Kademlia、DHT、KRPC、BitTorrent 協定、DHT Sniffer
catalogue
0. 引言
1. Kademlia協定
2. KRPC 協定 KRPC Protocol
3. DHT 公網嗅探器實作(DHT 爬蟲)
4. BitTorrent協定
5. uTP協定
6. Peer Wire協定
7. BitTorrent協定擴充與ut_metadata和ut_pex(Extension for Peers to Send Metadata Files)
8. 用P2P對等網絡思想改造C/S、B/S架構的思考 0. 引言
平常我們高端使用者都會用到BT工具來分享一些好玩的資源,例如ubuntu 13.04的ISO安裝盤,一些好聽的音樂等。這個時候我們會進入一個叫做P2P的網絡,大家都在這個網絡裡互相傳遞資料,這種分布式的資料傳輸解決了HTTP、FTP等單一伺服器的帶寬壓力。以往的BT工具(包括現在也有)在加入這個P2P網絡的時候都需要借助一個叫Tracker的中心伺服器,這個伺服器是用來登記有哪些使用者在請求哪些資源,然後讓請求同一個資源的使用者都集中在一起互相分享資料,形成的一個叢集叫做Swarm。
這種工作方式有一個弊端就是一旦Tracker伺服器出現故障或者線路遭到屏蔽,BT工具就無法正常工作了。是以聰明的人類後來發明了一種叫做DHT(Distributed Hash Table)的去中心化網絡。每個加入這個DHT網絡的人都要負責存儲這個網絡裡的資源資訊和其他成員的聯系資訊,相當于所有人一起構成了一個龐大的分布式存儲資料庫。在DHT裡定位一個使用者和定位一個資源的方法是一樣的,他們都使用SHA-1産生的哈希值來作辨別
0x1: Kademlia/DHT/KRPC/BitTorrent之間的關系
Kademlia是一個最初提出的架構和理論基礎,P2P對等資源共享的思想從這裡開始衍生,DHT和KRPC是在Kademlia的基礎上進行了包裝和發展,BitTorrent是在這三者之上的檔案共享分發協定
0x2: Magnet URI格式
magnet:?xt=urn:btih:<info-hash>&dn=<name>&tr=<tracker-url>
1. <info-hash>: Infohash的16進制編碼,共40字元。為了與其它的編碼相容,用戶端應當也支援32字元的infohash base32編碼
2. Xt是唯一強制的參數
3. dn是在等待metadata時可能供用戶端顯示的名字
4. 如果隻有一個字段,Tr是tracker的url,如果有很多的tracker,那麼多個tr字段會被包含進去
# dn和tr都是可選的 如果沒有指定tracker,用戶端應使用DHT來擷取peers
0x3:P2P的含義
從第一個P2P應用系統Napster的出現開始,P2P技術掀起的風暴為網際網路帶來了一場空前的變革。P2P不是一個全新的概念,P2P理念的起源可以追溯到20世紀80年代。目前,在學術界、工業界對于P2P沒有一個統一的定義。Peer在英語裡有“(地位、能力等)同等者”、“同僚”和“夥伴”等意義,這樣一來,P2P也就可以了解為“夥伴對夥伴”的意思,或稱為對等網
嚴格地定義純粹的P2P網絡,它是指完全分布的系統,每一個節點都是在功能上和任務上完全相同的。但是這樣的定義就會排除掉一些使用“超級節點”的系統或者一些使用中央伺服器做一些非核心任務的系統。廣義的定義裡面指出P2P是一種能善于利用網際網路上的存儲、CPU周期、内容和使用者活動等各種資源的一類應用程式[3],包括了一些依賴中央伺服器才能工作的系統
P2P這個定義并不是從系統的結構或者内部的操作特征出發考慮的,而是從人們外在的感覺角度出發,如果一個系統從直覺上看是各個計算機之間直接互相聯系的就可以被叫做P2P。目前,技術上比較權威的定義為,P2P系統是一個由直接相連的節點們所構成的分布式的系統[4],這些節點能夠為了共享内容、CPU 時間、存儲或者帶寬等資源而自我形成一定的網絡拓撲結構,能夠在适應節點數目的變化和失效的同時維持可以接受的連結能力和性能,并且不需要一個全局伺服器或者權威的中介的支援。本文從人們感覺的角度出發,采用P2P的廣義定義
Relevant Link:
http://blog.csdn.net/xxxxxx91116/article/details/8549454 1. Kademlia協定
0x1: Kademlia
Kademlia是一種通過分散式雜湊表實作的協定算法,它是由Petar和David為非集中式P2P計算機網絡而設計的
1. Kademlia規定了網絡的結構,也規定了通過節點查詢進行資訊交換的方式
2. Kademlia網絡節點之間使用UDP進行通訊
3. 參與通訊的所有節點形成一張虛拟網(或者叫做覆寫網)。這些節點通過一組數字(或稱為節點ID)來進行身份辨別
4. 節點ID不僅可以用來做身份辨別,還可以用來進行值定位(值通常是檔案的散列或者關鍵詞)
5. 其實,節點ID與檔案散列直接對應,它所表示的那個節點存儲着哪兒能夠擷取檔案和資源的相關資訊
6. 當我們在網絡中搜尋某些值(即通常搜尋存儲檔案散列或關鍵詞的節點)的時候,Kademlia算法需要知道與這些值相關的鍵,然後分步在網絡中開始搜尋。每一步都會找到一些節點,這些節點的ID與鍵更為接近,如果有節點直接傳回搜尋的值或者再也無法找到與鍵更為接近的節點ID的時候搜尋便會停止。這種搜尋值的方法是非常高效的
7. 與其他的分散式雜湊表的實作類似,在一個包含n個節點的系統的值的搜尋中,Kademlia僅通路O(log(n))個節點。非集中式網絡結構還有更大的優勢,那就是它能夠顯著增強抵禦拒絕服務攻擊的能力。即使網絡中的一整批節點遭受泛洪攻擊,也不會對網絡的可用性造成很大的影響,通過繞過這些漏洞(被攻擊的節點)來重新編織一張網絡,網絡的可用性就可以得到恢複 0x2: p2p網絡架構演進
1. 第一代P2P檔案分享網絡,像Napster,依賴于中央資料庫來協調網絡中的查詢
2. 第二代P2P網絡,像Gnutella,使用泛濫式查詢(query flooding)來查詢檔案,它會搜尋網絡中的所有節點
3. 第三代p2p網絡使用分散式雜湊表來查詢網絡中的檔案,分散式雜湊表在整個網絡中儲存資源的位置 這些協定追求的主要目标就是快速定位期望的節點。Kademlia基于兩個節點之間的距離計算,該距離是"兩個網絡節點ID号的異或",計算的結果最終作為整型數值傳回。關鍵字和節點ID有同樣的格式和長度,是以,可以使用同樣的方法計算關鍵字和節點ID之間的距離。節點ID一般是一個大的随機數,選擇該數的時候所追求的一個目标就是它的唯一性(希望在整個網絡中該節點ID是唯一的)。異或距離跟實際上的地理位置沒有任何關系,隻與ID相關。是以很可能來自德國和澳洲的節點由于選擇了相似的随機ID而成為鄰居。選擇異或是因為通過它計算的距離享有幾何距離公式的一些特征,尤其展現在以下幾點
1. 節點和它本身之間的異或距離是0
2. 異或距離是對稱的:即從A到B的異或距離與從B到A的異或距離是等同的
3. 異或距離符合三角不等式: 三個頂點A B C,AC異或距離小于或等于AB異或距離和BC異或距離之和,這種幾何數學特征,可以很好的支撐算法進行尋路路由 由于以上的這些屬性,在實際的節點距離的度量過程中計算量将大大降低。Kademlia搜尋的每一次疊代将距目标至少更近1 bit(每次根據XOR結果,往前選擇1bit更近的節點)。一個基本的具有2的n次方個節點的Kademlia網絡在最壞的情況下隻需花n步就可找到被搜尋的節點或值
因為Kademlia是根據bit位XOR計算得到"相對距離"的,對于越低bit位,XOR可能得到的結果越小,對于越高位的bit位,XOR可能得到的值就越大,并且是呈現2的指數方式增長的,是以,從數學上來說,一個DHT網絡中的所有節點,通過這種方式(XOR距離)進行尋址,每次前進一個bit,最大隻需要log2N次即可到達目标節點(log2逼近的思路,即bit 2可以表示世界上任何數字) 0x3: 路由表
Kademlia路由表由多個清單組成,每個清單對應節點ID的一位(例如: 假如節點ID共有6位,則節點的路由表将包含6個清單),一個清單中包含多個條目,條目中包含定位其他節點所必要的一些資料。清單條目中的這些資料通常是由其他節點的IP位址,端口和節點ID組成。這裡仔細思考一下
1. 節點ID的一位就是1bit,假設我們的節點ID是: 111000
2. 對第一個K桶來說,它的清單中的條目必須第一bit不能是1,因為第一個K桶的含義是和該節點的距離是最遠的一個分組,第一位不為1,它背後的含義是該分組裡的節點和該節點的距離至少在2^6以上,它代表了整個網絡中和該節點邏輯距離最遠的一些節點 它的清單條目是這樣的: 0 00000 ~ 0 111111
3. 對第二個K桶來說,它的清單中的條目的第一位必須是1,表示和目前節點的第一bit相同,第二bit不能是1,這樣代表的意思是第二個K桶裡的節點和該節點的距離是介于MAX(2bit)和MIN(1bit)之間的距離,它的清單條目是這樣的: 10 0000 ~ 10 1111
4. 第三個K桶的情況和前2個相同
5. 對第四個K桶的來說,它的清單中的條目前三位都是1,第四位不是0,它的清單條目是這樣的: 1111 00 ~ 1111 11
6. 後面的bit位情況類推,可以看出,越低bit位的K桶的MAX(XOR)就越小,它的可變範圍就越小了。這代表了越低bit位的K桶裡存儲的都是距離目前節點越近的Nod節點 而條目清單以節點ID的一位(即1bit)來分組是有道理的:我們使用log2N的指數分級方法把除目前節點的全網所有節點都進行了分組,當别的節點來向目前節點請求某個資源HASH的時候,将待搜尋尋址的"目标節點ID"和路由表進行異或,會有2種情況
1. 找到某個條目和目标節點XOR為0,即已經尋址成功,則直接傳回這個條目給requester即可
2. 如果沒找到XOR結果為0的條目,則選取那個XOR值最小的條目對應的K桶中的K個條目傳回給requester,因為這些條目是最有可能存儲了目标節點ID條目的 每個清單對應于與節點相距"特定範圍距離"的一些節點,節點的第n個清單中所找到的節點的第n位與該節點的第n位肯定不同,而前n-1位相同
1. 這就意味着很容易使用網絡中遠離該節點的一半節點來填充第一個清單(第一位不同的節點最多有一半)
2. 而用網絡中四分之一的節點來填充第二個清單(比第一個清單中的那些節點離該節點更近一位)
3. 依次類推。如果ID有128個二進制位,則網絡中的每個節點按照不同的異或距離把其他所有的節點分成了128類,ID的每一位對應于其中的一類 随着網絡中的節點被某節點發現,它們被逐漸加入到該節點的相應的清單中,這個過程中包括
1. 向節點清單中存資訊: 錄入别的節點釋出的聲明
2. 和從節點清單中取資訊的操作
3. 甚至還包括當時協助其他節點尋找相應鍵對應值的操作: 轉發其他節點的尋址請求 這個過程中發現的所有節點都将被加入到節點的清單之中,是以節點對整個網絡的感覺是動态的,這使得網絡一直保持着頻繁地更新,增強了抵禦錯誤和攻擊的能力
在Kademlia相關的論文中,清單也稱為K桶,其中K是一個系統變量,如20,每一個K桶是一個最多包含K個條目的清單,也就是說,網絡中所有節點的一個清單(對應于某一位,與該節點相距一個特定的距離)最多包含20個節點。随着對應的bit位變低(即對應的異或距離越來越短)(bit位越小,可能的距離MAX值就越小了,即距離目标節點的距離越近),K桶包含的可能節點數迅速下降(K定義的是該bit對應的清單最多能存儲K個條目,但不一定都是K存滿,當到最低幾個bit位的時候,K桶裡可能就隻有幾個個位數的條目了)。由于網絡中節點的實際數量遠遠小于可能ID号的數量,是以對應那些短距離的某些K桶可能一直是空的(如果異或距離隻有1,可能的數量就最大隻能為1,這個異或距離為1的節點如果沒有發現,則對應于異或距離為1的K桶則是空的)
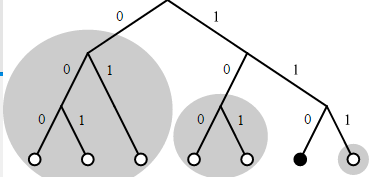
從這個邏輯圖中可以看出
1. 節點的HASH值決定了它們的邏輯距離,即Kademlia網絡中的下一跳尋址是根據HASH XOR的值範圍(數值大小範圍)結果決定的
2. 該網絡最大可有2^3,即8個關鍵字和節點,目前共有7個節點加入,每個節點用一個小圈表示(在樹的底部)
3. 考慮那個用黑圈标注的節點6,它共有3個K桶(即3bit位)
節點0,1和2(二進制表示為000,001和010)是第一個K桶的候選節點
000 -> 110: 6
001 -> 110: 5
010 -> 110: 4
節點3目前(二進制表示為011)還沒有加入網絡
節點4和節點5(二進制表示分别為100和101)是第二個K桶的候選節點
100 -> 110: 2
101 -> 110: 1
節點7(二進制表示為111)是第3個K桶的候選節點
111 -> 110: 1 圖中3個K桶都用灰色圈表示,假如K桶的大小(即K值)是2,那麼第一個K桶隻能包含3個節點中的2個。衆所周知,那些長時間線上連接配接的節點未來長時間線上的可能性更大,基于這種靜态統計分布的規律,Kademlia選擇把那些長時間線上的節點存入K桶,這一方法增長了未來某一時刻有效節點的數量(hot hint),同時也提供了更為穩定的網絡。當某個K桶已滿,而又發現了相應于該桶的新節點的時候,那麼,就首先檢查K桶中最早通路的節點,假如該節點仍然存活,那麼新節點就被安排到一個附屬清單中(作為一個替代緩存). 隻有當K桶中的某個節點停止響應的時候,替代cache才被使用。換句話說,新發現的節點隻有在老的節點消失(失效)後才被使用
