面試開始,坐在我前面的就是這次我的面試官嗎?這發量看着根本不像程式員啊?我心裡正嘀咕着,隻聽見面試官說:“小夥,下午好,我今天就是你的面試官,咱們開始面試吧!”。
面試開始
面試官: 我也不用多說了,你先自我介紹一下吧,履歷上有的就不要再說了哈。
我: 内心 os:"果然如我所料,就知道會讓我先自我介紹一下,還好我看了 JavaGuide[1] ,學到了一些套路。套路總結起來就是:最好準備好兩份自我介紹,一份對 hr 說的,主要講能突出自己的經曆,會的程式設計技術一語帶過;另一份對技術面試官說的,主要講自己會的技術細節,項目經驗,經曆那些就一語帶過。 是以,我按照這個套路準備了一個還算通用的模闆,畢竟我懶嘛!不想多準備一個自我介紹,整個通用的多好!
面試官,您好!我叫小李子。大學時間我主要利用課外時間學習 Java 相關的知識。在校期間參與過一個某某系統的開發,主要負責資料庫設計和後端系統開發.,期間解決了什麼問題,巴拉巴拉。另外,我自己在學習過程中也參照網上的教程寫過一個電商系統的網站,寫這個電商網站主要是為了能讓自己接觸到分布式系統的開發。在學習之餘,我比較喜歡通過部落格整理分享自己所學知識。我現在已經是某社群的認證作者,寫過一系列關于 線程池使用以及源碼分析的文章深受好評。另外,我獲得過省級程式設計比賽二等獎,我将這個獲獎項目開源到 Github 還收獲了 2k 的 Star 呢?
面試官: 你剛剛說參考網上的教程做了一個電商系統?你能畫畫這個電商系統的架構圖嗎?
我: 内心 os: "這可難不倒我!早知道寫在履歷上的項目要重視了,提前都把這個系統的架構圖畫了好多遍了呢!"
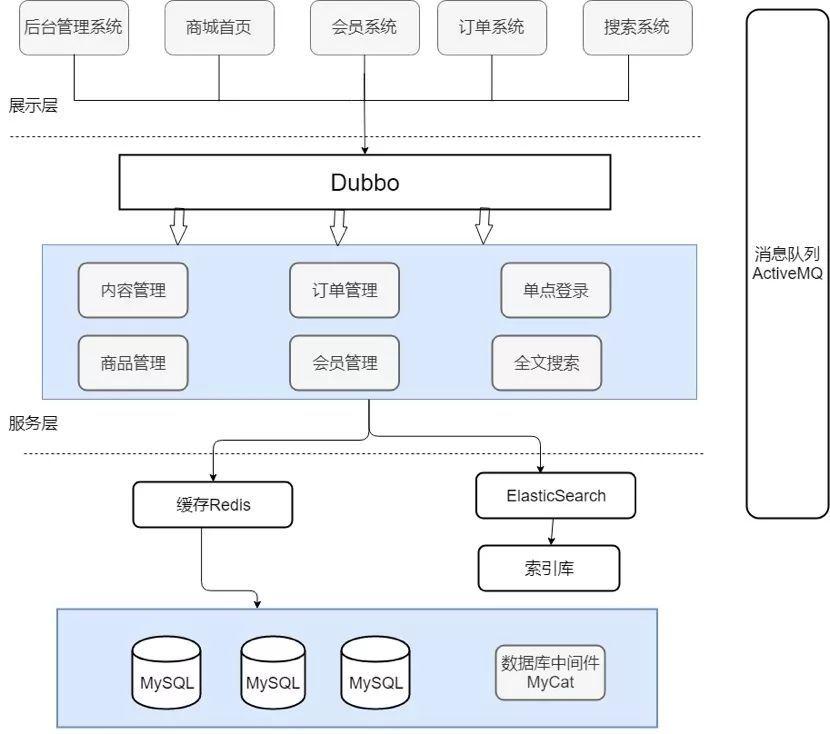
做過分布式電商系統的一定很熟悉上面的架構圖(目前比較流行的是微服務架構,但是如果你有分布式開發經驗也是非常加分的!)。
面試官: 簡單介紹一下你做的這個系統吧!
