當我們在浏覽器上點開一個網頁時,我們的用戶端就會和伺服器建立一個socket連接配接。Soket是什麼,什麼是Socket 五元組,常見的TCP優化參數的依據又是什麼,這裡我們将來分析一下。
Socket 五元組
我們通常所說的五元組就是我們熟悉的 源IP,源端口,目的IP,目的端口和協定組成。以http協定為例,當我們通路網站時,使用三層協定的是TCP協定,源IP為本地電腦的IP,源端口為随機端口,目的IP為網站所在伺服器IP,目的端口為80。
下圖是TCP資料的封裝結構:
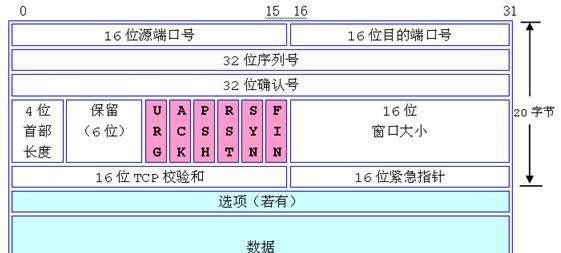
tcp的源端口和目的端口都占用16bit,也就是2的16次方,這樣一共可用的端口就是65536個,端口号是從0開始,而且0是保留端口(使用0端口配置設定一個随機端口),實際可用的端口範圍是1-65535,Unix系統中的保留端口是0-1024,在1024以内的端口都需要超級使用者特權才能啟用。
優化端口範圍
在我們的系統中,有很多保留的端口,如http的80,ftp的20,21,ssh的22等等,這些端口都是特定協定的特定端口。當我們從本機通路伺服器時,系統會随機配置設定一個端口,在linux系統中這個随機端口的範圍預設是 32768到61000,可以通過如下指令檢視:
# cat /proc/sys/net/ipv4/ip_local_port_range
32768 61000 當然,我們可以通過優化主機的端口範圍來提高并發系統的并發能力,這個一般配置在我們的代理伺服器和需要向其他主機發起請求的主機上,如web伺服器等。在指定端口範圍的時候,我們需要将10000以下的端口保留,很多服務預設會使用10000以内的端口。
# echo "10000 65535" > /proc/sys/net/ipv4/ip_local_port_range 由于Linux系統中,一切皆檔案,在系統發起一個socket連接配接的時候會自動建立一個socket檔案,如果同時有很多個socket請求,本地的Openfile數量就會是一個瓶頸,下面我們看一下Linux系統預設的open-file參數:
# ulimit -n
1024 預設的open files數量遠遠低于我們的随機端口數量,我們需要修改open files參數:
vim /etc/security/limits.conf
* soft nofile 50000 # soft表示為預設的限制範圍,可以超過,但是最大不能超過hard中的配置
* hard nofile 60000 # hard表示不能超過此範圍 這裡指定了所有使用者,如果是對特定使用者或者使用者組可以将'*'替換為使用者名。
提示:使用ulimit -n 60000這條指令,隻是在目前的shell生效。普通使用者使用此指令不能超過hard nofile中的設定值,且使用之後,隻能縮小,不能增大。root使用者可任意設定,不受限制。
由于系統支援的端口範圍有限,是以在有些高并發的場景,即使優化了端口範圍也會是一個瓶頸,是以在這種場景下,一般使用多IP的方式來實作。
TCP三向交握四次揮手
這裡既然提到了TCP協定,就不得不說下TCP的三次握手和四次揮手。附圖:

在描述這個流程圖前,結合上面的TCP報頭結構,可以更加容易了解這個過程:
簡單的描述下這個流程圖(結合上面的三張圖了解):
三次握手
1、在起始點服務端和用戶端都是無應用狀态,沒有TCP連接配接.