0x4: 協定消息
Kademlia協定共有四種消息
1. PING消息: 用來測試節點是否仍然線上
2. STORE消息: 在某個節點中存儲一個鍵值對
3. FIND_NODE消息: 消息請求的接收者将傳回自己桶中離請求鍵值最近的K個節點: 将請求者請求的節點HASH和自己的HASH進行XOR計算,将計算結果
4. FIND_VALUE消息: 與FIND_NODE一樣,不過當請求的接收者存有請求者所請求的鍵的時候,它将傳回相應鍵的值 每一個RPC消息中都包含一個發起者加入的随機值,這一點確定響應消息在收到的時候能夠與前面發送的請求消息比對
0x5: 定位節點
節點查詢可以異步進行,也可以同時進行,同時查詢的數量由α表示,一般是3
1. 在節點查詢的時候,它先得到它K桶中離所查詢的鍵值最近的K個節點(XOR值最小的那個條目所在的分組),然後向這K個節點發起FIND_NODE消息請求(因為這個K桶内的節點最有可能尋址成功)
2. 消息接收者收到這些請求消息後将在他們的K桶中進行查詢,如果他們知道離被查鍵更近的節點,他們就傳回這些節點(最多K個)
1) 找到某個條目和目标節點XOR為0,即已經尋址成功,則直接傳回這個條目給requester即可
2) 如果沒找到XOR結果為0的條目,則選取那個XOR值最小的條目對應的K桶中的K個條目傳回給requester,因為這些條目是最有可能存儲了目标節點ID條目的
3. 消息的請求者在收到響應後将使用它所收到的響應結果來更新它的結果清單,傳回的結果也應該插入到剛才發起請求的那個K桶裡,這個結果清單總是保持K個響應FIND_NODE消息請求的最優節點(即離被搜尋鍵更近的K個節點)
4. 然後消息發起者将向這K個最優節點發起查詢,因為剛開始的查詢很可能K桶裡存的不全是目标節點,而是潛在地離目标節點較近的節點
5. 不斷地疊代執行上述查詢過程。因為每一個節點比其他節點對它周邊的節點有更好的感覺能力(水波擴散式的節點尋址方式),是以響應結果将是一次一次離被搜尋鍵值越來越近的某節點。如果本次響應結果中的節點沒有比前次響應結果中的節點離被搜尋鍵值更近了(即發現這輪查詢的結果未發生diff變化了),這個查詢疊代也就終止了
6. 當這個疊代終止的時候,響應結果集中的K個最優節點就是整個網絡中離被搜尋鍵值最近的K個節點(從以上過程看,這顯然是局部的,而非整個網絡,因為這本質和最優解搜尋算法一樣,可能陷入局部最優解而無法獲得全局最優解)
7. 節點資訊中可以增加一個往返時間,或者叫做RTT的參數,這個參數可以被用來定義一個針對每個被查詢節點的逾時設定,即當向某個節點發起的查詢逾時的時候,另一個查詢才會發起,當然,針對某個節點的查詢在同一時刻從來不超過α個 0x6: 定位和備援拷貝資源
通過把資源資訊與鍵進行映射,資源即可進行定位,雜湊表是典型的用來映射的手段。由于以前的STORE消息,存儲節點将會有對應STORE所存儲的相關資源的資訊。定位資源時,如果一個節點存有相應的資源的值的時候,它就傳回該資源,搜尋便結束了,除了該點以外,定位資源與定位離鍵最近的節點的過程相似
1. 考慮到節點未必都線上的情況,資源的值被存在多個節點上(節點中的K個),并且,為了提供備援,還有可能在更多的節點上儲存值
2. 儲存值的節點将定期搜尋網絡中與儲存值所對應的鍵接近的K個節點并且把值複制到這些節點上,這些節點可作為那些下線的節點的補充
3. 另外,對于那些普遍流行的内容,可能有更多的請求需求,通過讓那些通路值的節點把值存儲在附近的一些節點上(不在K個最近節點的範圍之類)來減少存儲值的那些節點的負載,這種新的存儲技術就是緩存技術,通過這種技術,依賴于請求的數量,資源的值被存儲在離鍵越來越遠的那些節點上(資源熱度越高,緩存cache就越廣泛),這使得那些流行的搜尋可以更快地找到資源的儲存者
5. 由于傳回值的節點的NODE_ID遠離值所對應的關鍵字,網絡中的"熱點"區域存在的可能性也降低了。依據與鍵的距離,緩存的那些節點在一段時間以後将會删除所存儲的緩存值。DHT的某些實作(如Kad)即不提供備援(複制)節點也不提供緩存,這主要是為了能夠快速減少系統中的陳舊資訊。在這種網絡中,提供檔案的那些節點将會周期性地更新網絡上的資訊(通過NODE_LOOKUP消息和STORE消息)。當存有某個檔案的所有節點都下線了,關于該檔案的相關的值(源和關鍵字)的更新也就停止了,該檔案的相關資訊也就從網絡上完全消失了 0x7: 加入網絡
1. 想要加入網絡的節點首先要經曆一個引導過程。在引導過程中,節點需要知道其他已加入該網絡的某個節點的IP位址和端口号(可從使用者或者存儲的清單中獲得)。假如正在引導的那個節點還未加入網絡,它會計算一個目前為止還未配置設定給其他節點的随機ID号,直到離開網絡,該節點會一直使用該ID号
2. 正在加入Kademlia網絡的節點在它的某個K桶中插入引導節點(加入該網絡的介紹人)(負責加入節點的初始化工作),然後向它的唯一鄰居(引導節點)發起NODE_LOOKUP操作請求來定位自己,這種"自我定位"将使得Kademlia的其他節點(收到請求的節點)能夠使用新加入節點的Node Id填充他們的K桶(鄰居互相認識)
3. 同時也能夠使用那些查詢過程的中間節點(位于新加入節點和引導節點的查詢路徑上的其他節點)來填充新加入節點的K桶(相當于完成一個DNS遞歸查詢後,沿途路徑上的DNS IP都被記錄了)。想象一下這個過程
1) 新加入的節點可能和"引導節點"距離很遠,它一上來就向離自己幾何距離最遠的引導節點問話: "誰知道我自己這個節點在哪?",引導節點會盡力去回答這個問題,即引導節點會把自己K桶内最有可能知道該節點位置(即離該幾點XOR幾何距離最近的K個點傳回給新加入的請求節點)
2) 新加入的請求方收到了K個節點後,把這K個節點儲存進自己的K桶,然後繼續向這些節點去"詢問(發起find_node請求)"自己的節點在哪,這些節點會收到這些請求,同時也把新加入節點儲存進自己的K桶内
3) 整個過程和向DNS根域名伺服器請求解析某個域名的遞歸過程類似
4. 這一自查詢過程使得新加入節點自引導節點所在的那個K桶開始,由遠及近,對沿途的所有節點逐漸得到重新整理,整條鍊路上的鄰居都認識了這個新鄰居
5. 最初的時候,節點僅有一個K桶(覆寫所有的ID範圍),當有新節點需要插入該K桶時,如果K桶已滿,K桶就開始分裂,分裂發生在節點的K桶的覆寫範圍(表現為二叉樹某部分從左至右的所有值)包含了該節點本身的ID的時候。對于節點内距離節點最近的那個K桶,Kademlia可以放松限制(即可以到達K時不發生分裂),因為桶内的所有節點離該節點距離最近,這些節點個數很可能超過K個,而且節點希望知道所有的這些最近的節點。是以,在路由樹中,該節點附近很可能出現高度不平衡的二叉子樹。假如K是20,新加入網絡的節點ID為"xxx000011001",則字首為"xxx0011..."的節點可能有21個,甚至更多,新的節點可能包含多個含有21個以上節點的K桶(位于節點附近的k桶)。這點保證使得該節點能夠感覺網絡中附近區域的所有節點 0x8: 查詢加速
1. Kademlia使用異或來定義距離。兩個節點ID的異或(或者節點ID和關鍵字的異或)的結果就是兩者之間的距離。對于每一個二進制位來說,如果相同,異或傳回0,否則,異或傳回1。異或距離滿足三角形不等式: 任何一邊的距離小于(或等于)其它兩邊距離之和
2. 異或距離使得Kademlia的路由表可以建在單個bit之上,即可使用位組(多個位聯合)來建構路由表。位組可以用來表示相應的K桶,它有個專業術語叫做字首,對一個m位的字首來說,可對應2^m-1個K桶(m位的字首本來可以對應2^m個K桶)另外的那個K桶可以進一步擴充為包含該節點本身ID的路由樹
3. 一個b位的字首可以把查詢的最大次數從logn減少到logn/b。這隻是查詢次數的最大值,因為自己K桶可能比字首有更多的位與目标鍵相同,這會增加在自己K桶中找到節點的機會,假設字首有m位,很可能查詢一個節點就能比對2m甚至更多的位組,是以其實平均的查詢次數要少的多
4. 節點可以在他們的路由表中使用混合字首,就像eMule中的Kad網絡。如果以增加查詢的複雜性為代價,Kademlia網絡在路由表的具體實作上甚至可以是有異構的 0x9: 在檔案分享網絡中的應用
Kademlia可在檔案分享網絡中使用,通過制作Kademlia關鍵字搜尋,我們能夠在檔案分享網絡中找到我們需要的檔案以供我們下載下傳。由于沒有中央伺服器存儲檔案的索引,這部分工作就被平均地配置設定到所有的用戶端中去
1. 假如一個節點希望分享某個檔案,它先根據檔案的内容來處理該檔案,通過運算,把檔案的内容散列成一組數字,該數字在檔案分享網絡中可被用來辨別檔案
2. 這組散列數字必須和節點ID有同樣的長度,然後,該節點便在網絡中搜尋ID值與檔案的散列值相近的節點,然後向這些被搜尋到的節點廣播自己(即把它自己的IP位址存儲在那些搜尋到的節點上),本質意思是說: "你如果要搜尋這個檔案,就去找那些節點ID就好了,那些節點ID會告訴搜尋者應該到自己這裡來(檔案釋出者)來建立TCP連接配接,下載下傳檔案",也就是說,它把自己作為檔案的源進行了釋出(檔案共享方式)。正在進行檔案搜尋的用戶端将使用Kademlia協定來尋找網絡上ID值與希望尋找的檔案的散列值最近的那個節點(尋找檔案的過程和尋找節點的機制形成了統一,因為檔案和節點的ID的HASH格式是一樣的),然後取得存儲在那個節點上的檔案源清單
3. 由于一個鍵(HASH)可以對應很多值,即同一個檔案(通過一個對應的HASH公布到P2P網絡中)可以有多個源(因為可能有多個節點都會有這個檔案的拷貝),每一個存儲源清單的節點可能有不同的檔案的源的資訊,這樣的話,源清單可以從與鍵值相近的K個節點獲得。 檔案的散列值通常可以從其他的一些特别的Internet連結的地方獲得,或者被包含在從其他某處獲得的索引檔案中(即種子檔案)
4. 檔案名的搜尋可以使用關鍵詞來實作,檔案名可以分割成連續的幾個關鍵詞,這些關鍵詞都可以散列并且可以和相應的檔案名和檔案散列儲存在網絡中。搜尋者可以使用其中的某個關鍵詞,聯系ID值與關鍵詞散列最近的那個節點,取得包含該關鍵詞的檔案清單。由于在檔案清單中的檔案都有相關的散列值,通過該散列值就可利用上述通常取檔案的方法獲得要搜尋的檔案 https://zh.wikipedia.org/wiki/Kademlia
http://file.scirp.org/pdf/3-4.3.pdf 2. KRPC 協定 KRPC Protocol
KRPC是BitTorrent在Kademlia理論基礎之上定義的一個通信消息格式協定,主要用來支援peer節點的擷取(get_peer)和peer節點的聲明(announce_peer),以及判活心跳(ping)、節點尋址(find_node),它在find_node的原理上和DHT是一樣的,同時增加了get_peer/announce_peer/ping協定的支援
KRPC協定是由B編碼組成的一個簡單的RPC結構,有4種請求:ping、find_node、get_peers 和 announce_peer
0x0: bencode編碼
bencode 有 4 種資料類型: string, integer, list 和 dictionary
1. string: 字元是以這種方式編碼的: <字元串長度>:<字元串>
如 hell: 4:hell
2. integer: 整數是一這種方式編碼的: i<整數>e
如 1999: i1999e
3. list: 清單是一這種方式編碼的: l[資料1][資料2][資料3][…]e
如清單 [hello, world, 101]:l5:hello5:worldi101ee
4. dictionary: 字典是一這種方式編碼的: d[key1][value1][key2][value2][…]e,其中 key 必須是 string 而且按照字母順序排序
如字典 {aa:100, bb:bb, cc:200}: d2:aai100e2:bb2:bb2:cci200ee KRPC 協定是由 bencode 編碼組成的一個簡單的 RPC 結構,他使用 UDP 封包發送。一個獨立的請求包被發出去然後一個獨立的包被回複。這個協定沒有重發(UDP是無連接配接協定)
0x1: KRPC字典基本組成元素
一條 KRPC 消息即可能是request,也可能是response,由一個獨立的字典組成
1. t關鍵字: 每條消息都包含 t 關鍵字,它是一個代表了 transaction ID 的字元串。transaction ID 由請求節點産生,并且回複中要包含回顯該字段(挑戰-響應模型),是以回複可能對應一個節點的多個請求。transaction ID 應當被編碼為一個短的二進制字元串,比如 2 個位元組,這樣就可以對應 2^16 個請求
2. y關鍵字: 它由一個位元組組成,表明這個消息的類型。y 對應的值有三種情況
1) q 表示請求(請求Queries): q類型的消息它包含 2 個附加的關鍵字 q 和 a
1.1) 關鍵字 q: 是字元串類型,包含了請求的方法名字(get_peers/announce_peer/ping/find_node)
1.2) 關鍵字 a: 一個字典類型包含了請求所附加的參數(info_hash/id..)
