背景
ClickHouse 作為開源 OLAP 引擎,因其出色的性能表現在大資料生态中得到了廣泛的應用。差別于 Hadoop 生态元件通常依賴 HDFS 作為底層的資料存儲,ClickHouse 使用本地盤來自己管理資料,官方推薦使用 SSD 作為存儲媒體來提升性能。但受限于本地盤的容量上限以及 SSD 盤的價格,使用者很難在容量、成本和性能這三者之間找到一個好的平衡。JuiceFS 的某個客戶近期就遇到了這樣的難題,希望将 ClickHouse 中的溫冷資料從 SSD 盤遷移到更大容量、更低成本的存儲媒體,更好地支撐業務查詢更長時間資料的需求。
JuiceFS 是基于對象存儲實作并完全相容 POSIX 的開源分布式檔案系統,同時 JuiceFS 的資料緩存特性可以智能管理查詢熱點資料,非常适合作為 ClickHouse 的存儲系統,下面将詳細介紹這個方案。
MergeTree 存儲格式簡介
在介紹具體方案之前先簡單了解一下 MergeTree 的存儲格式。MergeTree 是 ClickHouse 最主要使用的存儲引擎,當建立表時可以通過
PARTITION BY
語句指定以某一個或多個字段作為分區字段,資料在磁盤上的目錄結構類似如下形式:
$ ls -l /var/lib/clickhouse/data/<database>/<table>
drwxr-xr-x 2 test test 64B Mar 8 13:46 202102_1_3_0
drwxr-xr-x 2 test test 64B Mar 8 13:46 202102_4_6_1
drwxr-xr-x 2 test test 64B Mar 8 13:46 202103_1_1_0
drwxr-xr-x 2 test test 64B Mar 8 13:46 202103_4_4_0
以
202102_1_3_0
為例,
202102
是分區的名稱,
1
是最小的資料塊編号,
3
是最大的資料塊編号,
是 MergeTree 的深度。可以看到 202102 這個分區不止一個目錄,這是因為 ClickHouse 每次在寫入的時候都會生成一個新的目錄,并且一旦寫入以後就不會修改(immutable)。每一個目錄稱作一個「part」,當 part 逐漸變多以後 ClickHouse 會在背景對多個 part 進行合并(compaction),通常的建議是不要保留過多 part,否則會影響查詢性能。
每個 part 目錄内部又由很多大大小小的檔案組成,這裡面既有資料,也有一些元資訊,一個典型的目錄結構如下所示:
$ ls -l /var/lib/clickhouse/data/<database>/<table>/202102_1_3_0
-rw-r--r-- 1 test test ?? Mar 8 14:06 ColumnA.bin
-rw-r--r-- 1 test test ?? Mar 8 14:06 ColumnA.mrk
-rw-r--r-- 1 test test ?? Mar 8 14:06 ColumnB.bin
-rw-r--r-- 1 test test ?? Mar 8 14:06 ColumnB.mrk
-rw-r--r-- 1 test test ?? Mar 8 14:06 checksums.txt