我: 我一本正經的對着我剛剛畫的商城架構圖開始了滿嘴造火箭的講起來:
本系統主要分為展示層、服務層和持久層這三層。表現層顧名思義主要就是為了用來展示,比如我們的背景管理系統的頁面、商城首頁的頁面、搜尋系統的頁面等等,這一層都隻是作為展示,并沒有提供任何服務。
展示層和服務層一般是部署在不同的機器上來提高并發量和擴充性,那麼展示層和服務層怎樣才能互動呢?在本系統中我們使用 Dubbo 來進行服務治理。Dubbo 是一款高性能、輕量級的開源 Java RPC 架構。Dubbo 在本系統的主要作用就是提供遠端 RPC 調用。在本系統中服務層的資訊通過 Dubbo 注冊給 ZooKeeper,表現層通過 Dubbo 去 ZooKeeper 中擷取服務的相關資訊。Zookeeper 的作用僅僅是存放提供服務的伺服器的位址和一些服務的相關資訊,實作 RPC 遠端調用功能的還是 Dubbo。如果需要引用到某個服務的時候,我們隻需要在配置檔案中配置相關資訊就可以在代碼中直接使用了,就像調用本地方法一樣。假如說某個服務的使用量增加時,我們隻用為這單個服務增加伺服器,而不需要為整個系統添加服務。
另外,本系統的資料庫使用的是常用的 MySQL,并且用到了資料庫中間件 MyCat。另外,本系統還用到 redis 記憶體資料庫來作為緩存來提高系統的反應速度。假如使用者第一次通路資料庫中的某些資料,這個過程會比較慢,因為是從硬碟上讀取的。将該使用者通路的資料存在數緩存中,這樣下一次再通路這些資料的時候就可以直接從緩存中擷取了。操作緩存就是直接操作記憶體,是以速度相當快。
系統還用到了 Elasticsearch 來提供搜尋功能。使用 Elasticsearch 我們可以非常友善的為我們的商城系統添加必備的搜尋功能,并且使用 Elasticsearch 還能提供其它非常實用的功能,并且很容易擴充。
面試官: 我看你的系統裡面還用到了消息隊列,能說說為什麼要用它嗎?
我:
使用消息隊列主要是為了:
- 減少響應所需時間和削峰。
- 降低系統耦合性(解耦/提升系統可擴充性)。
面試官: 你這說的太簡單了!能不能稍微詳細一點,最好能畫圖給我解釋一下。
我: 内心 os:"都 2019 年了,大部分面試者都能對消息隊列的為系統帶來的這兩個好處倒背如流了,如果你想走的更遠就要别别人懂的更深一點!"
當我們不使用消息隊列的時候,所有的使用者的請求會直接落到伺服器,然後通過資料庫或者緩存響應。假如在高并發的場景下,如果沒有緩存或者資料庫承受不了這麼大的壓力的話,就會造成響應速度緩慢,甚至造成資料庫當機。但是,在使用消息隊列之後,使用者的請求資料發送給了消息隊列之後就可以立即傳回,再由消息隊列的消費者程序從消息隊列中擷取資料,異步寫入資料庫,不過要確定消息不被重複消費還要考慮到消息丢失問題。由于消息隊列伺服器處理速度快于資料庫,是以響應速度得到大幅改善。
文字 is too 空洞,直接上圖吧!下圖展示了使用消息前後系統處理使用者請求的對比(ps:我自己都被我畫的這個圖美到了,如果你也覺得這張圖好看的話麻煩來個素質三連!)。

通過異步處理提高系統性能通過以上分析我們可以得出消息隊列具有很好的削峰作用的功能——即通過異步處理,将短時間高并發産生的事務消息存儲在消息隊列中,進而削平高峰期的并發事務。 舉例:在電子商務一些秒殺、促銷活動中,合理使用消息隊列可以有效抵禦促銷活動剛開始大量訂單湧入對系統的沖擊。如下圖所示:
削峰使用消息隊列還可以降低系統耦合性。我們知道如果子產品之間不存在直接調用,那麼新增子產品或者修改子產品就對其他子產品影響較小,這樣系統的可擴充性無疑更好一些。還是直接上圖吧:
解耦生産者(用戶端)發送消息到消息隊列中去,接受者(服務端)處理消息,需要消費的系統直接去消息隊列取消息進行消費即可而不需要和其他系統有耦合, 這顯然也提高了系統的擴充性。
面試官: 你覺得它有什麼缺點嗎?或者說怎麼考慮用不用消息隊列?