2) r 表示回複(回複 Responses): 包含了傳回的值。發送回複消息是在正确解析了請求消息的基礎上完成的,包含了一個附加的關鍵字 r。關鍵字 r 是字典類型
2.1) id: peer節點id号或者下一跳DHT節點
2.2) nodes": ""
2.3) token: token
3) e 表示錯誤(錯誤 Errors): 包含一個附加的關鍵字 e,關鍵字 e 是清單類型
3.1) 第一個元素是數字類型,表明了錯誤碼,當一個請求不能解析或出錯時,錯誤包将被發送。下表描述了可能出現的錯誤碼
201: 一般錯誤
202: 服務錯誤
203: 協定錯誤,比如不規範的包,無效的參數,或者錯誤的 toke
204: 未知方法
3.2) 第二個元素是字元串類型,表明了錯誤資訊 以上是整個KRPC的協定架構結構,具體到請求Query/回複Response/錯誤Error還有具體的協定實作
0x2: 請求Query具體協定
所有的請求都包含一個關鍵字 id,它包含了請求節點的節點 ID。所有的回複也包含關鍵字id,它包含了回複節點的節點 ID
1. ping: 檢測節點是否可達,請求包含一個參數id,代表該節點的nodeID。對應的回複也應該包含回複者的nodeID
ping Query = {"t":"aa", "y":"q", "q":"ping", "a":{"id":"abcdefghij0123456789"}}
bencoded = d1:ad2:id20:abcdefghij0123456789e1:q4:ping1:t2:aa1:y1:qe
Response = {"t":"aa", "y":"r", "r": {"id":"mnopqrstuvwxyz123456"}}
bencoded = d1:rd2:id20:mnopqrstuvwxyz123456e1:t2:aa1:y1:re 2. find_node: find_node 被用來查找給定 ID 的DHT節點的聯系資訊,該請求包含兩個參數id(代表該節點的nodeID)和target。回複中應該包含被請求節點的路由表中距離target最接近的K個nodeID以及對應的nodeINFO
find_node Query = {"t":"aa", "y":"q", "q":"find_node", "a": {"id":"abcdefghij0123456789", "target":"mnopqrstuvwxyz123456"}}
# "id" containing the node ID of the querying node, and "target" containing the ID of the node sought by the queryer.
bencoded = d1:ad2:id20:abcdefghij01234567896:target20:mnopqrstuvwxyz123456e1:q9:find_node1:t2:aa1:y1:qe
Response = {"t":"aa", "y":"r", "r": {"id":"0123456789abcdefghij", "nodes": "def456..."}}
bencoded = d1:rd2:id20:0123456789abcdefghij5:nodes9:def456...e1:t2:aa1:y1:re find_node 請求包含 2 個參數,第一個參數是 id,包含了請求節點的ID。第二個參數是 target,包含了請求者正在查找的節點的 ID

當一個節點接收到了 find_node 的請求,他應該給出對應的回複,回複中包含 2 個關鍵字 id(被請求節點的id) 和 nodes,nodes 是字元串類型,包含了被請求節點的路由表中最接近目标節點的 K(8) 個最接近的節點的聯系資訊(被請求方每次都統一傳回最靠近目标節點的節點清單K捅)
參數: {"id" : "<querying nodes id>", "target" : "<id of target node>"}
回複: {"id" : "<queried nodes id>", "nodes" : "<compact node info>"} 這裡要明确3個概念
1. 請求方的id: 發起這個DHT節點尋址的節點自身的ID,可以類比DNS查詢中的用戶端
2. 目标target id: 需要查詢的目标ID号,可以類比于DNS查詢中的URL,這個ID在整個遞歸查詢中是一直不變的
3. 被請求節點的id: 在節點的遞歸查詢中,請求方由遠及近不斷詢問整個鍊路上的節點,沿途的每個節點在傳回時都要帶上自己的id号 3. get_peers
1. get_peers 請求包含 2 個參數(id請求節點ID,info_hash代表torrent檔案的infohash,infohash為種子檔案的SHA1哈希值,也就是磁力連結的btih值)
2. response get_peer:
1) 如果被請求的節點有對應 info_hash 的 peers,他将傳回一個關鍵字 values,這是一個清單類型的字元串。每一個字元串包含了 "CompactIP-address/portinfo" 格式的 peers 資訊(即對應的機器ip/port資訊)(peer的info資訊和DHT節點的info資訊是一樣的)
2) 如果被請求的節點沒有這個 infohash 的 peers,那麼他将傳回關鍵字 nodes(需要注意的是,如果該節點沒有對應的infohash資訊,而隻是傳回了nodes,則請求方會認為該節點是一個"可疑節點",則會從自己的路由表K捅中删除該節點),這個關鍵字包含了被請求節點的路由表中離 info_hash 最近的 K 個節點(我這裡沒有該節點,去别的節點試試運氣),使用 "Compactnodeinfo" 格式回複。在這兩種情況下,關鍵字 token 都将被傳回。token 關鍵字在今後的 annouce_peer 請求中必須要攜帶。token 是一個短的二進制字元串 infohash = 1619ecc9373c3639f4ee3e261638f29b33a6cbd6,正是磁力連結magnet:?xt=urn:btih:1619ecc9373c3639f4ee3e261638f29b33a6cbd6&dn;=ubuntu-14.10-desktop-i386.iso中的btih值
get_peers Query = {"t":"aa", "y":"q", "q":"get_peers", "a": {"id":"abcdefghij0123456789", "info_hash":"mnopqrstuvwxyz123456"}}
bencoded = d1:ad2:id20:abcdefghij01234567899:info_hash20:mnopqrstuvwxyz123456e1:q9:get_peers1:t2:aa1:y1:qe
Response with peers = {"t":"aa", "y":"r", "r": {"id":"abcdefghij0123456789", "token":"aoeusnth", "values": ["axje.u", "idhtnm"]}}
bencoded = d1:rd2:id20:abcdefghij01234567895:token8:aoeusnth6:valuesl6:axje.u6:idhtnmee1:t2:aa1:y1:re
Response with closest nodes = {"t":"aa", "y":"r", "r": {"id":"abcdefghij0123456789", "token":"aoeusnth", "nodes": "def456..."}}
bencoded = d1:rd2:id20:abcdefghij01234567895:nodes9:def456...5:token8:aoeusnthe1:t2:aa1:y1:re 架構格式
參數: {"id" : "<querying nodes id>", "info_hash" : "<20-byte infohash of target torrent>"}
回複:
{"id" : "<queried nodes id>", "token" :"<opaque write token>", "values" : ["<peer 1 info string>", "<peer 2 info string>"]}
或:
{"id" : "<queried nodes id>", "token" :"<opaque write token>", "nodes" : "<compact node info>"} get_peers請求的回複。回複封包中包含了8個node,以及100個peer。可見包含該種子檔案的peer非常多
4. announce_peer: 這個請求用來表明發出 announce_peer 請求的節點,正在某個端口下載下傳 torrent 檔案
announce_peer 包含 4 個參數
1. 第一個參數是 id: 包含了請求節點的 ID
2. 第二個參數是 info_hash: 包含了 torrent 檔案的 infohash
3. 第三個參數是 port: 包含了整型的端口号,表明 peer 在哪個端口下載下傳
4. 第四個參數數是 token: 這是在之前的 get_peers 請求中收到的回複中包含的。收到 announce_peer 請求的節點必須檢查這個 token 與之前我們回複給這個節點 get_peers 的 token 是否相同(也就說,所有下載下傳者/釋出者都要參與檢測新加入的釋出者是否僞造了該資源,但是這個機制有一個問題,如果最開始的那個釋出者就僞造,則整條鍊路都是一個僞造的錯的資源infohash資訊了)
如果相同,那麼被請求的節點将記錄發送 announce_peer 節點的 IP 和請求中包含的 port 端口号在 peer 聯系資訊中對應的 infohash 下,這意味着一個一個事實: 目前這個資源有一個新的peer提供者了,下一次有其他節點希望或者這個資源的時候,會把這個新的(前一次請求下載下傳資源的節點)也當作一個peer傳回給請求者,這樣,資源的提供者就越來越多,資源共享速度就越來越快 一個peer正在下載下傳某個資源,意味着該peer有能夠通路到該資源的管道,且該peer本地是有這份資源的全部或部分拷貝的,它需要向DHT網絡廣播announce消息,告訴其他節點這個資源的下載下傳位址
arguments: {"id" : "<querying nodes id>",
"implied_port": <0 or 1>,
"info_hash" : "<20-byte infohash of target torrent>",
"port" : <port number>,
"token" : "<opaque token>"}
response: {"id" : "<queried nodes id>"} 封包包例子 Example Packets
announce_peers Query = {"t":"aa", "y":"q", "q":"announce_peer", "a": {"id":"abcdefghij0123456789", "implied_port": 1, "info_hash":"mnopqrstuvwxyz123456", "port": 6881, "token": "aoeusnth"}}
bencoded = d1:ad2:id20:abcdefghij01234567899:info_hash20:<br />
mnopqrstuvwxyz1234564:porti6881e5:token8:aoeusnthe1:q13:announce_peer1:t2:aa1:y1:qe
Response = {"t":"aa", "y":"r", "r": {"id":"mnopqrstuvwxyz123456"}}
bencoded = d1:rd2:id20:mnopqrstuvwxyz123456e1:t2:aa1:y1:re 0x3: 回複 Responses
回複 Responses的包已經在上面的Query裡說明了
0x4: 錯誤 Errors
錯誤包例子 Example Error Packets
generic error = {"t":"aa", "y":"e", "e":[201, "A Generic Error Ocurred"]}
bencoded = d1:eli201e23:A Generic Error Ocurrede1:t2:aa1:y1:ee http://www.bittorrent.org/beps/bep_0005.html
https://segmentfault.com/a/1190000002528378
https://github.com/wuzhenda/simDHT
https://wenku.baidu.com/view/9a7b447aa26925c52cc5bfc9.html
http://www.bittorrent.org/beps/bep_0005.html 3. DHT 公網嗅探器實作(DHT 爬蟲)
在開始研究BitTorrent協定之前,我們先來了解下DHT協定上存在的一個缺點導緻的一個攻擊面: 嗅探攻擊
0x1: DHT嗅探器的原理
DHT這種對等分布式網絡在帶來抗DDOS的優點的同時,也帶來了一些缺點
1. 僞造攻擊: 有些不聽話的使用者可能會在DHT網絡裡搗亂,譬如說撒謊,明明自己不是奧巴馬,卻偏說自己是奧巴馬,這樣會誤導其他人無法正常擷取想要的資源
2. 嗅探攻擊: 另外,使用者在DHT網絡裡的隐私可能會被竊聽,因為在DHT網絡裡跟其他使用者交換資源的時候,難免會暴露自己的IP位址,是以别人就會知道你有什麼資源,你在請求什麼資源了。這也是目前DHT網絡裡一直存在的一個弱點 利用第二個特點,我們可以根據DHT協定用Python寫了一段程式,加入了這個DHT網絡。在這個網絡裡,我會認識很多人,越多越好(不斷遞歸find_node),并且觀察這些人的舉動(監聽get_peer的query包),比如說A想要ubuntu的安裝盤,那麼我會把A的這個行為記下來,同時我會把ubuntu安裝盤這個資源的資訊也記下來,儲存到資料庫中,統計請求ubuntu這個資源的人有多少
0x2: 示例代碼: DHT HASH嗅探
from gevent import monkey
monkey.patch_all()
from gevent.server import DatagramServer
import gevent
import socket
from hashlib import sha1
from random import randint
from struct import unpack
from socket import inet_ntoa
from threading import Timer, Thread
from gevent import sleep
from collections import deque
from bencode import bencode, bdecode
BOOTSTRAP_NODES = (
("router.bittorrent.com", 6881),
("dht.transmissionbt.com", 6881),
("router.utorrent.com", 6881)
)
TID_LENGTH = 2
RE_JOIN_DHT_INTERVAL = 3
MONITOR_INTERVAL = 10
TOKEN_LENGTH = 2
def entropy(length):
return "".join(chr(randint(0, 255)) for _ in xrange(length))
def random_id():
h = sha1()
h.update(entropy(20))
return h.digest()
def decode_nodes(nodes):
n = []
length = len(nodes)
if (length % 26) != 0:
return n
for i in range(0, length, 26):
nid = nodes[i:i+20]
ip = inet_ntoa(nodes[i+20:i+24])
port = unpack("!H", nodes[i+24:i+26])[0]
n.append((nid, ip, port))
return n
def get_neighbor(target, nid, end=10):
return target[:end]+nid[end:]
class KNode(object):
def __init__(self, nid, ip, port):