-rw-r--r-- 1 test test ?? Mar 8 14:06 columns.txt
-rw-r--r-- 1 test test ?? Mar 8 14:06 count.txt
-rw-r--r-- 1 test test ?? Mar 8 14:06 minmax_ColumnC.idx
-rw-r--r-- 1 test test ?? Mar 8 14:06 partition.dat
-rw-r--r-- 1 test test ?? Mar 8 14:06 primary.idx
其中比較重要的檔案有:
primary.idx
:這個檔案包含的是主鍵資訊,但不是目前 part 全部行的主鍵,預設會按照 8192 這個區間來存儲,也就是每 8192 行存儲一次主鍵。
ColumnA.bin
:這是壓縮以後的某一列的資料,ColumnA 隻是這一列的代稱,實際情況會是真實的列名。壓縮是以 block 作為最小機關,每個 block 的大小從 64KiB 到 1MiB 不等。
ColumnA.mrk
:這個檔案儲存的是對應的 ColumnA.bin 檔案中每個 block 壓縮後和壓縮前的偏移。
partition.dat
:這個檔案包含的是經過分區表達式計算以後的分區 ID。
minmax_ColumnC.idx
:這個檔案包含的是分區字段對應的原始資料的最小值和最大值。
基于 JuiceFS 的存算分離方案
因為 JuiceFS 完全相容 POSIX,是以可以把 JuiceFS 挂載的檔案系統直接作為 ClickHouse 的磁盤來使用。這種方案下資料會直接寫入 JuiceFS,結合為 ClickHouse 節點配置的緩存盤,查詢時涉及的熱資料會自動緩存在 ClickHouse 節點本地。整體方案如下圖所示。
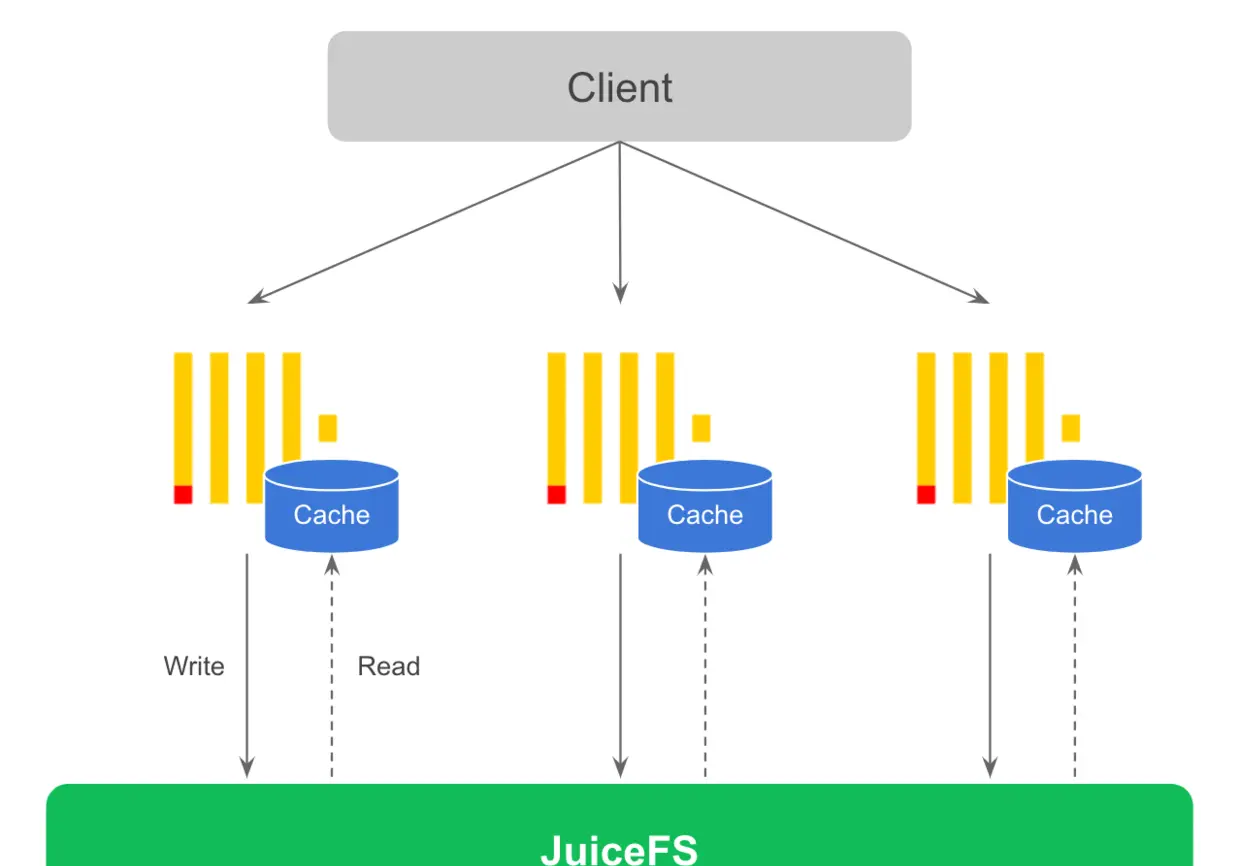
ClickHouse 在寫入時會産生大量的小檔案,是以如果寫入壓力較大這個方案對寫入和查詢性能都會有一定影響。建議在寫入資料時增大寫入緩存,盡量一次寫入更多資料來避免這個小檔案過多的問題。最簡單的做法是使用 ClickHouse 的 Buffer 表,基本上不需要修改應用代碼就可以解決小檔案過多的問題,适合當 ClickHouse 當機時允許少量資料丢失的場景。這樣做的好處是存儲和計算完全分離,ClickHouse 節點完全無狀态,如果節點故障可以很快恢複,不涉及任何資料拷貝。未來可以讓 ClickHouse 感覺到底層存儲是共享的,實作自動的無資料拷貝遷移。
同時由于 ClickHouse 通常應用在實時分析場景,這個場景對于資料實時更新的要求比較高,在分析時也需要經常性地查詢新資料。是以資料具有比較明顯的冷熱特征,即一般新資料是熱資料,随着時間推移曆史資料逐漸變為冷資料。利用 ClickHouse 的存儲政策(storage policy)來配置多塊磁盤,通過一定條件可以實作自動遷移冷資料到 JuiceFS。整體方案如下圖所示。

這個方案中資料會先寫入本地磁盤,當滿足一定條件時 ClickHouse 的背景線程會異步把資料從本地磁盤遷移到 JuiceFS 上。和第一個方案一樣,查詢時也會自動緩存熱資料。注意圖中為了區分寫和讀是以畫了兩塊磁盤,實際使用中沒有這個限制,可以使用同一個盤。雖然這個方案不是完全的存儲計算分離,但是可以滿足對寫入性能要求特别高的場景需求,也保留一定的存儲資源彈性伸縮能力。下面會詳細介紹這個方案在 ClickHouse 中如何配置。
