靠批量處理(batch processing),而 Storm 是一個實時的(real-time),分布式的(distributed),容錯的(fault-tolerant),計算系統。像 Hadoop,它可以保證可靠性處理大量的資料,但不能實時;也就是說,每個消息都将被處理。Storm 也提供這些特性,如容錯,分布式計算,這些使它适合在不同機器上處理大規模資料。它還具有如下特性:
- 簡擴充。若想擴充,你隻需添加裝置和改變 topology 的并行性設定。用于叢集協調的 Hadoop Zookeeper 用在 Storm 使得它非常容易擴充。
- 保證每個消息都被處理。
- Storm 叢集(cluster)很容易管理。
- 容錯性:一旦 topology 被送出,Storm 運作 topology,直到它被殺掉或叢集被關閉。此外,如果執行期間發生錯誤,那麼重新配置設定的任務由 Storm 處理。
- Storm 的 topology 可以用任何語言定義,但通常還是用 Java。
文章接下來的部分,你首先需要安裝和建立 Storm。步驟如下:
- Storm 官方站點下載下傳 Storm.
- 解壓,将 bin/ 添加到你的環境變量 PATH,保證 bin/storm 腳本可執行。
Hadoop Map/Reduce 的資料處理過程是,從HDFS中擷取資料,分片後,進行分布式處理,最終輸出結果。
Hadoop 與 Storm 的概念對比,如下表所示:
| Hadoop | Storm |
| JobTracker | Nimbus |
| TaskTracker | Supervisor |
| Child | Worker |
| Job | Topology |
| Mapper/Reducer | Spout/Bolt |
Twitter 列舉了Storm的三大類應用:
1. 資訊流處理(Stream processing)。Storm可用來實時處理新資料和更新資料庫,兼具容錯性和可擴充性。即Storm可以用來處理源源不斷流進來的消息,處理之後将結果寫入到某個存儲中去。
2. 連續計算(Continuous computation)。Storm可進行連續查詢并把結果即時回報給用戶端。比如把Twitter上的熱門話題發送到浏覽器中。
3. 分布式遠端程式調用(Distributed RPC)。Storm可用來并行處理密集查詢。Storm的拓撲結構是一個等待調用資訊的分布函數,當它收到一條調用資訊後,會對查詢進行計算,并傳回查詢結果。舉個例子Distributed RPC可以做并行搜尋或者處理大集合的資料。
通過配置drpc伺服器,将storm的topology釋出為drpc服務。用戶端程式可以調用drpc服務将資料發送到storm叢集中,并接收處理結果的回報。這種方式需要drpc伺服器進行轉發,其中drpc伺服器底層通過thrift實作。适合的業務場景主要是實時計算。并且擴充性良好,可以增加每個節點的工作worker數量來動态擴充。
4. 項目實施,建構Topology。
Storm元件
Storm 叢集主要由主節點(master)和工作節點(worker node)組成,它們通過 Zookeeper 進行協調。Nimbus類似Hadoop裡面的 JobTracker。Nimbus 負責在叢集裡面分發代碼,配置設定計算任務給機器, 并且監控狀态。
主節點(master)——Nimbus
主節點運作一個守護程序(daemon),Nimbus,它負責在叢集中分布代碼,配置設定任務(Task)并監測故障。它類似于 Hadoop 的 Job Tracker。
工作者節點(worker node)——Supervisor
工作節點同樣會運作一個守護程序,Supervisor,它監聽已配置設定的工作,并按要求運作工作程序。每個工作節點都執行一個 topology 的子集。Nimbus 和 Supervisor 之間的協調是由 Zookeeper 或其叢集來管理。
Zookeeper
Zookeeper 負責 Supervisor 和 Nimbus 之間的協調。一個實時應用程式的邏輯被封裝到一個 Storm 的“topology”中。一個 topology 是由一組 spouts(資料源)和 bolts(資料操作)組成,通過 Stream Groupings 連接配接(協調)。下面更進一步說明這些術語。
Spout
簡單來說,一個 spout 在 topology 中從一個源中讀取資料。spout 可以是可靠的,也可以是不可靠的。如果 Storm 處理失敗,那麼一個可靠的 spout 可以確定重新發送元組(它是一個資料項的有序清單)。一個不可靠的 spout,元組一旦發送,它不會跟蹤。spout 中的主要方法是 nextTuple()。該種方法或者向 topology 發出一個新元組,或是直接傳回,如果沒有什麼可發。
Bolt
bolt 負責所有處理處理 topology 發生的一切。 bolt 可做從過濾到連接配接,聚合,寫檔案/資料庫等等任何事。bolt 從一個 spout 接收資料來處理,在複雜流轉換中,它可以進一步發出元組到另一個 bolt。bolt 中主要方法是 execute(),它接受一個元組作為輸入。在 spout 和 bolt,發動元組到更多的流,可以在 declareStream() 中聲明和指定流。
Stream Grouping
stream grouping 定義流在 bolt 任務之間如何被劃分。Storm 提供了内置的流分組:随機分組(shuffle grouping),域組域(fields grouping),所有分組(all grouping),單一分組(one grouping),直接分組(direct grouping)和本地/随機分組(local/shuffle grouping)。自定義分組實作可以使用 CustomStreamGrouping 接口。