self.nid = nid
self.ip = ip
self.port = port
class DHTServer(DatagramServer):
def __init__(self, max_node_qsize, bind_ip):
s = ':' + str(bind_ip)
self.bind_ip = bind_ip
DatagramServer.__init__(self, s)
self.process_request_actions = {
"get_peers": self.on_get_peers_request,
"announce_peer": self.on_announce_peer_request,
}
self.max_node_qsize = max_node_qsize
self.nid = random_id()
self.nodes = deque(maxlen=max_node_qsize)
def handle(self, data, address): #
try:
msg = bdecode(data)
self.on_message(msg, address)
except Exception:
pass
def monitor(self):
while True:
# print 'len: ', len(self.nodes)
sleep(MONITOR_INTERVAL)
def send_krpc(self, msg, address):
try:
self.socket.sendto(bencode(msg), address)
except Exception:
pass
def send_find_node(self, address, nid=None):
nid = get_neighbor(nid, self.nid) if nid else self.nid
tid = entropy(TID_LENGTH)
msg = {
"t": tid,
"y": "q",
"q": "find_node",
"a": {
"id": nid,
"target": random_id()
}
}
self.send_krpc(msg, address)
def join_DHT(self):
for address in BOOTSTRAP_NODES:
self.send_find_node(address)
def re_join_DHT(self):
while True:
if len(self.nodes) == 0:
self.join_DHT()
sleep(RE_JOIN_DHT_INTERVAL)
def auto_send_find_node(self):
wait = 1.0 / self.max_node_qsize / 5.0
while True:
try:
node = self.nodes.popleft()
self.send_find_node((node.ip, node.port), node.nid)
except IndexError:
pass
sleep(wait)
def process_find_node_response(self, msg, address):
# print 'find node' + str(msg)
nodes = decode_nodes(msg["r"]["nodes"])
for node in nodes:
(nid, ip, port) = node
if len(nid) != 20: continue
if ip == self.bind_ip: continue
if port < 1 or port > 65535: continue
n = KNode(nid, ip, port)
self.nodes.append(n)
def on_message(self, msg, address):
try:
if msg["y"] == "r":
if msg["r"].has_key("nodes"):
self.process_find_node_response(msg, address)
elif msg["y"] == "q":
try:
self.process_request_actions[msg["q"]](msg, address)
except KeyError:
self.play_dead(msg, address)
except KeyError:
pass
def on_get_peers_request(self, msg, address):
try:
infohash = msg["a"]["info_hash"]
tid = msg["t"]
nid = msg["a"]["id"]
token = infohash[:TOKEN_LENGTH]
info = infohash.encode("hex").upper() + '|' + address[0]
print info + "\n",
msg = {
"t": tid,
"y": "r",
"r": {
"id": get_neighbor(infohash, self.nid),
"nodes": "",
"token": token
}
}
self.send_krpc(msg, address)
except KeyError:
pass
def on_announce_peer_request(self, msg, address):
try:
# print 'announce peer'
infohash = msg["a"]["info_hash"]
token = msg["a"]["token"]
nid = msg["a"]["id"]
tid = msg["t"]
if infohash[:TOKEN_LENGTH] == token:
if msg["a"].has_key("implied_port") and msg["a"]["implied_port"] != 0:
port = address[1]
else:
port = msg["a"]["port"]
if port < 1 or port > 65535: return
info = infohash.encode("hex").upper()
print info + "\n",
except Exception as e:
print e
pass
finally:
self.ok(msg, address)
def play_dead(self, msg, address):
try:
tid = msg["t"]
msg = {
"t": tid,
"y": "e",
"e": [202, "Server Error"]
}
self.send_krpc(msg, address)
except KeyError:
print 'error'
pass
def ok(self, msg, address):
try:
tid = msg["t"]
nid = msg["a"]["id"]
msg = {
"t": tid,
"y": "r",
"r": {
"id": get_neighbor(nid, self.nid)
}
}
self.send_krpc(msg, address)
except KeyError:
pass
if __name__ == '__main__':
sniffer = DHTServer(50, 8080)
gevent.spawn(sniffer.auto_send_find_node)
gevent.spawn(sniffer.re_join_DHT)
gevent.spawn(sniffer.monitor)
print('Receiving datagrams on :6882')
sniffer.serve_forever() 0x3: 示例代碼: DHT HASH/BitTorrent infohash嗅探
在DHT的基礎 上,增加umetainfo資訊的擷取(即種子資訊的擷取)
#!/usr/bin/env python
# encoding: utf-8
# apt-get install python-dev
# pip install bencode
# pip install mysql-python
# apt-get install libmysqlclient-dev
import math
import socket
import threading
from time import sleep, time
from hashlib import sha1
from random import randint
from struct import pack, unpack
from socket import inet_ntoa
from threading import Timer, Thread
from time import sleep
from collections import deque
from bencode import bencode, bdecode
from Queue import Queue
import base64
import json
import urllib2
import traceback
import gc
BOOTSTRAP_NODES = (
("router.bittorrent.com", 6881),
("dht.transmissionbt.com", 6881),
("router.utorrent.com", 6881)
)
TID_LENGTH = 2
RE_JOIN_DHT_INTERVAL = 3
TOKEN_LENGTH = 2
BT_PROTOCOL = "BitTorrent protocol"
BT_MSG_ID = 20
EXT_HANDSHAKE_ID = 0
def entropy(length):
return "".join(chr(randint(0, 255)) for _ in xrange(length))
def random_id():
h = sha1()
h.update(entropy(20))
return h.digest()
def decode_nodes(nodes):
n = []
length = len(nodes)
if (length % 26) != 0:
return n
for i in range(0, length, 26):
nid = nodes[i:i + 20]
ip = inet_ntoa(nodes[i + 20:i + 24])
port = unpack("!H", nodes[i + 24:i + 26])[0]
n.append((nid, ip, port))
return n
def timer(t, f):
Timer(t, f).start()
def get_neighbor(target, nid, end=10):
return target[:end] + nid[end:]
def send_packet(the_socket, msg):
the_socket.send(msg)
def send_message(the_socket, msg):
msg_len = pack(">I", len(msg))
send_packet(the_socket, msg_len + msg)
def send_handshake(the_socket, infohash):
bt_header = chr(len(BT_PROTOCOL)) + BT_PROTOCOL
ext_bytes = "\x00\x00\x00\x00\x00\x10\x00\x00"
peer_id = random_id()
packet = bt_header + ext_bytes + infohash + peer_id
send_packet(the_socket, packet)
def check_handshake(packet, self_infohash):
try:
bt_header_len, packet = ord(packet[:1]), packet[1:]
if bt_header_len != len(BT_PROTOCOL):
return False
except TypeError:
return False
bt_header, packet = packet[:bt_header_len], packet[bt_header_len:]
if bt_header != BT_PROTOCOL:
return False
packet = packet[8:]
infohash = packet[:20]
if infohash != self_infohash:
return False
return True
def send_ext_handshake(the_socket):
msg = chr(BT_MSG_ID) + chr(EXT_HANDSHAKE_ID) + bencode({"m": {"ut_metadata": 1}})
send_message(the_socket, msg)
def request_metadata(the_socket, ut_metadata, piece):
"""bep_0009"""
msg = chr(BT_MSG_ID) + chr(ut_metadata) + bencode({"msg_type": 0, "piece": piece})
send_message(the_socket, msg)
def get_ut_metadata(data):
try:
ut_metadata = "_metadata"
index = data.index(ut_metadata) + len(ut_metadata) + 1
return int(data[index])
except Exception as e:
pass
def get_metadata_size(data):
metadata_size = "metadata_size"
start = data.index(metadata_size) + len(metadata_size) + 1
data = data[start:]
return int(data[:data.index("e")])
def recvall(the_socket, timeout=15):
the_socket.setblocking(0)
total_data = []
data = ""
begin = time()
while True:
sleep(0.05)
if total_data and time() - begin > timeout:
break
elif time() - begin > timeout * 2:
break
try:
data = the_socket.recv(1024)
if data:
total_data.append(data)
begin = time()
except Exception:
pass
return "".join(total_data)
def ip_black_list(ipaddress):
black_lists = ['45.32.5.150', '45.63.4.233']
if ipaddress in black_lists:
return True
return False
def download_metadata(address, infohash, timeout=15):
if ip_black_list(address[0]):
return
try:
the_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
the_socket.settimeout(15)
the_socket.connect(address)
# handshake
send_handshake(the_socket, infohash)
packet = the_socket.recv(4096)
# handshake error
if not check_handshake(packet, infohash):
try:
the_socket.close()
except:
return
return
# ext handshake
send_ext_handshake(the_socket)
packet = the_socket.recv(4096)