ClickHouse 支援配置多塊磁盤用于資料存儲,下面是示例的配置檔案:
<storage_configuration>
<disks>
<jfs>
<path>/jfs</path>
</jfs>
</disks>
</storage_configuration>
上面的
/jfs
目錄即是 JuiceFS 檔案系統挂載的路徑。在把以上配置添加到 ClickHouse 的配置檔案中,并成功挂載 JuiceFS 檔案系統以後,就可以通過 MOVE PARTITION 指令将某個 partition 移動到 JuiceFS 上,例如:
ALTER TABLE test MOVE PARTITION 'xxx' TO DISK 'jfs';
當然這種手動移動的方式隻是用于測試,ClickHouse 支援通過配置存儲政策的方式來将資料自動從某個磁盤移動到另一個磁盤。下面是示例的配置檔案:
<storage_configuration>
<disks>
<jfs>
<path>/jfs</path>
</jfs>
</disks>
<policies>
<hot_and_cold>
<volumes>
<hot>
<disk>default</disk>
<max_data_part_size_bytes>1073741824</max_data_part_size_bytes>
</hot>
<cold>
<disk>jfs</disk>
</cold>
</volumes>
<move_factor>0.1</move_factor>
</hot_and_cold>
</policies>
</storage_configuration>
上面的配置檔案中有一個名為
hot_and_cold
的存儲政策,其中定義了兩個 volume,名為
hot
的 volume 是預設的 SSD 盤,名為
cold
的 volume 即是上一步
disks
中定義的 JuiceFS 盤。這些 volume 在配置檔案中的順序很重要,資料會首先存儲到第一個 volume 中,而
max_data_part_size_bytes
這個配置表示當資料 part 超過指定的大小時(示例中是 1GiB)自動從目前 volume 移動到下一個 volume,也就是把資料從 SSD 盤移動到 JuiceFS。最後的
move_factor
配置表示當 SSD 盤的磁盤容量超過 90% 時也會觸發資料移動到 JuiceFS。
最後在建立表時需要顯式指定要用到的存儲政策:
CREATE TABLE test (
...
) ENGINE = MergeTree
...
SETTINGS storage_policy = 'hot_and_cold';
當滿足資料移動的條件時,ClickHouse 就會啟動背景線程去執行移動資料的操作,預設會有 8 個線程同時工作,這個線程數量可以通過
background_move_pool_size
配置調整。
除了配置存儲政策以外,還可以在建立表時通過
TTL
将超過一段時間的資料移動到 JuiceFS 上,例如:
CREATE TABLE test (
d DateTime,
...
) ENGINE = MergeTree
...