我: 内心 os: "面試官真雞賊!這不是勾引我上鈎麼?還好我準備充分。"
我覺得可以從下面幾個方面來說:
- 系統可用性降低: 系統可用性在某種程度上降低,為什麼這樣說呢?在加入 MQ 之前,你不用考慮消息丢失或者說 MQ 挂掉等等的情況,但是,引入 MQ 之後你就需要去考慮了!
- 系統複雜性提高: 加入 MQ 之後,你需要保證消息沒有被重複消費、處理消息丢失的情況、保證消息傳遞的順序性等等問題!
- 一緻性問題: 我上面講了消息隊列可以實作異步,消息隊列帶來的異步确實可以提高系統響應速度。但是,萬一消息的真正消費者并沒有正确消費消息怎麼辦?這樣就會導緻資料不一緻的情況了!
面試官:做項目的過程中遇到了什麼問題嗎?解決了嗎?如果解決的話是如何解決的呢?
我 :内心 os: "做的過程中好像也沒有遇到什麼問題啊!怎麼辦?怎麼辦?突然想到可以說我在使用 Redis 過程中遇到的問題,畢竟我對 Redis 還算熟悉嘛,把面試官往這個方向吸引,準沒錯。"
我在使用 Redis 對常用資料進行緩沖的過程中出現了緩存穿透問題。然後,我通過谷歌搜尋相關的解決方案來解決的。
面試官: 你還知道緩存穿透啊?不錯啊!來說說什麼是緩存穿透以及你最後的解決辦法。
我: 我先來談談什麼是緩存穿透吧!
緩存穿透說簡單點就是大量請求的 key 根本不存在于緩存中,導緻請求直接到了資料庫上,根本沒有經過緩存這一層。舉個例子:某個黑客故意制造我們緩存中不存在的 key 發起大量請求,導緻大量請求落到資料庫。
總結一下就是:
- 緩存層不命中。
- 存儲層不命中,不将空結果寫回緩存。
- 傳回空結果給用戶端。
一般 MySQL 預設的最大連接配接數在 150 左右,這個可以通過
show variables like '%max_connections%';
指令來檢視。最大連接配接數一個還隻是一個名額,cpu,記憶體,磁盤,網絡等實體條件都是其運作名額,這些名額都會限制其并發能力!是以,一般 3000 的并發請求就能打死大部分資料庫了。
面試官: 小夥子不錯啊!還準備問你:“為什麼 3000 的并發能把支援最大連接配接數 4000 資料庫壓死?”想不到你自己就提前回答了!不錯!