2、用戶端有應用需要發起TCP連接配接,此時向服務端發送SYN的TCP連接配接請求,并将自身狀态轉換為SYN_SENT。此處的SYN資訊儲存在TCP報頭的32位序列号中(圖3,SEQ No),Code Bits區域的SYN位設定為1(圖1)。
3、服務端服務啟動後,進入LISTEN狀态,當服務端收到用戶端發來的SYN後,立即回複一個新的SYN序列号,同時帶上ACK,ACK也是一個32bits的序列号(圖3,ACK No),并且是在用戶端發送的SYN序列号上+1,Code Bits區域的SYN位和ACK位都設定為1。服務端進入SYN_RCVD狀态。
4、用戶端接收到服務端發送的SYN,ACK報之後,會回複服務端一個ACK,此時ACK辨別位置為1,用戶端進入ESTABLISHED狀态。
5、服務端接受ACK後進入ESTABLISHED狀态。
四次揮手
1、當要斷開連接配接時(我們将發起斷開請求的一端稱作用戶端),用戶端會向服務端發送一個FIN,然後自身轉變為FIN_WAIT_1狀态。
2、服務端接受FIN後,傳回一個ACK,然後進入CLOSE_WAIT狀态。
3、用戶端接收到服務端的ACK後,進入FIN_WAIT_2狀态。
4、服務端完成資料傳輸後,會向用戶端發送一個FIN,然後進入LAST_ACK。
5、用戶端接收FIN後,向服務端發送ACK,進入TIME_WAIT狀态。
6、服務端接受ACK後關閉程序,進入close狀态。
通過nc 指令,使用本機telnet 觀察整個過程
1、主機A啟用端口8888,并使用tcpdump 監聽此端口
[root@zabbixsvr ~]# nc -l -4 -p 8888 -k [root@zabbixsvr ~]# tcpdump -i ens3 host 192.168.1.17 and port 8888 2、本地主機B,IP為192.168.1.17,使用telnet遠端通路此端口:
C:\Users\admin>telnet 192.168.1.100 8888 此時主機上的TCP狀态為ESTABLISHED:
[root@zabbixsvr ~]# netstat -alntpu|grep 8888
tcp 0 0 0.0.0.0:8888 0.0.0.0:* LISTEN 5019/nc
tcp 0 0 192.168.1.100:8888 192.168.1.17:63633 ESTABLISHED 5019/nc 3、之後主機A主動斷開連接配接,此時主機A上的TCP狀态為TIME_WAIT:
[root@zabbixsvr ~]# netstat -alntpu|grep 8888
tcp 0 0 192.168.1.100:8888 192.168.1.17:63633 TIME_WAIT - TIME_WAIT狀态會持續60s的時間。
4、整個過程由于沒有資料的發送,是以tcpdump捕獲到的資訊剛好是一個tcp 三次握手和四次揮手過程:
11:06:39.833871 IP 192.168.1.17.63633 > zabbixsvr.ddi-tcp-1: Flags [S], seq 1288094251, win 8192, options [mss 1460,nop,wscale 8,nop,nop,sackOK], length 0
11:06:39.833978 IP zabbixsvr.ddi-tcp-1 > 192.168.1.17.63633: Flags [S.], seq 204052783, ack 1288094252, win 29200, options [mss 1460,nop,nop,sackOK,nop,wscale 7], length 0
11:06:39.834352 IP 192.168.1.17.63633 > zabbixsvr.ddi-tcp-1: Flags [.], ack 1, win 256, length 0
11:07:03.335179 IP zabbixsvr.ddi-tcp-1 > 192.168.1.17.63633: Flags [F.], seq 1, ack 1, win 229, length 0
11:07:03.335702 IP 192.168.1.17.63633 > zabbixsvr.ddi-tcp-1: Flags [.], ack 2, win 256, length 0
11:07:03.337265 IP 192.168.1.17.63633 > zabbixsvr.ddi-tcp-1: Flags [F.], seq 1, ack 2, win 256, length 0
11:07:03.337347 IP zabbixsvr.ddi-tcp-1 > 192.168.1.17.63633: Flags [.], ack 2, win 229, length 0 TCP連接配接優化