TTL d + INTERVAL 1 DAY TO DISK 'jfs'
SETTINGS storage_policy = 'hot_and_cold';
上面的例子是将超過 1 天的資料移動到 JuiceFS 上,結合存儲政策一起可以非常靈活地管理資料的生命周期。
寫入性能測試
采用冷熱資料分離方案以後資料并不會直接寫入 JuiceFS,而是先寫入 SSD 盤,再通過背景線程異步遷移到 JuiceFS 上。但是我們希望直接評估不同存儲媒體在寫資料的場景有多大的性能差異,是以這裡在測試寫入性能時沒有配置冷熱資料分離的存儲政策,而是讓 ClickHouse 直接寫入不同的存儲媒體。
具體測試方法是将真實業務中的某一張 ClickHouse 表作為資料源,然後使用 INSERT INTO 語句批量插入千萬級行數的資料,比較直接寫入 SSD 盤、JuiceFS 以及對象存儲的吞吐。最終的測試結果如下圖:
以 SSD 盤作為基準,可以看到 JuiceFS 的寫入性能與 SSD 盤有 30% 左右的性能差距,但是相比對象存儲有 11 倍的性能提升。這裡 JuiceFS 的測試中開啟了 writeback 選項,這是因為 ClickHouse 在寫入時每個 part 會産生大量的小檔案(KiB 級),用戶端采用異步寫入的方式能明顯提升性能,同時大量的小檔案對于查詢性能也會造成一定影響。
在了解了直接寫入不同媒體的性能以後,接下來測試冷熱資料分離方案的寫入性能。經過實際業務測試,基于 JuiceFS 的冷熱資料分離方案表現穩定,因為新資料都是直接寫入 SSD 盤,是以寫入性能與上面測試中的 SSD 盤性能相當。SSD 盤上的資料可以很快遷移到 JuiceFS 上,在 JuiceFS 上對資料 part 進行合并也都是沒有問題的。
查詢性能測試
查詢性能測試使用真實業務中的資料,并選取幾個典型的查詢場景進行測試。其中 q1-q4 是掃描全表的查詢,q5-q7 是命中主鍵索引的查詢。測試結果如下圖:
可以看到 JuiceFS 與 SSD 盤的查詢性能基本相當,平均差異在 6% 左右,但是對象存儲相比 SSD 盤有 1.4 至 30 倍的性能下降。得益于 JuiceFS 高性能的中繼資料操作以及本地緩存特性,可以自動将查詢請求需要的熱資料緩存在 ClickHouse 節點本地,大幅提升了 ClickHouse 的查詢性能。需要注意的是以上測試中對象存儲是通過 ClickHouse 的 S3 磁盤類型進行通路,這種方式隻有資料是存儲在對象存儲上,中繼資料還是在本地磁盤。如果通過類似 S3FS 的方式把對象存儲挂載到本地,性能會有進一步的下降。
在完成基礎的查詢性能測試以後,接下來測試冷熱資料分離方案下的查詢性能。差別于前面的測試,當采用冷熱資料分離方案時,并不是所有資料都在 JuiceFS 中,資料會優先寫入 SSD 盤。
首先選取一個固定的查詢時間範圍,評估 JuiceFS 緩存對性能的影響,測試結果如下圖:
跟固定時間範圍的查詢一樣,從第二次查詢開始因為緩存的建立帶來了 78% 左右的性能提升。不同的地方在于第四次查詢因為涉及到查詢新寫入或者合并後的資料,而 JuiceFS 目前不會在寫入時緩存大檔案,會對查詢性能造成一定影響,之後會提供參數允許緩存寫入資料來改善新資料的查詢性能。
總結
通過 ClickHouse 的存儲政策可以很簡單地将 SSD 和 JuiceFS 結合使用,實作性能與成本的兩全方案。從寫入和查詢性能測試的結果上來看 JuiceFS 完全可以滿足 ClickHouse 的使用場景,使用者不必再擔心容量問題,在增加少量成本的情況下輕松應對未來幾倍的資料增長需求。JuiceFS 目前已經支援超過 20 家公有雲的對象存儲,結合完全相容 POSIX 的特性,不需要改動 ClickHouse 任何一行代碼就可以輕松接入雲上的對象存儲。
展望
在目前越來越強調雲原生的環境下,存儲計算分離已經是大勢所趨。ClickHouse 2021 年的 roadmap 上已經明确把存儲計算分離作為了主要目标,雖然目前 ClickHouse 已經支援把資料存儲到 S3 上,但這個實作還比較粗糙。未來 JuiceFS 也會與 ClickHouse 社群緊密合作共同探索存算分離的方向,讓 ClickHouse 更好地識别和支援共享存儲,實作叢集伸縮時不需要做任何資料拷貝。
其他:
Elasticsearch 存儲成本省 60%,稿定科技幹貨分享