我: 别誇了!别誇了!我再來說說我知道的一些解決辦法以及我最後采用的方案吧!您幫忙看看有沒有問題。
最基本的就是首先做好參數校驗,一些不合法的參數請求直接抛出異常資訊傳回給用戶端。比如查詢的資料庫 id 不能小于 0、傳入的郵箱格式不對的時候直接傳回錯誤消息給用戶端等等。
參數校驗通過的情況還是會出現緩存穿透,我們還可以通過以下幾個方案來解決這個問題:
1)緩存無效 key : 如果緩存和資料庫都查不到某個 key 的資料就寫一個到 redis 中去并設定過期時間,具體指令如下:
SET key value EX 10086
。這種方式可以解決請求的 key 變化不頻繁的情況,如何黑客惡意攻擊,每次建構的不同的請求 key,會導緻 redis 中緩存大量無效的 key 。很明顯,這種方案并不能從根本上解決此問題。如果非要用這種方式來解決穿透問題的話,盡量将無效的 key 的過期時間設定短一點比如 1 分鐘。
另外,這裡多說一嘴,一般情況下我們是這樣設計 key 的:
表名:列名:主鍵名:主鍵值
。
2)布隆過濾器: 布隆過濾器是一個非常神奇的資料結構,通過它我們可以非常友善地判斷一個給定資料是否存在于海量資料中。我們需要的就是判斷 key 是否合法,有沒有感覺布隆過濾器就是我們想要找的那個“人”。
面試官: 不錯不錯!你還知道布隆過濾器啊!來給我談一談。
我: 内心 os:“如果你準備過海量資料處理的面試題,你一定對:“如何确定一個數字是否在于包含大量數字的數字集中(數字集很大,5 億以上!)?”這個題目很了解了!解決這道題目就要用到布隆過濾器。”
布隆過濾器在針對海量資料去重或者驗證資料合法性的時候非常有用。布隆過濾器的本質實際上是 “位(bit)數組”,也就是說每一個存入布隆過濾器的資料都隻占一位。相比于我們平時常用的的 List、Map 、Set 等資料結構,它占用空間更少并且效率更高,但是缺點是其傳回的結果是機率性的,而不是非常準确的。
當一個元素加入布隆過濾器中的時候,會進行如下操作:
- 使用布隆過濾器中的哈希函數對元素值進行計算,得到哈希值(有幾個哈希函數得到幾個哈希值)。
- 根據得到的哈希值,在位數組中把對應下标的值置為 1。
當我們需要判斷一個元素是否存在于布隆過濾器的時候,會進行如下操作:
- 對給定元素再次進行相同的哈希計算;
- 得到值之後判斷位數組中的每個元素是否都為 1,如果值都為 1,那麼說明這個值在布隆過濾器中,如果存在一個值不為 1,說明該元素不在布隆過濾器中。
舉個簡單的例子:
布隆過濾器hash計算如圖所示,當字元串存儲要加入到布隆過濾器中時,該字元串首先由多個哈希函數生成不同的哈希值,然後在對應的位數組的下表的元素設定為 1(當位數組初始化時 ,所有位置均為 0)。當第二次存儲相同字元串時,因為先前的對應位置已設定為 1,是以很容易知道此值已經存在(去重非常友善)。
如果我們需要判斷某個字元串是否在布隆過濾器中時,隻需要對給定字元串再次進行相同的哈希計算,得到值之後判斷位數組中的每個元素是否都為 1,如果值都為 1,那麼說明這個值在布隆過濾器中,如果存在一個值不為 1,說明該元素不在布隆過濾器中。
不同的字元串可能哈希出來的位置相同,這種情況我們可以适當增加位數組大小或者調整我們的哈希函數。
綜上,我們可以得出:布隆過濾器說某個元素存在,小機率會誤判。布隆過濾器說某個元素不在,那麼這個元素一定不在。
面試官: 看來你對布隆過濾器了解的還挺不錯的嘛!那你快說說你最後是怎麼利用它來解決緩存穿透的。
我: 知道了布隆過濾器的原理就之後就很容易做了。我是利用 Redis 布隆過濾器來做的。我把所有可能存在的請求的值都存放在布隆過濾器中,當使用者請求過來,我會先判斷使用者發來的請求的值是否存在于布隆過濾器中。不存在的話,直接傳回請求參數錯誤資訊給用戶端,存在的話才會走下面的流程。總結一下就是下面這張圖(這張圖檔不是我畫的,為了省事直接在網上找的):
更多關于布隆過濾器的内容可以看我的這篇原創:《不了解布隆過濾器?一文給你整的明明白白!》[2] ,強烈推薦,個人感覺網上應該找不到總結的這麼明明白白的文章了。
面試官: 好了好了。項目就暫時問到這裡吧!下面有一些比較基礎的問題我簡單地問一下你。内心 os:難不成這家夥滿口高并發,連最基礎的東西都不會吧!
我: 好的好的!沒問題!
面試官: 浏覽器輸入 URL 發生了什麼?
我: 内心 os:“很常問的一個問題,建議拿小本本記好了!另外,百度好像最喜歡問這個問題,去百度面試可要提前備好這道題的功課哦!相似問題:打開一個網頁,整個過程會使用哪些協定?”。
圖解(圖檔來源:《圖解 HTTP》):
總體來說分為以下幾個過程:
- DNS 解析
- TCP 連接配接
- 發送 HTTP 請求
- 伺服器處理請求并傳回 HTTP 封包
- 浏覽器解析渲染頁面
- 連接配接結束
具體可以參考下面這篇文章:
- https://segmentfault.com/a/1190000006879700[3]
面試官: TCP 和 UDP 差別?