- 随機分組(Shuffle grouping):随機分發tuple到Bolt的任務,保證每個任務獲得相等數量的tuple。
- 字段分組(Fields grouping):根據指定字段分割資料流,并分組。例如,根據“user-id”字段,相同“user-id”的元組總是分發到同一個任務,不同“user-id”的元組可能分發到不同的任務。
- 全部分組(All grouping):tuple被複制到bolt的所有任務。這種類型需要謹慎使用。
- 全局分組(Global grouping):全部流都配置設定到bolt的同一個任務。明确地說,是配置設定給ID最小的那個task。
- 無分組(None grouping):你不需要關心流是如何分組。目前,無分組等效于随機分組。但最終,Storm将把無分組的Bolts放到Bolts或Spouts訂閱它們的同一線程去執行(如果可能)。
- 直接分組(Direct grouping):這是一個特别的分組類型。元組生産者決定tuple由哪個元組處理者任務接收。
另外,還涉及其他概念。
Task
worker 中每一個 spout/bolt 的線程稱為一個 task。在 storm0.8 之後,task 不再與實體線程對應,同一個 spout/bolt 的 task 可能會共享一個實體線程,該線程稱為 executor。
Tuple
一次消息傳遞的基本單元。本來應該是一個 key-value 的 map,但是由于各個元件間傳遞的tuple的字段名稱已經事先定義好,是以,tuple 中隻要按序填入各個value 就行了,是以就是一個 value list。
storm中運作的一個實時應用程式,因為各個元件間的消息流動形成邏輯上的一個拓撲結構。一個topology是spouts和bolts組成的圖, 通過stream groupings将圖中的spouts和bolts連接配接起來,如下圖:
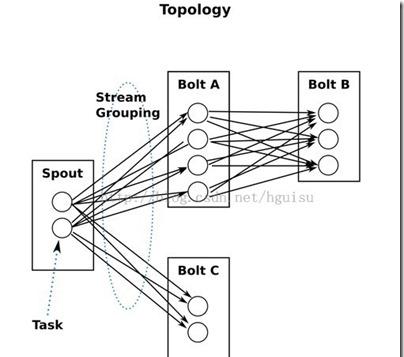
一個 topology 會一直運作,直到你 kill 掉它,Storm自動地重新配置設定執行失敗的任務, 并且Storm可以保證你不會有資料丢失(如果開啟了高可靠性的話)。如果一些機器意外停機它上面的所有任務會被轉移到其他機器上。
運作一個topology很簡單。首先,把你所有的代碼以及所依賴的jar打進一個jar包。然後運作類似下面的這個指令:
storm jar all-my-code.jar backtype.storm.MyTopology arg1 arg2 這個指令會運作主類: backtype.strom.MyTopology, 參數是arg1, arg2。這個類的main函數定義這個topology并且把它送出給Nimbus。storm jar負責連接配接到Nimbus并且上傳jar包。
Topology的定義是一個Thrift結構,并且Nimbus就是一個Thrift服務, 你可以送出由任何語言建立的topology。上面的方面是用JVM-based語言送出的最簡單的方法。
Stream
源源不斷傳遞的tuple就組成了stream。消息流stream是storm裡的關鍵抽象。一個消息流是一個沒有邊界的tuple序列, 而這些tuple序列會以一種分布式的方式并行地建立和處理。通過對stream中tuple序列中每個字段命名來定義stream。在預設的情況下,tuple的字段類型可以是:integer,long,short, byte,string,double,float,boolean和byte array。你也可以自定義類型(隻要實作相應的序列化器)。
每個消息流在定義的時候會被配置設定給一個id,因為單向消息流使用的相當普遍, OutputFieldsDeclarer 定義了一些方法讓你可以定義一個stream而不用指定這個id。在這種情況下這個stream會配置設定個值為‘default’預設的id 。
Storm提供的最基本的處理stream的原語是spout和bolt。你可以實作spout和bolt提供的接口來處理你的業務邏輯。

實作
對于我們的示例中,我們設計了一個 spout 和 bolt 的 topology,可以處理大量規模資料(日志檔案),設計觸發一個報警,當一個特定值超過預設門檻值時。使用 Storm 的 topology,日志檔案按行讀取,topology 監控到來的資料。在 Storm 元件,spout 讀取到來的資料。它不僅從現存的檔案中讀取資料,也監控新檔案。一旦檔案被修改,spout 讀取新條目,轉換為元組(一個可以被 bolt 讀取的格式)後,把元組發出到 bolt 執行門檻值分析,查找任何超過門檻值的記錄。
門檻值分析(Threshold Analysis)
本節主要集中兩種類型的門檻值(threshold)分析:瞬時門檻值(instant thershold)和時間序列門檻值(time series threshold)。
- 瞬時門檻值監測:一個字段的值在那個瞬間超過了預設的臨界值,如果條件符合的話則觸發一個trigger。舉個例子當車輛超越80公裡每小時,則觸發trigger。
- 時間序列門檻值監測:字段的值在一個給定的時間段内超過了預設的臨界值,如果條件符合則觸發一個觸發器。比如:在5分鐘内,時速超過80公裡每小時兩次及以上的車輛。
清單 1 顯示一個我們使用的日志檔案,它包含車輛資料資訊,例如車輛号碼,速度,位置。
清單 1:日志檔案,通過檢查點的車輛資訊
