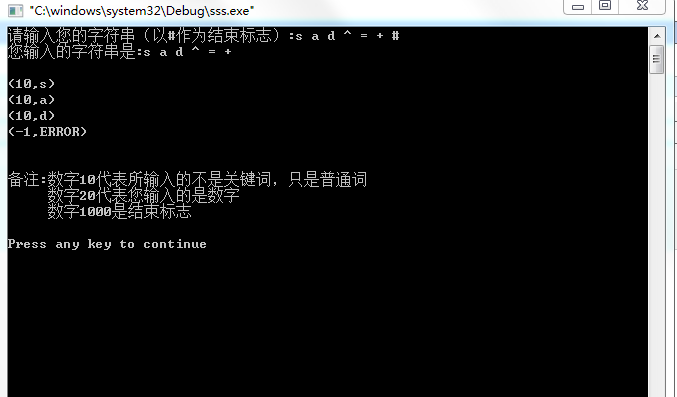
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#define _KEY_WOED_END "waiting for your expanding" //關鍵字結束标志
typedef
struct
{
int
typenum;
char
* word;
}
WORD
;
char
input[255];
//輸入換緩沖區
char
token[255]=
""
;
//單詞緩沖區
int
p_input;
//輸入換緩沖區指針
int
p_token;
//單詞緩沖區指針
char
ch;
//目前所讀的字元
char
*rwtab[]={
"begin"
,
"if"
,
"then"
,
"while"
,
"do"
,
"end"
,_KEY_WOED_END};
//C語言關鍵字
WORD
* scaner();
//詞法掃描函數,獲得關鍵字
main()
{
int
over=1;
WORD
*oneword;
oneword=(
WORD
*)
malloc
(
sizeof
(
WORD
));
printf
(
"請輸入您的字元串(以#作為結束标志):"
);
scanf
(
"%[^#]s"
,input);
//讀入源程式字元串到緩沖區,以#結束,允許多行輸入
p_input=0;
printf
(
"您輸入的字元串是:%s\n\n"
,input);
while
(over<1000&&over!=-1)
{
oneword=scaner();
printf
(
"(%d,%s)\n"
,oneword->typenum,oneword->word);
over=oneword->typenum;
}
printf
(
"\n\n備注:數字10代表所輸入的不是關鍵詞,隻是普通詞\n"
);
printf
(
" 數字20代表您輸入的是數字\n"
);
printf
(
" 數字1000是結束标志\n\n"
);
}
//需要用到的自編函數參考實作
//從輸入緩沖區讀取一個字元到ch中
char
m_getch(){
ch=input[p_input];
p_input=p_input+1;
return
(ch);
}
//去掉空白字元
void
getbc()
{
while
(ch==
' '
||ch==10){
ch=input[p_input];
p_input=p_input+1;
}
}
//拼接單詞
void
concat()
{
token[p_token]=ch;
p_token=p_token+1;
token[p_token]=
'\0'
;
}
//判斷是否字母
int
letter()
{
if
(ch>=
'a'
&&ch<=
'z'
||ch>=
'A'
&&ch<=
'Z'
)
return
1;
else
return
0;
}
//判斷是否數字
int
digit()
{
if
(ch>=
'0'
&&ch<=
'9'
)
return
1;
else
return
0;
}
//檢索關鍵字表格
int
reserve()
{
int
i=0;
for
(i=0;i<7;i++)
{
if
(!
strcmp
(rwtab[i],token))
{
return
i+1;
}
i=i+1;
}
return
10;
}
//回退一個字元
void
retract()
{
p_input=p_input-1;
}
WORD
*scaner()
{
WORD
*myword;
myword=(
WORD
*)
malloc
(
sizeof
(
WORD
));
myword->typenum=10;
myword->word=
""
;
p_token=0;
m_getch();
getbc();
if
(letter())
{
while
(letter()||digit())
{
concat();
m_getch();
}
retract();
myword->typenum=reserve();
myword->word=token;
return
(myword);
}
else
if
(digit())
{
while
(digit())
{
concat();
m_getch();
}
retract();
myword->typenum=20;
myword->word=token;
return
(myword);
}
else
{
switch
(ch)
{
case
'='
:m_getch();
if
(ch==
'='
)
{
myword->typenum=39;
myword->word=
"=="
;
return
(myword);
}
retract();
myword->typenum=21;
myword->word=
"="
;
return
(myword);
break
;
case
'+'
:
myword->typenum=22;
myword->word=
"+"
;
return
(myword);
break
;
case
'-'
:
myword->typenum=23;
myword->word=
"-"
;
return
(myword);
break
;
case
'*'
:
myword->typenum=24;
myword->word=
"*"
;
return
(myword);
break
;
case
'/'
:
myword->typenum=25;
myword->word=
"/"
;
return
(myword);
break
;
case
'('
:
myword->typenum=26;
myword->word=
"("
;
return
(myword);
break
;
case
')'
:
myword->typenum=27;
myword->word=
")"
;
return
(myword);
break
;
case
'['
:
myword->typenum=28;
myword->word=
"["
;
return
(myword);
break
;
case
']'
:
myword->typenum=29;
myword->word=
"]"
;
return
(myword);
break
;
case
'{'
:
myword->typenum=30;
myword->word=
"{"
;
return
(myword);
break
;
case
'}'
:
myword->typenum=31;
myword->word=
"}"
;
return
(myword);
break
;
case
','
:
myword->typenum=32;
myword->word=
","
;
return
(myword);
break
;
case
':'
:
myword->typenum=33;
myword->word=
":"
;
return
(myword);
break
;
case
';'
:
myword->typenum=34;
myword->word=
";"
;
return
(myword);
break
;
case
'>'
:
myword->typenum=35;
myword->word=
">"
;
return
(myword);
break
;
case
'<'
:
myword->typenum=36;
myword->word=
"<"
;
return
(myword);
break
;
case
'!'
:
m_getch();
if
(ch==
'='
)
{
myword->typenum=40;
myword->word=
"!="
;
return
(myword);
}
retract();
myword->typenum=-1;
myword->word=
"ERROR"
;
return
(myword);
break
;
case
'\0'
:
myword->typenum=1000;
myword->word=
"OVER"
;
return
(myword);
break
;
default
:
myword->typenum=-1;
myword->word=
"ERROR"
;
return
(myword);
}
}
}