# get ut_metadata and metadata_size
ut_metadata, metadata_size = get_ut_metadata(packet), get_metadata_size(packet)
# print 'ut_metadata_size: ', metadata_size
# request each piece of metadata
metadata = []
for piece in range(int(math.ceil(metadata_size / (16.0 * 1024)))):
request_metadata(the_socket, ut_metadata, piece)
packet = recvall(the_socket, timeout) # the_socket.recv(1024*17) #
metadata.append(packet[packet.index("ee") + 2:])
metadata = "".join(metadata)
info = {}
meta_data = bdecode(metadata)
del metadata
info['hash_id'] = infohash.encode("hex").upper()
if meta_data.has_key('name'):
info["hash_name"] = meta_data["name"].strip()
else:
info["hash_name"] = ''
if meta_data.has_key('length'):
info['hash_size'] = meta_data['length']
else:
info['hash_size'] = 0
if meta_data.has_key('files'):
info['files'] = meta_data['files']
for item in info['files']:
# print item
if item.has_key('length'):
info['hash_size'] += item['length']
info['files'] = json.dumps(info['files'], ensure_ascii=False)
info['files'] = info['files'].replace("\"path\"", "\"p\"").replace("\"length\"", "\"l\"")
else:
info['files'] = ''
info['a_ip'] = address[0]
info['hash_size'] = str(info['hash_size'])
print info, "\r\n\r\n"
del info
gc.collect()
except socket.timeout:
try:
the_socket.close()
except:
return
except socket.error:
try:
the_socket.close()
except:
return
except Exception, e:
try:
# print e
# traceback.print_exc()
the_socket.close()
except:
return
finally:
the_socket.close()
return
class KNode(object):
def __init__(self, nid, ip, port):
self.nid = nid
self.ip = ip
self.port = port
class DHTClient(Thread):
def __init__(self, max_node_qsize):
Thread.__init__(self)
self.setDaemon(True)
self.max_node_qsize = max_node_qsize
self.nid = random_id()
self.nodes = deque(maxlen=max_node_qsize)
def send_krpc(self, msg, address):
try:
self.ufd.sendto(bencode(msg), address)
except Exception:
pass
def send_find_node(self, address, nid=None):
nid = get_neighbor(nid, self.nid) if nid else self.nid
tid = entropy(TID_LENGTH)
msg = {
"t": tid,
"y": "q",
"q": "find_node",
"a": {
"id": nid,
"target": random_id()
}
}
self.send_krpc(msg, address)
def join_DHT(self):
for address in BOOTSTRAP_NODES:
self.send_find_node(address)
def re_join_DHT(self):
if len(self.nodes) == 0:
self.join_DHT()
timer(RE_JOIN_DHT_INTERVAL, self.re_join_DHT)
def auto_send_find_node(self):
wait = 1.0 / self.max_node_qsize
while True:
try:
node = self.nodes.popleft()
self.send_find_node((node.ip, node.port), node.nid)
except IndexError:
pass
sleep(wait)
def process_find_node_response(self, msg, address):
nodes = decode_nodes(msg["r"]["nodes"])
for node in nodes:
(nid, ip, port) = node
if len(nid) != 20: continue
if ip == self.bind_ip: continue
n = KNode(nid, ip, port)
self.nodes.append(n)
class DHTServer(DHTClient):
def __init__(self, master, bind_ip, bind_port, max_node_qsize):
DHTClient.__init__(self, max_node_qsize)
self.master = master
self.bind_ip = bind_ip
self.bind_port = bind_port
self.process_request_actions = {
"get_peers": self.on_get_peers_request,
"announce_peer": self.on_announce_peer_request,
}
self.ufd = socket.socket(socket.AF_INET, socket.SOCK_DGRAM, socket.IPPROTO_UDP)
self.ufd.bind((self.bind_ip, self.bind_port))
timer(RE_JOIN_DHT_INTERVAL, self.re_join_DHT)
def run(self):
self.re_join_DHT()
while True:
try:
(data, address) = self.ufd.recvfrom(65536)
msg = bdecode(data)
self.on_message(msg, address)
except Exception:
pass
def on_message(self, msg, address):
try:
if msg["y"] == "r":
if msg["r"].has_key("nodes"):
self.process_find_node_response(msg, address)
elif msg["y"] == "q":
try:
self.process_request_actions[msg["q"]](msg, address)
except KeyError:
self.play_dead(msg, address)
except KeyError:
pass
def on_get_peers_request(self, msg, address):
try:
infohash = msg["a"]["info_hash"]
tid = msg["t"]
nid = msg["a"]["id"]
token = infohash[:TOKEN_LENGTH]
msg = {
"t": tid,
"y": "r",
"r": {
"id": get_neighbor(infohash, self.nid),
"nodes": "",
"token": token
}
}
self.send_krpc(msg, address)
except KeyError:
pass
def on_announce_peer_request(self, msg, address):
try:
infohash = msg["a"]["info_hash"]
token = msg["a"]["token"]
nid = msg["a"]["id"]
tid = msg["t"]
if infohash[:TOKEN_LENGTH] == token:
if msg["a"].has_key("implied_port ") and msg["a"]["implied_port "] != 0:
port = address[1]
else:
port = msg["a"]["port"]
self.master.log(infohash, (address[0], port))
except Exception:
print 'error'
pass
finally:
self.ok(msg, address)
def play_dead(self, msg, address):
try:
tid = msg["t"]
msg = {
"t": tid,
"y": "e",
"e": [202, "Server Error"]
}
self.send_krpc(msg, address)
except KeyError:
pass
def ok(self, msg, address):
try:
tid = msg["t"]
nid = msg["a"]["id"]
msg = {
"t": tid,
"y": "r",
"r": {
"id": get_neighbor(nid, self.nid)
}
}
self.send_krpc(msg, address)
except KeyError:
pass
class Master(Thread):
def __init__(self):
Thread.__init__(self)
self.setDaemon(True)
self.queue = Queue()
def run(self):
while True:
self.downloadMetadata()
def log(self, infohash, address=None):
self.queue.put([address, infohash])
def downloadMetadata(self):
# 100 threads for download metadata
for i in xrange(0, 100):
if self.queue.qsize() == 0:
sleep(1)
continue
announce = self.queue.get()
t = threading.Thread(target=download_metadata, args=(announce[0], announce[1]))
t.setDaemon(True)
t.start()
trans_queue = Queue()
if __name__ == "__main__":
# max_node_qsize bigger, bandwith bigger, spped higher
master = Master()
master.start()
print('Receiving datagrams on :6882')
dht = DHTServer(master, "0.0.0.0", 6881, max_node_qsize=10)
dht.start()
dht.auto_send_find_node() http://www.lyyyuna.com/2016/03/26/dht01/ 4. BitTorrent協定
BitTorrent 使用"分布式哈希表"(DHT)來為無 tracker 的種子(torrents)存儲 peer 之間的聯系資訊。這樣每個 peer 都成了 tracker。這個協定基于 Kademila 網絡并且在 UDP 上實作
1. "peer" 是在一個 TCP 端口上監聽的用戶端/伺服器,它實作了 BitTorrent 協定
2. "節點" 是在一個 UDP 端口上監聽的用戶端/伺服器,它實作了 DHT(分布式哈希表) 協定
DHT 由節點組成,它存儲了 peer 的位置。BitTorrent 用戶端包含一個 DHT 節點,這個節點用來聯系 DHT 中其他節點,進而得到 peer 的位置,進而通過 BitTorrent 協定下載下傳 每個節點有一個全局唯一的辨別符,作為 "node ID"。節點 ID 是一個随機選擇的 160bit(20位元組) 空間,BitTorrent infohash 也使用這樣的 160bit 空間。"距離"用來比較兩個節點 ID 之間或者節點 ID 和 infohash 之間的"遠近"(節點和節點、節點和檔案之間的距離)。節點必須維護一個路由表,路由表中含有一部分其它節點的聯系資訊。其它節點距離自己越近時,路由表資訊越詳細。是以每個節點都知道 DHT 中離自己很"近"的節點的聯系資訊,而離自己非常遠的 ID 的聯系資訊卻知道的很少
在 Kademlia 網絡中,距離是通過異或(XOR)計算的,結果為無符号整數。distance(A, B) = |A xor B|,值越小表示越近
1. 當節點要為 torrent(種子檔案) 尋找 peer(儲存了目标資源的IP) 時,它将自己路由表中的節點 ID 和 torrent 的 infohash(資源HASH) 進行"距離對比"(節點和目标檔案的距離),然後向路由表中離 infohash 最近的節點發送請求,問它們正在下載下傳這個 torrent 的 peer 的聯系資訊
2. 因為資源HASH和節點HASH都共用一套20bytes的命名空間,是以DHT節點充當了peer節點的"代理"的工作,我們不能直接向peer節點發起資源擷取請求(即使這個peer節點确實存儲了我們的目标資源),因為peer節點本身不具備處理P2P request/response能力的,我們需要借助DHT的能力,讓DHT告訴我們哪個peer節點儲存了我們想要的資源或者哪個DHT節點可能知道進而遞歸地繼續去問那個DHT網絡
3. 如果一個被聯系的節點知道下載下傳這個 torrent 的 peer 資訊,那個 peer 的聯系資訊将被回複給目前節點。否則,那個被聯系的節點則必須回複在它的路由表中離該 torrent 的 infohash 最近的節點的聯系資訊,
4. 最初的節點重複地請求比目标 infohash 更近的節點,直到不能再找到更近的節點為止
5. 查詢完了之後,用戶端把自己作為一個 peer 插入到所有回複節點中離種子最近的那個節點中,這一步背後的含義是: 我之前是請求這個資源的人,我們現在擷取到資源了,我在下載下傳這個檔案的同時,我也要充當一個新的peer來向其他的用戶端貢獻自己的檔案共享,這樣,當另外的其他用戶端在發起新的請求的時候,DHT節點就有可能把目前用戶端對應的peer傳回給新的請求方,這樣不斷發展下去,這個資源的熱度就越來越熱,下載下傳速度也越來越快
6. 請求 peer 的傳回值包含一個不透明的值,稱之為"令牌(token)"
7. 如果一個節點宣布它所控制的 peer 正在下載下傳一個種子(即該節點擁有該檔案資源),它必須在回複請求節點的同時,附加上對方向我們發送的最近的"令牌(token)"。這樣當一個節點試圖"宣布"正在下載下傳一個種子時,被請求的節點核對令牌和送出請求的節點的 IP 位址。這是為了防止惡意的主機登記其它主機的種子。由于令牌僅僅由請求節點傳回給收到令牌的同一個節點,是以沒有規定他的具體實作。但是令牌必須在一個規定的時間内被接受,逾時後令牌則失效。在 BitTorrent 的實作中,token 是在 IP 位址後面連接配接一個 secret(通常是一個随機數),這個 secret 每五分鐘改變一次,其中 token 在十分鐘以内是可接受的 這種握手驗證的原理是