AB 123, 60, North city BC 123, 70, South city CD 234, 40, South city DE 123, 40, East city EF 123, 90, South city GH 123, 50, West city 建立相應的XML檔案,它由到來的資料格式組成。用于解析日志檔案。架構 XML 及其相應的描述如下表所示。
XML檔案和日志檔案都被 spout 随時監測,本例使用的 topology 如下圖所示。
圖 1:Storm中建立的 topology,以處理實時資料
如圖1所示,FilelistenerSpout 接收輸入日志,并逐行讀取,把資料發送給 ThresoldCalculatorBolt 進一步的門檻值處理。一旦處理完成,根據門檻值計算的行被發動到 DBWriterBolt,持久化到資料庫(或發出報警)。這個過程的具體實作将在下面介紹。
Spout 實作
spout 把日志檔案和XML描述符檔案作為輸入。該XML檔案指定了日志檔案的格式。現在考慮一個例子的日志檔案,它包含車輛資訊,如車輛号碼,速度,位置等三個資訊。如圖 2 所示。
圖 2:資料從日志檔案到 spout 的流程圖
清單 2 顯示了tuple對應的XML,其中指定了字段、将日志檔案切割成字段的定界符以及字段的類型。XML檔案以及資料都被儲存到Spout指定的路徑。
清單 2:用以描述日志檔案的XML檔案
<TUPLEINFO> <FIELDLIST> <FIELD> <COLUMNNAME>vehicle_number</COLUMNNAME> <COLUMNTYPE>string</COLUMNTYPE> </FIELD> <FIELD> <COLUMNNAME>speed</COLUMNNAME> <COLUMNTYPE>int</COLUMNTYPE> </FIELD> <FIELD> <COLUMNNAME>location</COLUMNNAME> <COLUMNTYPE>string</COLUMNTYPE> </FIELD> </FIELDLIST> <DELIMITER>,</DELIMITER> </TUPLEINFO> 構造函數用參數 Directory、PathSpout 和 TupleInfo 對象建立 Spout 對象。TupleInfo 儲存與日志檔案相關的必要資訊,如字段、分隔符、字段類型等。該對象通過XSTream序列化XML來建建。
Spout實作步驟:
- 監聽一個單獨日志檔案的變化。監控目錄是否添加新的日志檔案。
- 聲明字段後,把 spout 讀取行轉換成 tuple。
- 聲明Spout和Bolt之間的分組,并決定tuple發送給Bolt的方式。
Spout 代碼如下清單 3 所示。
清單 3:Spout中 open、nextTuple 和 delcareOutputFields 方法
public void open( Map conf, TopologyContext context,SpoutOutputCollector collector ) { _collector = collector; try { fileReader = new BufferedReader(new FileReader(new File(file))); } catch (FileNotFoundException e) { System.exit(1); } } public void nextTuple() { protected void ListenFile(File file) { Utils.sleep(2000); RandomAccessFile access = null; String line = null; try { while ((line = access.readLine()) != null) { if (line !=null) { String[] fields=null; if (tupleInfo.getDelimiter().equals("|")) fields = line.split("\\"+tupleInfo.getDelimiter()); else fields = line.split(tupleInfo.getDelimiter()); if (tupleInfo.getFieldList().size() == fields.length) _collector.emit(new Values(fields)); } } } catch (IOException ex) { } } } public void declareOutputFields(OutputFieldsDeclarer declarer) { String[] fieldsArr = new String [tupleInfo.getFieldList().size()]; for(int i=0; i<tupleInfo.getFieldList().size(); i++) { fieldsArr[i] = tupleInfo.getFieldList().get(i).getColumnName(); } declarer.declare(new Fields(fieldsArr)); } declareOutputFileds() 決定tuple發送的格式,這樣,Bolt就能用類似的方式編碼 tuple。Spout持續監聽添加到日志檔案的資料,一旦有資料添加,它就讀取并把資料發送給 bolt 處理。
Bolt 實作
Spout 輸出結果将給予Bolt進行更深一步的處理。經過對用例的思考,我們的topology中需要如圖 3中的兩個Bolt。
圖 3:Spout到Bolt的資料流程
ThresholdCalculatorBolt
