軟工實踐結對第二次作業
github連結
作業連結
隊友陳曉彬
具體分工
-
陳曉彬
負責從CVPR網站爬取論文資料
-
陳璟
負責對論文資料進行分析
PSP表格
| PSP2.1 | Personal Software Process Stages | 預估耗時(分鐘) | 實際耗時(分鐘) |
| Planning | 計劃 | 30 | 40 |
| • Estimate | • 估計這個任務需要多少時間 | ||
| Development | 開發 | 230 | 290 |
| • Analysis | • 需求分析 (包括學習新技術) | 20 | |
| • Design Spec | • 生成設計文檔 | ||
| • Design Review | • 設計複審 | 10 | |
| • Coding Standard | • 代碼規範 (為目前的開發制定合适的規範) | ||
| • Design | • 具體設計 | ||
| • Coding | • 具體編碼 | 120 | 150 |
| • Code Review | • 代碼複審 | ||
| • Test | • 測試(自我測試,修改代碼,送出修改) | ||
| Reporting | 報告 | 15 | |
| • Test Repor | • 測試報告 | ||
| • Size Measurement | • 計算工作量 | 5 | |
| • Postmortem & Process Improvement Plan | • 事後總結, 并提出過程改進計劃 | ||
| 合計 | 275 | 350 |
解題思路描述與設計實作說明
-
爬蟲使用
我們通路某一個網頁的時候,在位址欄輸入網址,按回車,該網站的伺服器就會傳回一個HTML檔案給我們,浏覽器解析傳回的資料,展示在UI上。同樣爬蟲程式也是模仿人的操作,給網站發送一個請求,網站會給爬蟲程式傳回一個HTML檔案,爬蟲程式再根據傳回的資料進行抓取分析 。
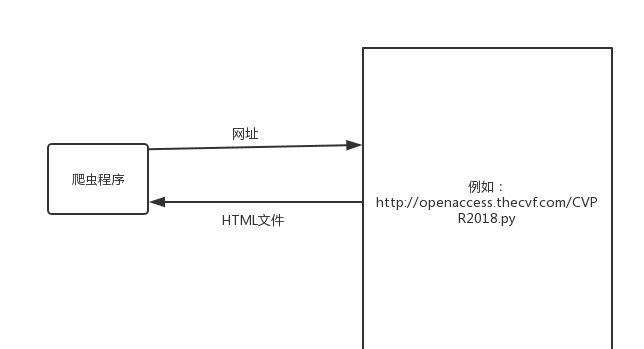
Jsoup是一款Java 的HTML解析器,可直接解析某個URL位址、HTML文本内容。可通過DOM,CSS以及類似于jQuery的操作方法來取出和操作資料。首先Jsoup從一個URL,檔案或字元串解析HTML,然後使用DOM或者CSS選擇器來查找,取出資料。
-
代碼組織與内部實作設計(類圖)
代碼分為兩塊,一塊為
Main
,這裡是存放主函數的地方,負責對參數進行分析,對另一個類進行調用來分析文本以及輸出結果,另一個是文本分析類
FileParser
,這個類按照
Main
給出的參數對文本進行分析,将分析出的詞組或單詞存放在一個map中,之後輸出就可以用這個map中的資料進行輸出

-
說明算法的關鍵與關鍵實作部分流程圖
算法的關鍵在于對文本的分析,将其分為若幹的詞組。算法的關鍵在于狀态的改變,可以吧本次作業了解成一個自動機,顯而易見的是本次作業的輸入檔案是由論文編号和Title和Abstract組成的,其中Title和Abstract内容為一行字元串(這是觀察發現的,如果不是就GG了),其中每行字元串可以了解為若幹個字母數字組成的串以及若幹個非字母數字組成的串交叉構成的,是以我設定了以下狀态。
- 讀取論文編号階段
-
1
讀取"Title: "階段
-
2
讀取Title中非字母數字串階段
-
3
讀取Title中字母數字串階段
-
4
讀取"Abstract: "階段
- 讀取Abstract中非字母數字串階段
-
6
讀取Abstract中字母數字串階段
-
7
讀取論文間兩空格階段
流程圖如下所示
附加題設計與展示
-
設計的創意獨到之處
-
實作思路
-
實作成果展示
關鍵代碼解釋
while((ch=br.read())!=-1) {
if(ch>255)continue;
//編号
if(state==0) {
if(isDigit(ch)) {
temp.append((char)ch);
}
else {
int no=Integer.parseInt(temp.toString());
//System.out.println(no);
line=(no+1)*2;
state=1;
temp.setLength(0);
}
}
//讀取Title:
else if(state==1) {
if(ch==' ') {
cizu.setLength(0);
del.clear();
state=2;
start=false;
temp.setLength(0);
}
}
//非字母數字
else if(state==2) {
charNum++;
if(ch=='\n') {
//under windows , delete the '\t'
charNum--;
state=4;
}
if(isLetter(ch)||isDigit(ch)) {
if(m>1&&start) {
cizu.append(temp.toString());
del.offer(temp.length());
}
temp.setLength(0);
isWord=true;
pos=0;
state=3;
if(isDigit(ch)) {
isWord=false;
}
if(ch>='A'&&ch<='Z') {
ch-='A'-'a';
}
}
temp.append((char)ch);
}
//字母數字
else if(state==3) {
charNum++;
if(ch>='A'&&ch<='Z') {
ch-='A'-'a';
}
if(ch=='\n') {
charNum--;
state=4;
}
if((!isLetter(ch)&&!isDigit(ch))) {
//not a word ,clear the cizu and del
if(!isWord||temp.length()<4) {
cizu.setLength(0);
del.clear();
}
//add word,if the queue is reach m,then add to map
else {
wordNum++;
start=true;
//add this word
cizu.append(temp.toString());
//add this size
del.offer(temp.length());
if(del.size()==m*2-1) {