TCP、UDP協定的差別UDP 在傳送資料之前不需要先建立連接配接,遠地主機在收到 UDP 封包後,不需要給出任何确認。雖然 UDP 不提供可靠傳遞,但在某些情況下 UDP 确是一種最有效的工作方式(一般用于即時通信),比如:QQ 語音、 QQ 視訊 、直播等等
TCP 提供面向連接配接的服務。在傳送資料之前必須先建立連接配接,資料傳送結束後要釋放連接配接。TCP 不提供廣播或多點傳播服務。由于 TCP 要提供可靠的,面向連接配接的傳輸服務(TCP 的可靠展現在 TCP 在傳遞資料之前,會有三次握手來建立連接配接,而且在資料傳遞時,有确認、視窗、重傳、擁塞控制機制,在資料傳完後,還會斷開連接配接用來節約系統資源),這一難以避免增加了許多開銷,如确認,流量控制,計時器以及連接配接管理等。這不僅使協定資料單元的首部增大很多,還要占用許多處理機資源。TCP 一般用于檔案傳輸、發送和接收郵件、遠端登入等場景。
面試官: TCP 如何保證傳輸可靠性?
- 應用資料被分割成 TCP 認為最适合發送的資料塊。
- TCP 給發送的每一個包進行編号,接收方對資料包進行排序,把有序資料傳送給應用層。
- 校驗和: TCP 将保持它首部和資料的檢驗和。這是一個端到端的檢驗和,目的是檢測資料在傳輸過程中的任何變化。如果收到段的檢驗和有差錯,TCP 将丢棄這個封包段和不确認收到此封包段。
- TCP 的接收端會丢棄重複的資料。
- 流量控制: TCP 連接配接的每一方都有固定大小的緩沖空間,TCP 的接收端隻允許發送端發送接收端緩沖區能接納的資料。當接收方來不及處理發送方的資料,能提示發送方降低發送的速率,防止包丢失。TCP 使用的流量控制協定是可變大小的滑動視窗協定。(TCP 利用滑動視窗實作流量控制)
- 擁塞控制: 當網絡擁塞時,減少資料的發送。
- ARQ 協定: 也是為了實作可靠傳輸的,它的基本原理就是每發完一個分組就停止發送,等待對方确認。在收到确認後再發下一個分組。
- 逾時重傳: 當 TCP 發出一個段後,它啟動一個定時器,等待目的端确認收到這個封包段。如果不能及時收到一個确認,将重發這個封包段。
面試官: 我再來問你一些 Java 基礎的問題吧!小夥子。
我: 好的。(内心 os:“你盡管來!”)
面試官: 既然有了位元組流,為什麼還要有字元流?
我:内心 os :“問題本質想問:不管是檔案讀寫還是網絡發送接收,資訊的最小存儲單元都是位元組,那為什麼 I/O 流操作要分為位元組流操作和字元流操作呢?”
字元流是由 Java 虛拟機将位元組轉換得到的,問題就出在這個過程還算是非常耗時,并且,如果我們不知道編碼類型就很容易出現亂碼問題。是以, I/O 流就幹脆提供了一個直接操作字元的接口,友善我們平時對字元進行流操作。如果音頻檔案、圖檔等媒體檔案用位元組流比較好,如果涉及到字元的話使用字元流比較好。
面試官:深拷貝 和 淺拷貝有啥差別呢?
- 淺拷貝:對基本資料類型進行值傳遞,對引用資料類型進行引用傳遞般的拷貝,此為淺拷貝。
- 深拷貝:對基本資料類型進行值傳遞,對引用資料類型,建立一個新的對象,并複制其内容,此為深拷貝。
deep and shallow copy
面試官: 好的!面試結束。小夥子可以的!回家等通知吧!
我: 好的好的!辛苦您了!
https://cloud.tencent.com/developer/article/1624586