Spout将tuple發出,由ThresholdCalculatorBolt接收并進行臨界值處理。在這裡,它将接收好幾項輸入進行檢查;分别是:
臨界值檢查
- 門檻值欄數檢查(拆分成字段的數目)
- 門檻值資料類型(拆分後字段的類型)
- 門檻值出現的頻數
- 門檻值時間段檢查
清單 4中的類,定義用來儲存這些值。
public class ThresholdInfo implements Serializable { private String action; private String rule; private Object thresholdValue; private int thresholdColNumber; private Integer timeWindow; private int frequencyOfOccurence; } 基于字段中提供的值,門檻值檢查将被在 execute() 方法執行,如清單 5 所示。代碼大部分的功能是解析和檢測到來的值。
清單 5:門檻值檢測代碼段
public void execute(Tuple tuple, BasicOutputCollector collector) { if(tuple!=null) { List<Object> inputTupleList = (List<Object>) tuple.getValues(); int thresholdColNum = thresholdInfo.getThresholdColNumber(); Object thresholdValue = thresholdInfo.getThresholdValue(); String thresholdDataType = tupleInfo.getFieldList().get(thresholdColNum-1).getColumnType(); Integer timeWindow = thresholdInfo.getTimeWindow(); int frequency = thresholdInfo.getFrequencyOfOccurence(); if(thresholdDataType.equalsIgnoreCase("string")) { String valueToCheck = inputTupleList.get(thresholdColNum-1).toString(); String frequencyChkOp = thresholdInfo.getAction(); if(timeWindow!=null) { long curTime = System.currentTimeMillis(); long diffInMinutes = (curTime-startTime)/(1000); if(diffInMinutes>=timeWindow) { if(frequencyChkOp.equals("==")) { if(valueToCheck.equalsIgnoreCase(thresholdValue.toString())) { count.incrementAndGet(); if(count.get() > frequency) splitAndEmit(inputTupleList,collector); } } else if(frequencyChkOp.equals("!=")) { if(!valueToCheck.equalsIgnoreCase(thresholdValue.toString())) { count.incrementAndGet(); if(count.get() > frequency) splitAndEmit(inputTupleList,collector); } } else System.out.println("Operator not supported"); } } else { if(frequencyChkOp.equals("==")) { if(valueToCheck.equalsIgnoreCase(thresholdValue.toString())) { count.incrementAndGet(); if(count.get() > frequency) splitAndEmit(inputTupleList,collector); } } else if(frequencyChkOp.equals("!=")) { if(!valueToCheck.equalsIgnoreCase(thresholdValue.toString())) { count.incrementAndGet(); if(count.get() > frequency) splitAndEmit(inputTupleList,collector); } } } } else if(thresholdDataType.equalsIgnoreCase("int") || thresholdDataType.equalsIgnoreCase("double") || thresholdDataType.equalsIgnoreCase("float") || thresholdDataType.equalsIgnoreCase("long") || thresholdDataType.equalsIgnoreCase("short")) { String frequencyChkOp = thresholdInfo.getAction(); if(timeWindow!