請求方生成一個随機值,跟着我的請求發給被請求方,被請求方回複的時候要帶上這個随機值,那請求方就知道,你是我剛才想請求的那個人 0x1: 路由表 Routing Table
1. 每個節點維護一個路由表儲存已知的好節點。路由表中的節點是用來作為在 DHT 中請求的起始點。路由表中的節點是在不斷的向其他節點請求過程中,對方節點回複的。即DHT中的K桶中的節點,當我們請求一個目标資源的時候,我們根據HASH XOR從自己的K桶中選擇最有可能知道該資源的節點發起請求,而被請求的節點也不一定知道目标資源所在的peer,這個時候被請求方會傳回一個新的"它認為可能知道這個peer的節點",請求方收到這個新的節點後,會把這個節點儲存進自己的K桶内,然後繼續發起請求,直到找到目标資源所在的peer為止
2. 并不是我們在請求過程中收到的節點都是平等的,有的節點是好的,而另一些則不是。許多使用 DHT 協定的節點都可以發送請求并接收回複,但是不能主動回複其他節點的請求,這種節點被稱之為"壞節點"
3. 節點的路由表隻包含已知的好節點,這很重要。好節點是指在過去的 15 分鐘以内,曾經對我們的某一個請求給出過回複的節點(存活好節點),或者曾經對我們的請求給出過一個回複(不用在15分鐘以内),并且在過去的 15 分鐘給我們發送過請求。上述兩種情況都可将節點視為好節點。在 15 分鐘之後,對方沒有上述 2 種情況發生,這個節點将變為可疑的。當節點不能給我們的一系列請求給出回複時,這個節點将變為壞的。相比那些未知狀态的節點,已知的好節點會被給于更高的優先級。
# 這就反過來告訴我們,如果我們要做DHT嗅探,我們的嗅探器除了要能夠發出FIND_NODE請求及接收傳回之外,還需要能夠響應其他節點發來的請求(get_peers/announce_peer),這樣才不會被其他節點列入"可疑"甚至"壞節點"清單中
4. 路由表覆寫從 0 到 2^160 全部的節點 ID 空間。路由表又被劃分為桶(bucket),每個桶包含一部分的 ID 空間。空的路由表隻有一個桶,它的 ID 範圍從 min=0 到 max=2^160。當 ID 為 N 的節點插入到表中時,它将被放到 ID 範圍在 min <= N < max 的 桶 中
5. 空的路由表隻有一個桶,是以所有的節點都将被放到這個桶中。每個桶最多隻能儲存 K 個節點,目前 K=8。當一個桶放滿了好節點之後,将不再允許新的節點加入,除非我們自身的節點 ID 在這個桶的範圍内。在這樣的情況下,這個桶将被分裂為 2 個新的桶,每個新桶的範圍都是原來舊桶的一半。原來舊桶中的節點将被重新配置設定到這兩個新的桶中。如果一個新表隻有一個桶,這個包含整個範圍的桶将總被分裂為 2 個新的桶,每個桶的覆寫範圍從 0..2^159 和 2^159..2^160
# 以log2N的方式不斷分裂,類似于Kademlia中的K桶機制
6. 當桶裝滿了好節點,新的節點會被丢棄。一旦桶中的某個節點變為了壞的節點,那麼我們就用新的節點來替換這個壞的節點。如果桶中有在 15 分鐘内都沒有活躍過的節點,我們将這樣的節點視為可疑的節點,這時我們向最久沒有聯系的節點發送 ping。如果被 ping 的節點給出了回複,那麼我們向下一個可疑的節點發送 ping,不斷這樣循環下去,直到有某一個節點沒有給出 ping 的回複,或者目前桶中的所有節點都是好的(也就是所有節點都不是可疑節點,他們在過去 15 分鐘内都有活動)。如果桶中的某個節點沒有對我們的 ping 給出回複,我們最好再試一次(再發送一次 ping,因為這個節點也許仍然是活躍的,但由于網絡擁塞,是以發生了丢包現象,注意 DHT 的包都是 UDP 的),而不是立即丢棄這個節點或者直接用新節點來替代它。這樣,我們得路由表将充滿穩定的長時間線上的節點
7. 每個桶都應該維持一個 lastchange 字段來表明桶中節點的"新鮮"度。當桶中的節點被 ping 并給出了回複,或者一個節點被加入到了桶,或者一個節點被新的節點所替代,桶的 lastchange 字段都應當被更新。如果一個桶的 lastchange 在過去的 15 分鐘内都沒有變化,那麼我們将更新它。這個更新桶操作是這樣完成的
1) 從這個桶所覆寫的範圍中随機選擇一個 ID,并對這個 ID 執行 find_nodes 查找操作。常常收到請求的節點通常不需要常常更新自己的桶
2) 反之,不常常收到請求的節點常常需要周期性的執行更新所有桶的操作,這樣才能保證當我們用到 DHT 的時候,裡面有足夠多的好的節點
8. 在插入第一個節點到路由表并啟動服務後,這個節點應試着查找 DHT 中離自己更近的節點,這個查找工作是通過不斷的發出 find_node 消息給越來越近的節點來完成的,當不能找到更近的節點時,這個擴散工作就結束了
9. 路由表應當被啟動工作和用戶端軟體儲存(也就是啟動的時候從用戶端中讀取路由表資訊,結束的時候用戶端軟體記錄到檔案中) 0x2: BitTorrent 協定擴充 BitTorrent Protocol Extension
BitTorrent 協定已經被擴充為可以在通過 tracker 得到的 peer 之間互相交換節點的 UDP 端口号(也就是告訴對方我們的 DHT 服務端口号),在這樣的方式下,用戶端可以通過下載下傳普通的種子檔案來自動擴充 DHT 路由表(我直接知道某個節點有某一個資源)。新安裝的用戶端第一次試着下載下傳一個無 tracker 的種子時,它的路由表中将沒有任何節點,這是它需要在 torrent 檔案中找到聯系資訊
1. peers 如果支援 DHT 協定就将 BitTorrent 協定握手消息的保留位的第 8 位元組的最後一位置為 1
2. 這時如果 peer 收到一個 handshake 表明對方支援 DHT 協定,就應該發送 PORT 消息。它由位元組 0x09 開始,payload 的長度是 2 個位元組,包含了這個 peer 的 DHT 服務使用的網絡位元組序的 UDP 端口号
3. 當 peer 收到這樣的消息時應當向對方的 IP 和消息中指定的端口号的節點發送 ping
4. 如果收到了 ping 的回複,那麼應當使用上述的方法将新節點的聯系資訊加入到路由表中 0x3: Torrent 檔案擴充 Torrent File Extensions(種子檔案)
一個無 tracker 的 torrent 檔案字典不包含 announce 關鍵字,而使用 nodes 關鍵字來替代。這個關鍵字對應的内容應該設定為 torrent 建立者的路由表中 K 個最接近的節點(可供選擇的),這個關鍵字也可以設定為一個已知的可用節點(這意味着接收到這個種子檔案的用戶端能夠向這些節點發出解析請求,詢問資源的所在位置),比如這個 torrent 檔案的建立者
請不要自動加入 router.bittorrent.com 到 torrent 檔案中或者自動加入這個節點到用戶端路由表中。這裡可以仔細思考一下,這麼做還有另一個好處,這個對等網絡可以保持無中心化,對于外部新加入的新節點來說,它可以不用通過"中心引導節點"來加入網絡,隐藏了"中心引導節點"的存在,增強了對等網絡的隐蔽性
bt 種子檔案是使用 bencode 編碼的,整個檔案就 dictionary,包含以下鍵
1. info(dictinary): 必選, 表示該bt種子檔案的檔案資訊
1) 檔案資訊包括檔案的公共部分
1.1) piece length(integer): 必選, 每一資料塊的長度
1.2) pieces(string): 必選, 所有資料塊的 SHA1 校驗值
1.3) publisher(string): 可選, 釋出者
1.4) publisher.utf-8(string): 可選, 釋出者的 UTF-8 編碼
1.5) publisher-url(string): 可選, 釋出者的 URL
1.6) publisher-url.utf-8(string): 可選, 釋出者的 URL 的 UTF-8 編碼
2) 如果 bt 種子包含的是單個檔案,包含以下内容
2.1) name(string): 必選, 推薦的檔案名稱
2.2) name.utf-8(string): 可選, 推薦的檔案名稱的 UTF-8 編碼
2.3) length(int): 必選,檔案的長度機關是位元組
3) 如果是多檔案,則包含以下部分:
3.1) name(string): 必選, 推薦的檔案夾名稱
3.2) name.utf-8(string): 可選, 推薦的檔案名稱的 UTF-8 編碼
3.3) files(list): 必選, 檔案清單,每個檔案清單下面是包括每一個檔案的資訊,檔案資訊是個字典
4) 檔案字典
4.1) length(int): 必選,檔案的長度機關是位元組
4.2) path(string): 必選,檔案名稱,包含檔案夾在内
4.3) path.utf-8(string): 必選,檔案名稱 UTF-8 表示,包含檔案夾在内
4.4) filehas(string): 可選,檔案hash
4.5) ed2k(string): 可選, ed2k 資訊
2. announce(string): 必選, tracker 伺服器的位址
3. announce-list(list): 可選, 可選的 tracker 伺服器位址
4. creation date(interger): 必選, 檔案建立時間
5. comment(string): 可選, bt 檔案注釋
6. created by(string): 可選,檔案建立者 以人民的名義的BT檔案為例
d8:announce33:udp://mgtracker.org:2710/announce13:announce-listll33:udp://mgtracker.org:2710/announceel35:http://share.camoe.cn:8080/announceel29:udp://11.rarbg.me:80/announceel32:http://tracker.tfile.me/announceel40:http://open.acgtracker.com:1096/announceel34:http://mgtracker.org:2710/announceel35:udp://tracker.openbittorrent.com:80el44:udp://tracker.openbittorrent.com:80/announceel38:udp://torrent.gresille.org:80/announceel34:udp://glotorrents.pw:6969/announceel33:udp://208.67.16.113:8000/announceel31:udp://9.rarbg.com:2710/announceel30:udp://9.rarbg.me:2710/announceel31:udp://tracker.ex.ua:80/announceee10:created by13:uTorrent/204013:creation datei1491018889e8:encoding5:UTF-84:infod5:filesld6:lengthi2168824586e4:pathl6:01.mp4eed6:lengthi2175155313e4:pathl6:02.mp4eed6:lengthi2165600175e4:pathl6:03.mp4eed6:lengthi2172491370e4:pathl6:04.mp4eed6:lengthi2168274148e4:pathl6:05.mp4eed6:lengthi2174880177e4:pathl6:06.mp4eed6:lengthi373e4:pathl38:HQC@水嫩的大白菜_2017.3.31.txteee4:name60:In.the.Name.of.People.EP01-06.2017.1080p.WEB-DL.x264.AAC-HQC12:piece lengthi4194304e6:pieces62120:XXXXX(SHA1雜湊值) 表示了如下資訊
Tracker位址: udp://mgtracker.org:2710/announce
Tracker伺服器位址清單:
udp://mgtracker.org:2710/announce
http://share.camoe.cn:8080/announce
udp://11.rarbg.me:80/announce
http://tracker.tfile.me/announce
http://open.acgtracker.com:1096/announce
http://mgtracker.org:2710/announce
udp://tracker.openbittorrent.com:80
udp://tracker.openbittorrent.com:80/announce
udp://torrent.gresille.org:80/announce
udp://glotorrents.pw:6969/announce
udp://208.67.16.113:8000/announce
udp://9.rarbg.com:2710/announce
udp://9.rarbg.me:2710/announce
udp://tracker.ex.ua:80/announce
建立者: uTorrent/204013
建立時間: datei1491018889e8
encoding: UTF-8
info: 檔案清單字典(包含了一批檔案)
length: 2168824586
path: 01.mp4
..
雜湊SHA1内容: 按照每個檔案塊(pieces)的方式分别計算SHA1雜湊值9 這裡要特别注意一點:磁力連結的infohash也是根據info字段來計算的,info字段的pieces為每個資料塊的校驗值,其作用是驗證下載下傳下來的檔案是否正确,如果下載下傳下來的檔案塊計算出來的SHA1值和pieces中的SHA1校驗值不一緻,該資料塊要重新下載下傳。 是以,我們可以看出根據磁力連結下載下傳檔案是分成兩個步驟的
1. 先根據infohash下載下傳種子檔案的info字段,種子檔案并不是必須的,但是info字段卻必不可少
2. 然後根據infohash下載下傳源檔案,将下載下傳的每一個資料塊和info中的對應的SHA1校驗碼進行比較,不一緻重新下載下傳該資料塊 需要注意的是
1. 一般的種子檔案會包含announce,也就是tracker伺服器的位址(trackerless是BTTorrent的趨勢)
2. 如果沒有tracker伺服器,檔案中可能會包含nodes,nodes是存有種子資訊的peer節點,這樣的種子檔案就是trackerless torrent。如果有nodes用戶端直接從nodes擷取種子資訊
3. 而從DHT網絡中下載下傳下來的種子檔案既沒有annouce也沒有nodes,用戶端隻能通過info字段計算出hashinfo,再從bootstrap node節點開始在DHT網絡中尋找種子資訊 BT原生依靠Tracker,後來才加入dht
http://xiaoxia.org/2013/05/11/magnet-search-engine/
https://segmentfault.com/a/1190000000681331
http://www.360doc.com/content/15/0507/16/3242454_468754791.shtml 5. uTP協定
uTP協定是一個基于UDP的開放的BT點對點檔案共享協定。在uTP協定出現之前,BT下載下傳會占用網絡中大量的連結,直接導緻其它網絡應用服務品質下載下傳和網絡的擁堵,是以有很多ISP都開始限制BT的下載下傳。uTP減輕了網絡延遲并解決了傳統的基于TCP的BT協定所遇到的擁塞控制問題,提供可靠的有序的傳送。一個有效的uTP資料包包含下面格式的報頭
1. type(包類型):
1) ST_DATA = 0: 最重要的資料包,uTP就是使用該類型的包傳送資料
2) ST_FIN = 1: 關閉連接配接,這是uTP連接配接的最後一個包,類似于TCP中的FIN
3) ST_STATE = 2: 簡單的應答包,表明已從對方收到了資料包,該包不包含任何資料,seq_nr值不變
4) ST_RESET = 3: 終止連接配接,類似于TCP中的RST
5) ST_SYN = 4: 初始化連接配接,類似于TCP中的SYN,這是uTP連接配接的第一個包
2. ver: This is the protocol version. The current version is 1.