由上面的分析,我們可以得出一個結論:time-wait會發生在發起斷開請求的一端。一般這樣的伺服器會是我們的代理節點或web伺服器,因為他們需要作為用戶端向後端節點發起通路。而系統進入time-wait後會等待60s的時間,在這段時間内,系統不會釋放socket,仍然會占據端口,這樣對于高并發的業務非常不利。
對此我們就需要對處于time-wait狀态的socket進行快速回收。
time-wait調優:減少time-wait
優化參數:
/proc/sys/net/ipv4/tcp_tw_reuse # 盡量複用連接配接 /proc/sys/net/ipv4/tcp_timestamps # 開啟時間戳,預設是開開啟狀态。 /proc/sys/net/ipv4/tcp_tw_recycle # time-wait快速回收,開啟必須開啟tcp_timestamps。 使用NAT網絡環境下不能開啟,會造成SYN資料包被丢棄,
負載均衡上不能開,否則會出現收不到資料包的情況。 提示:如果關閉tcp_timestamp, tcp_tw_recycle則不能開啟。
參數說明:
預設情況下,當tcp_tw_reuse和tcp_tw_recycle都被禁用時,核心将確定在TIME_WAIT狀态下的套接字将保持在足夠長的時間,這足以確定屬于未來連接配接的資料包不會被誤認為是舊的連接配接。
tcp_tw_reuse:
當啟用tcp_tw_reuse時,在TIME_WAIT狀态下的套接字可以在它們過期之前使用,并且核心将嘗試確定沒有關于TCP序列号的沖突。如果啟用tcp_timestamps(a.k.a. PAWS,防止包裝序列号),它将確定這些沖突不會發生。但是,需要在伺服器兩端都啟用TCP時間戳。
tcp_tw_recycle:
啟用tcp_tw_recycle時,核心變得更加積極回收time wait,并且将對遠端主機使用的時間戳作出假設判斷。它将跟蹤具有TIME_WAIT狀态的連接配接的每個遠端主機使用的最後時間戳),并允許在時間戳正确增加的情況下重新使用套接字。但是,如果主機使用的時間戳發生變化(即時間回退),則SYN資料包将被靜默地丢棄,并且連接配接不會建立(您将看到類似于“連接配接逾時”的錯誤)。
在開啟tcp_tw_recycle連接配接中間涉及網絡位址轉換(或智能防火牆)的場景就會出現這種情況:
在這種情況下,擁有相同IP位址後面有多個主機,是以,不同的時間戳序列(或者所有時間戳在防火牆的每個連接配接處被随機化)。在這種情況下,某些主機将無法連接配接,因為它們映射到伺服器的TIME_WAIT桶具有較新的時間戳的端口。這就是為什麼有些文檔告訴你“NAT裝置或負載均衡器可能由于設定而啟動丢幀”。
這裡建議不開啟tcp_tw_recycle,但是啟用tcp_tw_reuse并降低tcp_timewait_len。
除此之外我們還可以使用長連接配接的方式,減少time-wait。
長連接配接的優缺點:
1、長連接配接會長時間占用socket。
2、長連接配接會加快通路速度。
Nginx TCP配置優化
在nginx的配置檔案中有相關TCP連接配接的優化,分别是sendfile,tcp_nopush和tcp_nodelay。
sendfile on|off; # 是否啟用檔案快速傳輸
tcp_nopush on|off; # 是否緩存資料後集中發送,适用于大檔案傳輸
tcp_nodelay on|off; # 是否立即發送資料包,使用于即時性傳輸 當使用sendfile函數時,tcp_nopush才起作用,它和指令tcp_nodelay是互斥的。
為了避免網絡擁塞,使用TCP協定發送資料時,有等待資料達到MSS值之後再發生資料的機制,是以不會發送太小的資料包。 這種機制由Nagle的算法保證,其算法邏輯是這樣:
if there is new data to send
if the window size >= MSS and available data is >= MSS
send complete MSS segment now
else
if there is unconfirmed data still in the pipe
enqueue data in the buffer until an acknowledge is received
else
send data immediately
end if
end if
end if 該算法與TCP延遲确認機制(TCP delayed acknowledgment)在20世紀80年代早期引入到TCP中。啟用這兩種算法後,應用程式對TCP連接配接進行兩次連續寫入,其次是在第二次寫入的資料到達目的地之後将不會立即發送,在另一端會經曆長達500毫秒的恒定延遲,就是所謂的“ ACK延遲(delay ACK預設會延遲40ms回複,其作用也是給發送資料的一端更多的時間來緩沖更多的資料)“。 是以,TCP實作通常為應用程式提供禁用Nagle算法的接口。 這個就是TCP_NODELAY選項。