=null) { long valueToCheck = Long.parseLong(inputTupleList.get(thresholdColNum-1).toString()); long curTime = System.currentTimeMillis(); long diffInMinutes = (curTime-startTime)/(1000); System.out.println("Difference in minutes="+diffInMinutes); if(diffInMinutes>=timeWindow) { if(frequencyChkOp.equals("<")) { if(valueToCheck < Double.parseDouble(thresholdValue.toString())) { count.incrementAndGet(); if(count.get() > frequency) splitAndEmit(inputTupleList,collector); } } else if(frequencyChkOp.equals(">")) { if(valueToCheck > Double.parseDouble(thresholdValue.toString())) { count.incrementAndGet(); if(count.get() > frequency) splitAndEmit(inputTupleList,collector); } } else if(frequencyChkOp.equals("==")) { if(valueToCheck == Double.parseDouble(thresholdValue.toString())) { count.incrementAndGet(); if(count.get() > frequency) splitAndEmit(inputTupleList,collector); } } else if(frequencyChkOp.equals("!=")) { . . . } } } else splitAndEmit(null,collector); } else { System.err.println("Emitting null in bolt"); splitAndEmit(null,collector); } } 根據門檻值 bolt 發送的 tuple 被發送到下一個相應的Bolt,在我們的用例中是 DBWriterBolt。
DBWriterBolt
已經處理的tuple必須被持久化,以便于觸發tigger或者将來使用。DBWiterBolt 完成的工作是将 tuple 持久化到資料庫。表的建立是由 prepare() 完成,這也是topology調用的第一個方法。該方法的代碼如清單 6 所示。
清單 6:建立表的代碼
public void prepare( Map StormConf, TopologyContext context ) { try { Class.forName(dbClass); } catch (ClassNotFoundException e) { System.out.println("Driver not found"); e.printStackTrace(); } try { connection driverManager.getConnection( "jdbc:mysql://"+databaseIP+":"+databasePort+"/"+databaseName, userName, pwd); connection.prepareStatement("DROP TABLE IF EXISTS "+tableName).execute(); StringBuilder createQuery = new StringBuilder( "CREATE TABLE IF NOT EXISTS "+tableName+"("); for(Field fields : tupleInfo.getFieldList()) { if(fields.getColumnType().equalsIgnoreCase("String")) createQuery.append(fields.getColumnName()+" VARCHAR(500),"); else createQuery.append(fields.getColumnName()+" "+fields.getColumnType()+","); } createQuery.append("thresholdTimeStamp timestamp)"); connection.prepareStatement(createQuery.toString()).execute(); // Insert Query StringBuilder insertQuery = new StringBuilder("INSERT INTO "+tableName+"("); String tempCreateQuery = new String(); for(Field fields : tupleInfo.getFieldList()) { insertQuery.append(fields.getColumnName()+","); } insertQuery.append("thresholdTimeStamp").append(") values ("); for(Field fields : tupleInfo.getFieldList()) { insertQuery.append("?,"); } insertQuery.append("?)"); prepStatement = connection.prepareStatement(insertQuery.toString()); } catch (SQLException e) { e.printStackTrace(); } } 資料的插入是分批次完成的。插入的邏輯由 execute() 方法提供,如清單 7 所示。大部分代碼是解析各種不同輸入類型。
