隐馬爾可夫模型(HMM)總結
一、總結
一句話總結:
【社會規律】:【規律就是【不可抗拒】,誰也别想【免俗】】,比如社會的本質規則,比如人的一些本質規律,比如社交本質規律,【不可以違背,但是可以超脫,不可違反,但是可以急速,讀書做人做事請注意方法】
1、什麼是熵(Entropy)?
【系統的無序程度】:簡單來說,熵是表示物質系統狀态的一種度量,用它老表征系統的無序程度。
【熵越大,系統越無序】,意味着系統結構和運動的不确定和無規則;反之,,熵越小,系統越有序,意味着具有确定和有規則的運動狀态。
熵的中文意思是【熱量被溫度除的商】。負熵是物質系統有序化,組織化,複雜化狀态的一種度量。
熵最早來原于實體學. 德國實體學家魯道夫·克勞修斯首次提出熵的概念,用來表示【任何一種能量在空間中分布的均勻程度,能量分布得越均勻,熵就越大】。
2、熵的例子?
【一滴墨水滴在清水】中,部成了一杯淡藍色溶液。【熱水晾在空氣中】,熱量會傳到空氣中,最後使得溫度一緻。
熵力的一個例子是【耳機線】,我們将耳機線整理好放進口袋,下次再拿出來已經亂了。讓耳機線亂掉的看不見的“力”就是熵力,耳機線喜歡變成更混亂。熵力另一個具體的例子是【彈性力】。一根彈簧的力,就是熵力。 胡克定律其實也是一種熵力的表現。
于是從微觀看,【熵就表現了這個系統所處狀态的不确定性程度】。香農,描述一個資訊系統的時候就借用了熵的概念,這裡熵表示的是這個資訊系統的平均資訊量(平均不确定程度)。
3、最大熵模型?
我們在投資時常常講【不要把所有的雞蛋放在一個籃子裡】,這樣可以降低風險。在資訊進行中,這個原理同樣适用。在數學上,這個原理稱為【最大熵原理(the maximum entropy principle)】。
讓我們看一個拼音轉漢字的簡單的例子。假如輸入的拼音是【"wang-xiao-bo"】,利用語言模型,根據有限的上下文(比如前兩個詞),我們能給出兩個最常見的名字“王小波”和“王曉波 ”。至于要唯一确定是哪個名字就難了,即使利用較長的上下文也做不到。當然,我們知道如果通篇文章是介紹【文學】的,【作家王小波】的可能性就較大;而在讨論【兩岸關系】時,【台灣學者王曉波】的可能性會較大。
在上面的例子中,我們隻需要綜合兩類不同的資訊,即主題資訊和上下文資訊。雖然有不少湊合的辦法,比如:【分成成千上萬種的不同的主題單獨處理,或者對每種資訊的作用權重平均等等】,但都不能準确而圓滿地解決問題,這樣好比以前我們談到的行星運動模型中的小圓套大圓打更新檔的方法。在很多應用中,我們需要綜合幾十甚至上百種不同的資訊,這種小圓套大圓的方法顯然行不通。
數學上最漂亮的辦法是最大熵(maximum entropy)模型,它相當于行星運動的橢圓模型。“最大熵”這個名詞聽起來很深奧,但是它的原理很簡單,我們每天都在用。【說白了,就是要保留全部的不确定性,将風險降到最小】。
4、最大熵模型 "wang-xiao-bo"執行個體後續?
回到我們剛才談到的拼音轉漢字的例子,我們已知兩種資訊,第一,根據語言模型,wangxiao-bo可以被轉換成王曉波和王小波;第二,根據主題,王小波是作家,《黃金時代》的作者等等,而王曉波是台灣研究兩岸關系的學者。是以,【我們就可以建立一個最大熵模型,同時滿足這兩種資訊】。
現在的問題是,這樣一個模型是否存在。匈牙利著名數學家、資訊論最高獎香農獎得主希薩(Csiszar)證明,【對任何一組不自相沖突的資訊,這個最大熵模型不僅存在,而且是唯一的】。
而且它們都有【同一個非常簡單的形式--指數函數】。下面公式是根據上下文(前兩個詞)和主題預測下一個詞的最大熵模型,其中 w3 是要預測的詞(王曉波或者王小波)w1 和 w2 是它的前兩個字(比如說它們分别是“出版”,和“”),也就是其上下文的一個大緻估計,subject 表示主題。
$$P ( w _ { 3 } | w _ { 1 } , w _ { 2 } , \text { subject } ) = \frac { e ^ { ( \lambda _ { 1 } ( w _ { 1 } , w _ { 2 } , w _ { 3 } ) + \lambda _ { 2 } ( \text { subject } , w _ { 3 } ) ) } } { Z ( w _ { 1 } , w _ { 2 } , \text { subject } ) }$$
5、HMM(隐馬爾可夫模型)?