if(mp.containsKey(cizu.toString())) {
int val=mp.get(cizu.toString())+val1;
mp.put(cizu.toString(), val);
}
else {
mp.put(cizu.toString(), val1);
}
int size=del.poll();
if(m>1) {
size+=del.poll();
}
cizu.delete(0, size);
}
}
if(state==4) {
}
else {
temp.setLength(0);
state=2;
}
}
temp.append((char)ch);
if(pos<4&&isDigit(ch)) {
isWord=false;
}
pos++;
}
//讀取Abstract:
else if(state==4) {
if(ch==' ') {
cizu.setLength(0);
del.clear();
temp.setLength(0);
state=5;
start=false;
space=0;
}
}
//非字母數字
else if(state==5) {
charNum++;
if(ch=='\n') {
//under windows , delete the '\t'
charNum--;
state=7;
}
if(isLetter(ch)||isDigit(ch)) {
if(m>1&&start) {
cizu.append(temp.toString());
del.offer(temp.length());
}
temp.setLength(0);;
isWord=true;
pos=0;
state=6;
if(isDigit(ch)) {
isWord=false;
}
if(ch>='A'&&ch<='Z') {
ch-='A'-'a';
}
}
temp.append((char)ch);
}
//字母數字
else if(state==6) {
charNum++;
if(ch>='A'&&ch<='Z') {
ch-='A'-'a';
}
if(ch=='\n') {
charNum--;
state=7;
}
if((!isLetter(ch)&&!isDigit(ch))) {
//not a word ,clear the cizu and del
if(!isWord||temp.length()<4) {
cizu.setLength(0);
del.clear();
}
//add word,if the queue is reach m,then add to map
else {
wordNum++;
start=true;
//add this word
cizu.append(temp.toString());
//add this size
del.offer(temp.length());
if(del.size()==m*2-1) {
if(mp.containsKey(cizu.toString())) {
int val=mp.get(cizu.toString())+val2;
mp.put(cizu.toString(), val);
}
else {
mp.put(cizu.toString(), val2);
}
int size=del.poll();
if(m>1) {
size+=del.poll();
}
cizu.delete(0, size);
}
}
if(state==7) {
}
else {
temp.setLength(0);
state=5;
}
}
temp.append((char)ch);
if(pos<4&&isDigit(ch)) {
isWord=false;
}
pos++;
}
//行間兩空行
else if(state==7) {
if(ch=='\n') {
space++;
}
if(space==2) {
state=0;
temp.setLength(0);
}
}
}
性能分析與改進
在本次作業中基本上沒有在整體完成之後的大幅度性能改進,在編碼過程中就有做一些性能上的調優,我是使用Java來實作本次作業的,比如說檔案讀入時我用的通過BufferedReader包裝的FileReader而不是使用InputFIleStream,是因為使用具有緩沖區的BufferedReadder讀取更快,在本次得到的論文清單測試中有肉眼可以見的進步,其次是将map的實作由TreeMap改為HashMap,TreeMap的内部實作為二叉樹,而HashMap 的内部實作為哈希表,顯而易見HashMap 的插入和查詢的時間複雜度是要比TreeMap更優的。
本次程式的耗費時間較短,暫不需要性能優化
單元測試
public class FileParserTest {
public FileParser fp=new FileParser();
@Test
public void testParser() {
File file=new File("d://1.txt");
FileReader fr;
try {
fr = new FileReader(file);
fp.Parser(fr, 1, 1);
assertEquals(fp.getCharNum(),39);
assertEquals(fp.getLine(), 6);
assertEquals(fp.getWordNum(), 10);
} catch (FileNotFoundException e) {
e.printStackTrace();
}
}
}
因為在一個函數中就把所有事都做了,是以構造了一個測試文本簡單測試了一下
Github代碼簽入記錄
本人代碼是一次寫完的,是以并沒有很多的簽入記錄
遇到的代碼子產品異常及解決方法
雖然是一次寫完的,但其實還是有遇到一些錯誤,由于很久沒有用java來寫東西是以放了一個比較低級的錯誤,那就是在輸出檔案時,不管我怎麼調用
write
方法,但輸出檔案雖然被建立了,裡面卻沒有任何内容,後來才發現
FileWriter
在輸出時是先輸出到緩沖區的,而我沒有執行
File
的
close
方法,是以緩沖區的内容沒有被重新整理到檔案中,後來在全部輸出完成後加了
fflush
方法就解決了
評價你的隊友
隊友還是非常牢靠的
學習進度條
| 第n周 | 新增代碼行 | 本周學習耗時 | 重要成長 |
| 200 | Java使用 |