3. extension: The type of the first extension in a linked list of extension headers.
1) 0 means no extension.
2) Selective acks: There is currently one extension:
4. connection_id: This is a random, unique, number identifying all the packets that belong to the same connection. Each socket has one connection ID for sending packets and a different connection ID for receiving packets. The endpoint initiating the connection decides which ID to use, and the return path has the same ID + 1.
uTP的一個很重要的特點是使用connection id來辨別一次連接配接,而不是每個包算一次連接配接。是以在分析ST_DATA時,需要注意找所有connection id相同的資料包,然後按seq_nr排序,seq_nr應該是依次遞增的(注意ST_STATE包不會增加seq_nr值),如果發現兩個ST_DATA的seq_nr值相同則說明後面那個封包是重複封包需要忽略掉,如果發現兩個ST_DATA的seq_nr值不是連續的,中間差了一個或多個,則可能是由于網絡原因發生了丢包現象,資料包将不可用
5. timestamp_microseconds: This is the 'microseconds' parts of the timestamp of when this packet was sent. This is set using gettimeofday() on posix and QueryPerformanceTimer() on windows. The higher resolution this timestamp has, the better. The closer to the actual transmit time it is set, the better.
6. timestamp_difference_microseconds: This is the difference between the local time and the timestamp in the last received packet, at the time the last packet was received. This is the latest one-way delay measurement of the link from the remote peer to the local machine.
When a socket is newly opened and doesn't have any delay samples yet, this must be set to 0.
7. wnd_size: Advertised receive window. This is 32 bits wide and specified in bytes. The window size is the number of bytes currently in-flight, i.e. sent but not acked. The advertised receive window lets the other end cap the window size if it cannot receive any faster, if its receive buffer is filling up. When sending packets, this should be set to the number of bytes left in the socket's receive buffer.
8. seq_nr
9. ack_nr 下面是一個簡單的ST_SYN封包,從192.168.18.33發送到112.208.162.161,seq_nr = 31445,ack_nr = 0, connection id = 14487
112.208.162.161收到
ST_SYN
封包後,會向192.168.18.33發送一個
ST_STATE
封包,表示已收到。如果沒有回複,則連接配接不能建立。如下圖所示,seq_nr = 9690,ack_nr = 31445,connection id = 14487
在
uTP
連接配接建立之後,就開始傳送需要的資料了。peer和peer之間傳送資料也是遵循着一定的規範,這就是下面要講的
Peer Wire
協定
http://www.bittorrent.org/beps/bep_0029.html 6. Peer Wire協定
在BitTorrent中,節點的尋址是通過DHT實作的,而實際的資源共享和傳輸則需要通過uTP以及Peer Wire協定來配合完成
0x1: 握手
Peer Wire協定是Peer之間的通信協定,通常由一個握手消息開始。握手消息的格式是這樣的
<pstrlen><pstr><reserved><info_hash><peer_id> 在BitTorrent協定的v1.0版本, pstrlen = 19, pstr = "BitTorrent protocol",info_hash是上文中提到的磁力連結中的btih,peer_id每個用戶端都不一樣,但是有着一定的規則,根據前面幾個字元可以推斷出用戶端的類型
'AG' - Ares
'A~' - Ares
'AR' - Arctic
'AV' - Avicora
'AX' - BitPump
'AZ' - Azureus
'BB' - BitBuddy
'BC' - BitComet
'BF' - Bitflu
'BG' - BTG (uses Rasterbar libtorrent)
'BR' - BitRocket
'BS' - BTSlave
'BX' - ~Bittorrent X
'CD' - Enhanced CTorrent
'CT' - CTorrent
'DE' - DelugeTorrent
'DP' - Propagate Data Client
'EB' - EBit
'ES' - electric sheep
'FT' - FoxTorrent
'FX' - Freebox BitTorrent
'GS' - GSTorrent
'HL' - Halite
'HN' - Hydranode
'KG' - KGet
'KT' - KTorrent
'LH' - LH-ABC
'LP' - Lphant
'LT' - libtorrent
'lt' - libTorrent
'LW' - LimeWire
'MO' - MonoTorrent
'MP' - MooPolice
'MR' - Miro
'MT' - MoonlightTorrent
'NX' - Net Transport
'PD' - Pando
'qB' - qBittorrent
'QD' - QQDownload
'QT' - Qt 4 Torrent example
'RT' - Retriever
'S~' - Shareaza alpha/beta
'SB' - ~Swiftbit
'SS' - SwarmScope
'ST' - SymTorrent
'st' - sharktorrent
'SZ' - Shareaza
'TN' - TorrentDotNET
'TR' - Transmission
'TS' - Torrentstorm
'TT' - TuoTu
'UL' - uLeecher!
'UT' - µTorrent
'VG' - Vagaa
'WD' - WebTorrent Desktop
'WT' - BitLet
'WW' - WebTorrent
'WY' - FireTorrent
'XL' - Xunlei
'XT' - XanTorrent
'XX' - Xtorrent
'ZT' - ZipTorrent 可以看到,Peer Wire協定是在uTP協定基礎上裡層應用态協定。收到握手消息後,對方也會回複一個握手消息,并且開始協商一些基本的資訊。如下圖是握手封包的回複
http://www.bittorrent.org/beps/bep_0020.html
https://wiki.theory.org/BitTorrentSpecification#peer_id 7. BitTorrent協定擴充與ut_metadata和ut_pex(Extension for Peers to Send Metadata Files)
借助于DHT/KRPC完成了的Node節點尋址,資源對應的Peer擷取,以及uTP以及Peer Wire完成握手之後,接下要就要"動真格"了,我們需要擷取到目标資源的"種子資訊(infohash/filename/pieces分塊sha1)"了,這個擴充的目的是為了在最初沒有.torrent檔案的情況仍然能夠加入swarm并能夠完成下載下傳。這個擴充能讓用戶端從peer哪裡下載下傳metadata。這讓支援magnet link成為了可能,magnet link是一個web頁上的連結,僅僅包含了足夠加入swarm的足夠資訊(info hash)
0x1: Metadata
這個擴充僅僅傳輸.torrent檔案的info-字典字段,這個部分可以由infohash來驗證。在這篇文檔中,.torrent的這個部分被稱為metadata。
Metadata被分塊,每個塊有16KB(16384位元組),Metadata塊從0開始索引,所有快的大小都是16KB,除了最後一個塊可能比16KB小
0x2: Extension頭部
Metadata擴充使用extension協定(BEP0010)來聲稱它的存在。它在extension握手消息的頭部m字典加入ut_metadata項。它辨別了這個消息可以使用這個消息碼,同時也可以在握手消息中加入metadata_size這個整型字段(不是在m字典中)來指定metadata的位元組數
{'m': {'ut_metadata', 3}, 'metadata_size': 31235} 0x3: Extension消息
Extension消息都是bencode編碼,這裡有3類不同的消息
0. request(請求):
請求消息并不在字典中附加任何關鍵字,這個消息的回複應當來自支援這個擴充的peer,是一個reject或者data消息,回複必須和請求所指出的片相同
Peer必須保證它所發送的每個片都通過了infohash的檢測。即直到peer獲得了整個metadata并通過了infohash的驗證,才能夠發送片(即一個peer應該保證自己已經完整從其他peer中拷貝了一份相同的資源檔案後,才能繼續響應其他節點的拷貝請求)。Peers沒有獲得整個metadata時,對收到的所有metadata請求都必須直接回複reject消息
# exampel
{'msg_type': 0, 'piece': 0}
d8:msg_typei0e5:piecei0ee
# 這代表請求消息在請求metadata的第一片
1. data
這個data消息需要在字典中添加一個新的字段,"total_size".這個關鍵字段和extension頭的"metadata_size"有相同的含義,這是一個整型
Metadata片被添加到bencode字典後面,他不是字典的一部分,但是是消息的一部分(必須包括長度字首)。
如果這個片是metadata的最後一個片,他可能小于16KB。如果它不是metadata的最後一片,那大小必須是16KB
# example
{'msg_type': 1, 'piece': 0, 'total_size': 3425}
d8:msg_typei1e5:piecei0e10:total_sizei34256eexxxxxxxx...
# x表示二進制資料(metadata)
2. reject
Reject消息沒有附件的關鍵字。它的意思是peer沒有請求的這個metadata片資訊
在用戶端收到收到一定數目的消息後,可以通過拒絕請求消息來進行洪泛攻擊保護。尤其在metadata的數目乘上一個因子時
#
{'msg_type': 2, 'piece': 0}
d8:msg_typei1e5:piecei0ee 0x4: request消息: Metadat資訊擷取過程
1. 擴充支援互動(互相詢問對方支援哪些擴充)
根據BEP-010我們知道,擴充消息一般在Peer Wire握手之後立即發出,是一個B編碼的字典
{
e: 0,
ipv4: xxx,
ipv6: xxx,
complete_ago: 1,
m:
{
upload_only: 3,
lt_donthave: 7,
ut_holepunch: 4,
ut_metadata: 2,
ut_pex: 1,
ut_comment: 6
},
matadata_size: 45377,
p: 33733,
reqq: 255,
v: BitTorrent 7.9.3
yp: 19616,
yourip: xxx
}
1. m: 是一個字典,表示用戶端支援的所有擴充以及每個擴充的編号
1) ut_pex: 表示該用戶端支援PEX(Peer Exchange)
2) ut_metadata表示支援BEP-009(也就是交換種子檔案的metadata) 2. 握手handshake
我們在完成雙方握手之後,并且得到了對方支援的擴充資訊。接着我們發出下面的請求
資源請求方也通知被請求方本機支援的擴充情況,然後後面接着一個擴充消息(從上面的m字典可以看到可能會有多種不同的擴充消息),具體是哪個類型的擴充消息由message ID後面那個數字決定,這個數字對應着m字典中的編号。譬如我們這裡的消息是
00 00 00 1b 14 02 ... 00 00 00 1b
1. 消息長度為 0x1b (27 bytes)
2. 14 表示是 擴充消息(0x14 = 20)
3. 02 對應上面m字典中的 ut_metadata,是以我們這個消息是ut_metadata消息 再次看上圖的截圖,我們這裡的圖顯示的是[msg_type: 0, piece: 2]正是request消息,意思是向對象請求第二個piece的資料,piece的意思是分塊的意思,根據BEP-009我們知道,種子檔案的metadata(也就是info部分)會按16KB分成若幹塊,除最後一塊每一塊的大小都是16KB,每一塊從0開始按順序進行編号。是以這個請求的意思就是向對象請求第三塊的metadata
3. 回複data資訊
從圖中形象的表示可以看到torrent檔案整個info的長度為45377,這個值正是上面握手封包後的擴充消息中的metadata_size的值。在發送request消息之後,接下來對方應該回複data消息(如果對方有資料)或reject消息(如果對方沒有資料)。下圖是針對上面的request消息的回複
msg_type
為1表示是回複就是我所需要的資料,但是注意這裡的資料并沒完,由于uTP協定的緣故,我們可以根據
connection id
找到這個連接配接後續的所有資料。 這裡其實一共收到了三個消息,我們分别來看一下
00 00 00 03 09 83 c5 --> message ID為9,port消息,表示端口号為0x83c5 = 33733
00 00 00 03 14 03 01 --> message ID為20(0x14),extend消息,編号03為upload_only,表示設定upload_only = 1
00 00 31 70 14 02 xx --> message ID為20(0x14),extend消息,編号02為ut_metadata,後面的xx表示[msg_type: 1, piece: 2, total_size: 45377]和相應塊的metadata資料 看第三個消息可以知道消息長度為
0x3170
,這個長度包括了
[msg_type...]