清單 7:資料插入的代碼部分
public void execute(Tuple tuple, BasicOutputCollector collector) { batchExecuted=false; if(tuple!=null) { List<Object> inputTupleList = (List<Object>) tuple.getValues(); int dbIndex=0; for(int i=0;i<tupleInfo.getFieldList().size();i++) { Field field = tupleInfo.getFieldList().get(i); try { dbIndex = i+1; if(field.getColumnType().equalsIgnoreCase("String")) prepStatement.setString(dbIndex, inputTupleList.get(i).toString()); else if(field.getColumnType().equalsIgnoreCase("int")) prepStatement.setInt(dbIndex, Integer.parseInt(inputTupleList.get(i).toString())); else if(field.getColumnType().equalsIgnoreCase("long")) prepStatement.setLong(dbIndex, Long.parseLong(inputTupleList.get(i).toString())); else if(field.getColumnType().equalsIgnoreCase("float")) prepStatement.setFloat(dbIndex, Float.parseFloat(inputTupleList.get(i).toString())); else if(field.getColumnType().equalsIgnoreCase("double")) prepStatement.setDouble(dbIndex, Double.parseDouble(inputTupleList.get(i).toString())); else if(field.getColumnType().equalsIgnoreCase("short")) prepStatement.setShort(dbIndex, Short.parseShort(inputTupleList.get(i).toString())); else if(field.getColumnType().equalsIgnoreCase("boolean")) prepStatement.setBoolean(dbIndex, Boolean.parseBoolean(inputTupleList.get(i).toString())); else if(field.getColumnType().equalsIgnoreCase("byte")) prepStatement.setByte(dbIndex, Byte.parseByte(inputTupleList.get(i).toString())); else if(field.getColumnType().equalsIgnoreCase("Date")) { Date dateToAdd=null; if (!(inputTupleList.get(i) instanceof Date)) { DateFormat df = new SimpleDateFormat("yyyy-MM-dd hh:mm:ss"); try { dateToAdd = df.parse(inputTupleList.get(i).toString()); } catch (ParseException e) { System.err.println("Data type not valid"); } } else { dateToAdd = (Date)inputTupleList.get(i); java.sql.Date sqlDate = new java.sql.Date(dateToAdd.getTime()); prepStatement.setDate(dbIndex, sqlDate); } } catch (SQLException e) { e.printStackTrace(); } } Date now = new Date(); try { prepStatement.setTimestamp(dbIndex+1, new java.sql.Timestamp(now.getTime())); prepStatement.addBatch(); counter.incrementAndGet(); if (counter.get()== batchSize) executeBatch(); } catch (SQLException e1) { e1.printStackTrace(); } } else { long curTime = System.currentTimeMillis(); long diffInSeconds = (curTime-startTime)/(60*1000); if(counter.get()<batchSize && diffInSeconds>batchTimeWindowInSeconds) { try { executeBatch(); startTime = System.currentTimeMillis(); } catch (SQLException e) { e.printStackTrace(); } } } } public void executeBatch() throws SQLException { batchExecuted=true; prepStatement.executeBatch(); counter = new AtomicInteger(0); } 一旦Spout和Bolt準備就緒(等待被執行),topology生成器将會建立topology并執行。下面就來看一下執行步驟。
在本地叢集上運作和測試topology
- 通過TopologyBuilder建立topology。
- 使用Storm Submitter,将topology遞交給叢集。以topology的名字、配置和topology的對象作為參數。
- 送出topology。
清單 8:建立和執行topology
public class StormMain { public static void main(String[] args) throws AlreadyAliveException, InvalidTopologyException, InterruptedException { ParallelFileSpout parallelFileSpout = new ParallelFileSpout(); ThresholdBolt thresholdBolt = new ThresholdBolt(); DBWriterBolt dbWriterBolt = new DBWriterBolt(); TopologyBuilder builder = new TopologyBuilder(); builder.setSpout("spout", parallelFileSpout, 1); builder.setBolt("thresholdBolt", thresholdBolt,1).shuffleGrouping("spout"); builder.setBolt("dbWriterBolt",dbWriterBolt,1).shuffleGrouping("thresholdBolt"); if(this.argsMain!=null && this.argsMain.length > 0) { conf.setNumWorkers(1); StormSubmitter.submitTopology( this.argsMain[0], conf, builder.createTopology()); } else { Config conf = new Config(); conf.setDebug(true); conf.setMaxTaskParallelism(3); LocalCluster cluster = new LocalCluster(); cluster.submitTopology( "Threshold_Test", conf, builder.createTopology()); } } } 建立 topology 後,送出到本地叢集。一旦topology被送出,除非被 kill 或者因為修改而關閉叢集,否則它将一直運作。這也是Storm一大優勢之一。
本例展示建立和使用Storm,一旦你了解 topology、spout和bolt這些基本概念,将會很容易。如果你處理大資料,又不想用 Hadoop,那麼使用 Storm 是一個很好的選擇。
Storm常見問題解答
- 一、我有一個資料檔案,或者我有一個系統裡面有資料,怎麼導入storm做計算?
你需要實作一個Spout,Spout負責将資料emit到storm系統裡,交給bolts計算。怎麼實作spout可以參考官方的kestrel spout實作:
https://github.com/nathanmarz/storm-kestrel
如果你的資料源不支援事務性消費,那麼就無法得到storm提供的可靠處理的保證,也沒必要實作ISpout接口中的ack和fail方法。
- 二、Storm為了保證tuple的可靠處理,需要儲存tuple資訊,這會不會導緻記憶體OOM?
Storm為了保證tuple的可靠處理,acker會儲存該節點建立的tuple id的xor值,這稱為ack value,那麼每ack一次,就将tuple id和ack value做異或(xor)。當所有産生的tuple都被ack的時候, ack value一定為0。這是個很簡單的政策,對于每一個tuple也隻要占用約20個位元組的記憶體。對于100萬tuple,也才20M左右。關于可靠處理看這個:
https://github.com/nathanmarz/storm/wiki/Guaranteeing-message-processing
- 三、Storm計算後的結果儲存在哪裡?可以儲存在外部存儲嗎?
Storm不處理計算結果的儲存,這是應用代碼需要負責的事情,如果資料不大,你可以簡單地儲存在記憶體裡,也可以每次都更新資料庫,也可以采用NoSQL存儲。storm并沒有像s4那樣提供一個Persist API,根據時間或者容量來做存儲輸出。這部分事情完全交給使用者。
資料存儲之後的展現,也是你需要自己處理的,storm UI隻提供對topology的監控和統計。
- 四、Storm怎麼處理重複的tuple?