tcp_nodelay :
TCP_NODELAY選項允許繞過Naggle算法,然後盡快發送資料。當下載下傳完整的網頁時,TCP_NODELAY可以在每個HTTP請求上節省更多的時間,這樣可以有更佳的使用者體驗。 在線上遊戲或高頻交易時的場景,即使以相對網絡飽和的代價,擺脫延遲至關重要。
Nginx在HTTP keepalive連接配接上使用TCP_NODELAY。 keepalive連接配接是在發送資料後保持打開幾次的套接字。 keepalive允許發送更多的資料,而不會啟動新的連接配接,并重複每次HTTP請求的TCP 3次握手方式。 這樣可以節省重新建立socket的時間,因為每次資料傳輸後都不會切換到FIN_WAIT。 Keep-alive是HTTP 1.0和HTTP 1.1預設行為的一個選項。
tcp_nopush :
在Nginx上,配置選項tcp_nopush與tcp_nodelay相反。 不是優化延遲,但是它可以優化一次發送的資料量,和Nagle算法非常接近。
TCP_NOPUSH會調用tcp_cork函數,tcp_cork函數會阻塞資料,直到資料包到達MSS的長度,MSS長度等于MTU減去IP資料包的40(IPV4)或60(IPV6)位元組,和Nagle算法不同的是,TCP_CORK軟體将等待的時間上限設定為200毫秒,而不是等待上個資料包的ACK。 如果達到上限,則排隊的資料将自動傳輸。
TCP(7)聯機幫助頁解釋說TCP_NODELAY和TCP_CORK是互斥的,但是Linux 2.5.9以後的版本中兩者可以相容。
在Nginx的配置中,sendfile和tcp_nopush必須配合使用。
sendfile :
Nginx之是以在靜态檔案的傳輸上有很高的性能,主要原因就在于這裡所說的三個參數。
Nginx的sendfile選項可以使用sendfile(2)來處理與發送檔案相關的所有内容。
sendfile(2)允許在檔案描述符中直接在核心空間中傳輸資料,節省大量資源:
- sendfile是一個系統調用,這意味着在核心空間内執行,是以沒有昂貴的上下文切換。
- 替換了read和write兩者的組合。
- 允許零拷貝,這意味着通過DMA從塊裝置記憶體直接寫入核心緩沖區。
如果nginx是在為本地存儲的靜态檔案提供服務,則sendfile對于加快Web伺服器響應至關重要。 但是,如果使用Nginx作為反向代理來從應用程式伺服器提供頁面,則可以禁用它。 除非在tmpfs上提供微型緩存。
三個參數同時開啟:
之前提到,tcp_nodelay和tcp_nopush 是一對互斥的參數,那麼這裡同時開啟會帶來什麼效果呢?
當開啟sendfile,tcp_nopush時,可以確定在發送到用戶端之前資料包已經充分“填滿”, 這大大減少了網絡開銷,并加快了檔案發送的速度。 然後,當它到達最後一個可能因為沒有“填滿”而暫停的資料包時,Nginx會忽略tcp_nopush參數, 然後,tcp_nodelay強制套接字發送資料,每個檔案節200ms的時間。
這個運作過程可以從TCP_CORK相關的TCP stack 源碼中得到确認 a comment from the TCP stack source,引用源碼注釋中的原話:
/* When set indicates to always queue non-full frames.
* Later the user clears this option and we transmit
* any pending partial frames in the queue. This is
* meant to be used alongside sendfile() to get properly
* filled frames when the user (for example) must write
* out headers with a write() call first and then use
* sendfile to send out the data parts.
*
* TCP_CORK can be set together with TCP_NODELAY and it is
* stronger than TCP_NODELAY.
*/ 由此可知,TCP_CORK可以與TCP_NODELAY一起設定,它比單獨配置TCP_NODELAY具有更強的性能。
參考連結:
https://www.unixhot.com/article/65
https://stackoverflow.com/questions/8893888/dropping-of-connections-with-tcp-tw-recycle