這一串字元串的長度,共
0x2f
個位元組,我們将其減去就得到了piece2的長度:
0x3170 - 0x2f = 0x3141
我們上面說過每個塊的大小應該是16KB,也就是
0x4000
,這裡的大小為
0x3141
,隻可能是最後一塊。我們稍微計算驗證下,将整個info的長度
45377(0xb141)
按16KB分塊
piece 0: 0x0001 ~ 0x4000 長度0x4000
piece 1: 0x4001 ~ 0x8000 長度0x4000
piece 2: 0x8001 ~ 0xb141 長度0x3141 可以看到piece2正是最後一塊,大小為
0x3141
。至此我們得到了第二塊的metadata,然後通過
request
消息擷取piece0和piece1擷取第一和第二塊的metadata,将三塊的消息合并成torrent檔案
info
字段,然後再加上
create date
、
create by
或
comment
等資訊,種子檔案就算完成下載下傳了。可見要在BT網絡中完成實際的資源下載下傳,就必須完整擷取到種子檔案,因為種子檔案中不單有infohash值,還有piece sha1校驗碼,分塊下載下傳時需要進行校驗,而磁力連接配接magnet隻是一個最小化入口,最終還是需要通過磁力連接配接在DHT網絡中擷取種子檔案的完整資訊
0x5: 校驗info_hash
我們将從DHT網絡中下載下傳的種子檔案和原始的種子檔案進行比較,可以看到annouce和annouce-list字段都丢掉了(引入了DHT網絡後,BT可以實作Trackerless),create date發生了變化,info字段不變
磁力鍊是為了簡化BT種子檔案的分發,封裝了一個簡化版的magnet url,用戶端解析這個magnet磁力鍊之後,需要在DHT網絡中尋找infohash對應的peer節點,擷取節點成功後,向目标peer節點擷取真正的BitTorrent種子(.torrent檔案)資訊(包含了完整的pieces SHA1雜湊資訊),另一個管道就是傳統的Bt種子論壇會分發.BT種子檔案
http://www.bittorrent.org/beps/bep_0010.html
http://www.aneasystone.com/archives/2015/05/analyze-magnet-protocol-using-wireshark.html 8. 用P2P對等網絡思想改造C/S、B/S架構的思考
以下這個章節是我在谷歌時遇到的文章和片段,我感覺我的思路很混亂,原因是我當今網際網路的網絡架構和具體的業務場景有密切的關系,是重内容還是重連接配接,是長連還是短連接配接,需要共享的是meta資訊是資源本身,要共享的消息是否需要實時地廣播到全網,很多問題都在腦子裡雜糅在一起,一時都梳理不清我到底在思考什麼問題99
0x1: IPTV采用客戶機/伺服器模式的局限性
IPTV一般泛指通過IP網絡傳輸音視訊内容并用電視機收看的業務。目前電信營運商提供的IPTV營運在支援多點傳播的可管理的IP網上,其主要業務為直播電視(轉播電視廣播)、時移電視、視訊點播(VoD)以及互動資訊服務等。
目前中國的IPTV系統采用客戶機/伺服器模式提供單點傳播和點播(包括VoD和時移電視)業務。由于伺服器輸入/輸出(I/O)“瓶頸”的限制,一台伺服器隻能支援有限的并發流(千數量級的并發流)。要解決十萬、百萬使用者同時收看的問題,不僅需要大量伺服器,還需要極寬的網絡帶寬。目前的解決方法一是采用多點傳播來提供廣播,二是采用内容傳送網絡(CDN)技術将伺服器盡量放到離客戶近的地方以減輕網絡負荷。現有網絡要支援多點傳播,需要進行改造,這不僅導緻成本增加還将損失網際網路無所不在的通達能力。是以,IPTV隻能在經過改造的局部網絡内提供廣播業務。對于IPTV進一步向網絡新媒體演化趨勢,目前的客戶機/伺服器模式也不能很好地提供支援。
客戶機/伺服器已經成為制約IPTV發展的“瓶頸”,解決方法是體系結構向對等連接配接(P2P)模式演化
0x2: P2P内容分發技術的演化
計算機網絡發展演化過程不斷在集中和分布之間擺動。早期計算機的使用模式是衆多使用者共享大型計算機,以後發展了個人計算機,從集中走向分布。在網際網路上存在類似情況,開始采用客戶機/伺服器方式,使用網站上集中的伺服器。進一步發展将走向分布式,集中的伺服器變成分布式的。
P2P技術将許多使用者結合成一個網絡,共享其中的帶寬,共同處理其中的資訊。與傳統的客戶機/伺服器模式不同,P2P工作方式中,每一個客戶終端既是客戶機又是伺服器。以共享下載下傳檔案為例,下載下傳同一個檔案的衆多使用者中的每一個使用者隻需要下載下傳檔案的一個片段,然後互相交換,最終每個使用者都得到完整的檔案
1. 實作P2P的第一步是在網際網路上進行檢索,找到擁有所需内容和計算能力的結點位址
2. 第二步是通過網際網路實作對等連接配接 為了充分發揮網際網路無所不在的優勢,不能對網際網路協定進行任何修改。解決的方法是在基礎的網際網路上架設一個P2P重疊網,P2P重疊網分為以下幾類
1. 無組織的P2P重疊網: 目前在網際網路上廣泛使用的大多是無組織的P2P重疊網,如BitTorrent(BT)下載下傳。無組織的P2P重疊網已經演進了幾代
1) 第一代P2P網絡采用中央控制網絡體系結構。早期的軟體Napster就采用這種結構
2) 第二代P2P采用分散分布網絡體系結構,适合在自組織(Ad hoc)網上應用,如即時通信等
3) 第三代P2P采用混合網絡體系結構,這種模式綜合了第一代和第二代的優點,用分布的超級結點取代中央檢索伺服器,并進一步利用有組織網的分布式哈希表(DHT)加速檢索
2. 有組織的P2P重疊網: 有組織的P2P重疊網目前還處于學術界研究階段,如Tapestry、Chord、Pastry和CAN等網絡。正在研究的新一代的P2P應用包括多點傳播、網絡存儲等都運作在這種有組織的P2P重疊網上
3. 混合型網三大類: 一些實用系統開始使用混合型結構 廣播影視資料内容的分發主要采用兩種方法
1. 一種方法是先下載下傳,下載下傳後再觀看,這種方法現在被稱為播客(Podcast)
2. 另一種就是用流媒體的方式邊下載下傳邊收看。P2P技術對這兩種方式都支援 0x3: P2P流媒體直播技術進展
1. 利用P2P技術實作大規模流媒體點播和直播的系統Webcast出現于1998年。Webcast利用一棵二叉多點傳播樹在使用者之間進行實時多媒體資料的傳輸和共享。此後由于流媒體直播服務相對簡單,首先得到快速發展
2. 2000年出現第一套P2P視訊直播系統的原型——ESM系統,該系統采用使用者網狀結構互連構造最優媒體資料多點傳播樹的方法在使用者間傳播實時的多媒體内容。由于算法限制,這套系統隻能擴充到幾千人同時線上,但已經标志着P2P流媒體直播系統進入了系統發展期。
3. 此後各種原型系統、高度可擴充的應用層多點傳播協定大量湧現。其中典型的系統有提供音頻廣播的Standford大學的Peercast系統和德國的P2PRadio系統,他們均采用開放源代碼。而應用層多點傳播協定有
1) 微軟的Coopnet/Splitstream協定
2) 思科的Overcast協定
3) 馬裡蘭大學的NICE協定
4) 伯克利大學的Gossip協定等
雖然這些系統和協定尚不能實用,但為P2P流媒體直播打下了堅實的理論基礎
5. 2004年5月歐洲杯期間,香港科技大學張欣研博士開發的CoolStreaming原型系統在Planetlab網上試用獲得成功。這套系統使用Goosip協定在使用者之間傳播控制信令,使用類似于BT的"多點對多點資料傳播協定"在使用者之間傳送媒體資料包。CoolStreaming系統是第一次真正将高可擴充和高可靠性的網狀多點傳播協定應用在P2P流直播系統當中,标志P2P直播技術進入準商業運作階段
在CoolStreaming成功的鼓舞下,中國流媒體直播技術和業務發展迅速,在世界上獨樹一幟,目前中國有10多個網站使用各自發展的軟體提供P2P流媒體直播業務。使用者最多的是PPLive網采用的Synacast系統。Synacast系統的核心是一套完整的網上視訊傳輸和營運支援業務平台。在此平台上可以友善地完成節目采集、釋出、認證、統計分析等功能
由于采用了P2P技術進行流媒體内容的分發,Synacast系統對伺服器端的要求比較低。通常情況下,每一個源分發服務程式隻占用5%左右的CPU負載,20 MB的記憶體和10 Mb/s的網絡帶寬。以PPLive網為例,該網站原本使用的是傳統的Windows Media伺服器,一台100 Mb/s伺服器以單點傳播方式提供一路節目的直播,最多可支援200~300個使用者并發通路;當使用了Synacast技術後,一台100 Mb/s接入網際網路的普通PC伺服器可以同時提供5~10路視訊節目的直播,每一路節目均可以支援百萬使用者同時收視 0x4: P2P流媒體點播技術進展
與直播領域相比,在流媒體點播領域,P2P技術的發展速度相對較為緩慢。主要是因為點播當中的高度互動性需求,使得實作的複雜程度較高。此外節目源版權因素對P2P點播技術的應用有阻礙
1. 2000年,美國普度大學實作的GnuStream系統是在Gnutella網絡基礎之上的第一個P2P準點播系統。該系統也使用了網狀多點傳播的政策。由于版權因素的限制,這套系統沒有能得到大規模的使用
2. 2000年之後,P2P的點播技術在适用于點播的應用層傳輸協定技術、底層編碼技術以及數字版權技術等方面都有重要進展
1) 在應用層傳輸協定方面,比較重要的有2002年提出的P2Cast協定
2) 2003年提出的CollectCast協定(用于PROMISE系統)
3. 目前正在發展實用的P2P點播系統,開始進入商業應用階段
4. 美國線上(AOL)和華納兄弟合作将在網際網路上采用Kontiki公司P2P VoD推出In2TV業務,為客戶提供電視劇點播業務。有6類電視劇節目,具有DVD品質的視訊效果。In2TV還提供各種互動服務如遊戲等 P2P流媒體直播不同,P2P流媒體終端必須擁有硬碟,其成本高于直播終端
0x5: 用P2P思想改造遊戲/網遊/手遊用戶端
這裡在DHT的研究基礎上,稍微延伸出來做一些思考,我們是否可以有可能用P2P對等網絡建立一個無中心化的網遊網絡拓樸的可能,像遊戲用戶端這種場景和浏覽網頁資源又不完全一樣,遊戲是需要TCP長連接配接hold在那裡的,而HTTP TCP是一次性的連接配接資源擷取後就結束了
1. 登入用戶端(包括PC用戶端和手機用戶端)需要進行改造,需要支援UDP DHT,它不再直接和中心伺服器進行握手登入,而是在P2P網絡中,以對等的關系共同存儲所有使用者的帳号資料資訊 (裝備/遊戲币等)
# 這裡需要明白,如果我們隻是讓P2P來負責共享雲端的業務負載伺服器,即承擔分布式排程的問題,本質問題并沒有改變,攻擊者依然能夠很容易擷取到所有的負載業務伺服器
2. 要解決可信認真問題,即網絡中任意節點廣播出來的說現網的使用者賬戶資訊,需要讓網絡中的其他使用者(可以了解為礦工)進行數學可信驗證,以達到不可僞造的面對
3. 但是同時伴随着問題2,如果用Bit币網絡那種"挖礦驗證"的方法,一次"賬本廣播"需要至少經過3層的挖礦後才可以被全網所有節點接收,而這個時間周期要花費地較長,不是很符合遊戲這種對實時性要求較高的業務場景
4. 新節點入網問題,對DHT網絡來說,新節點的入網有2種方式:1)通過引導節點來引導進入、2)通過現網随機某個節點釋出的磁力連結進入網絡(但是這個情況同樣需要一個中心節點服務磁力分發)。總的來說,依然存在一個單點問題,如果這個單點入口Down了,則新節點的入網将無法進行,整個網絡的魯棒性依然得不到保證 http://www.zte.com.cn/cndata/magazine/zte_communications/2006/3/magazine/200605/t20060525_150563.html
http://www.zte.com.cn/cndata/magazine/zte_communications/2007/6/magazine/200712/t20071220_150729.html
http://www.it.com.cn/f/news/079/28/484649.htm
http://www.chinaunicom.com.cn/upload/1246533688964.pdf Copyright (c) 2017 LittleHann All rights reserved