因為Storm要保證tuple的可靠處理,當tuple處理失敗或者逾時的時候,spout會fail并重新發送該tuple,那麼就會有tuple重複計算的問題。這個問題是很難解決的,storm也沒有提供機制幫助你解決。一些可行的政策:
(1)不處理,這也算是種政策。因為實時計算通常并不要求很高的精确度,後續的批處理計算會更正實時計算的誤差。
(2)使用第三方集中存儲來過濾,比如利用mysql,memcached或者redis根據邏輯主鍵來去重。
(3)使用bloom filter做過濾,簡單高效。
- 五、Storm的動态增删節點
我在storm和s4裡比較裡談到的動态增删節點,是指storm可以動态地添加和減少supervisor節點。對于減少節點來說,被移除的supervisor上的worker會被nimbus重新負載均衡到其他supervisor節點上。在storm 0.6.1以前的版本,增加supervisor節點不會影響現有的topology,也就是現有的topology不會重新負載均衡到新的節點上,在擴充叢集的時候很不友善,需要重新送出topology。是以我在storm的郵件清單裡提了這個問題,storm的開發者nathanmarz建立了一個issue 54并在0.6.1提供了rebalance指令來讓正在運作的topology重新負載均衡,具體見:
https://github.com/nathanmarz/storm/issues/54
和0.6.1的變更:
http://groups.google.com/group/storm-user/browse_thread/thread/24a8fce0b2e53246
storm并不提供機制來動态調整worker和task數目。
- 六、Storm UI裡spout統計的complete latency的具體含義是什麼?為什麼emit的數目會是acked的兩倍?
這個事實上是storm郵件清單裡的一個問題。Storm作者marz的解答:
The complete latency is the time from the spout emitting a tuple to that tuple being acked on the spout. So it tracks the time for the whole tuple tree to be processed.
If you dive into the spout component in the UI, you'll see that a lot of the emitted/transferred is on the __ack* stream. This is the spout communicating with the ackers which take care of tracking the tuple trees.
簡單地說,complete latency表示了tuple從emit到被acked經過的時間,可以認為是tuple以及該tuple的後續子孫(形成一棵樹)整個處理時間。其次spout的emit和transfered還統計了spout和acker之間内部的通信資訊,比如對于可靠處理的spout來說,會在emit的時候同時發送一個_ack_init給acker,記錄tuple id到task id的映射,以便ack的時候能找到正确的acker task。
其他開源的大資料解決方案
自 Google 在 2004 年推出 MapReduce 範式以來,已誕生了多個使用原始 MapReduce 範式(或擁有該範式的品質)的解決方案。Google 對 MapReduce 的最初應用是建立網際網路的索引。盡管此應用程式仍然很流行,但這個簡單模型解決的問題也正在增多。
表 1 提供了一個可用開源大資料解決方案的清單,包括傳統的批處理和流式處理應用程式。在将 Storm 引入開源之前将近一年的時間裡,Yahoo! 的 S4 分布式流計算平台已向 Apache 開源。S4 于 2010 年 10 月釋出,它提供了一個高性能計算 (HPC) 平台,向應用程式開發人員隐藏了并行處理的複雜性。S4 實作了一個可擴充的、分散化的叢集架構,并納入了部分容錯功能。
表 1. 開源大資料解決方案
| 解決方案 | 開發商 | 類型 | 描述 |
| 流式處理 | Twitter 的新流式大資料分析解決方案 | ||
| S4 | Yahoo! | 來自 Yahoo! 的分布式流計算平台 | |
| Apache | 批處理 | MapReduce 範式的第一個開源實作 | |
| Spark | UC Berkeley AMPLab | 支援記憶體中資料集和恢複能力的最新分析平台 | |
| Disco | Nokia | Nokia 的分布式 MapReduce 架構 | |
| HPCC | LexisNexis | HPC 大資料叢集 |
參考資料
- Apache Storm 的曆史及經驗教訓——Nathan Marz【翻譯】
- Apache Storm 與 Spark:對實時處理資料,如何選擇【翻譯】