隐馬爾可夫模型(Hidden Markov Model,HMM)是【統計模型】,它用來描述一個【含有隐含未知參數的馬爾可夫過程】。其難點是從可觀察的參數中确定該過程的隐含參數。然後利用這些參數來作進一步的分析,例如【模式識别】。
假設我手裡有三個不同的骰子。第一個骰子是我們平常見的骰子(稱這個骰子為D6),6個面,每個面(1,2,3,4,5,6)出現的機率是1/6。第二個骰子是個四面體(稱這個骰子為D4),每個面(1,2,3,4)出現的機率是1/4。第三個骰子有八個面(稱這個骰子為D8),每個面(1,2,3,4,5,6,7,8)出現的機率是1/8。假設我們開始擲骰子,我們先從三個骰子裡挑一個,挑到每一個骰子的機率都是1/3。然後我們擲骰子,得到一個數字,1,2,3,4,5,6,7,8中的一個。不停的重複上述過程,我們會得到一串數字,每個數字都是1,2,3,4,5,6,7,8中的一個。例如我們【可能得到這麼一串數字(擲骰子10次):1 6 3 5 2 7 3 5 2 4】
這串數字叫做【可見狀态鍊】。但是在隐馬爾可夫模型中,我們不僅僅有這麼一串可見狀态鍊,還有一串【隐含狀态鍊】。在這個例子裡,這串隐含狀态鍊就是你用的骰子的序列。比如,隐含狀态鍊有可能是:D6 D8 D8 D6 D4 D8 D6 D6 D4 D8
一般來說,【HMM中說到的馬爾可夫鍊其實是指【隐含狀态鍊】】,因為【隐含狀态(骰子)之間存在轉換機率】(transition probability)。在我們這個例子裡,D6的下一個狀态是D4,D6,D8的機率都是1/3。D4,D8的下一個狀态是D4,D6,D8的轉換機率也都一樣是1/3。這樣設定是為了最開始容易說清楚,但是我們其實是可以随意設定轉換機率的。比如,【我們可以這樣定義,D6後面不能接D4,D6後面是D6的機率是0.9,是D8的機率是0.1。這樣就是一個新的HMM】。
6、HMM(隐馬爾可夫模型) 應用場景?
其實對于HMM來說,【如果提前知道所有隐含狀态之間的轉換機率和所有隐含狀态到所有可見狀态之間的輸出機率,做模拟是相當容易的】。
但是應用HMM模型時候呢,【往往是缺失了一部分資訊】的,有時候你知道骰子有幾種,每種骰子是什麼,但是不知道擲出來的骰子序列;有時候你隻是看到了很多次擲骰子的結果,剩下的什麼都不知道。如果應用算法去估計這些缺失的資訊,就成了一個很重要的問題。
7、和HMM模型相關的算法主要分為三類,分别解決三種問題?
1)知道骰子有幾種(隐含狀态數量),每種骰子是什麼(轉換機率),根據擲骰子擲出的結果(可見狀态鍊),我想知道每次擲出來的都是【哪種骰子(隐含狀态鍊)】。
2)還是知道骰子有幾種(隐含狀态數量),每種骰子是什麼(轉換機率),根據擲骰子擲出的結果(可見狀态鍊),我想知道【擲出這個結果的機率】。
3)知道骰子有幾種(隐含狀态數量),不知道每種骰子是什麼(轉換機率),觀測到很多次擲骰子的結果(可見狀态鍊),我想反推出【每種骰子是什麼(轉換機率)】。
8、HMM(隐馬爾可夫模型) 例子?
HMM(隐馬爾可夫模型)是用來描述隐含未知參數的統計模型,舉一個經典的例子:一個東京的朋友每天根據天氣{下雨,天晴}決定當天的活動{公園散步,購物,清理房間}中的一種,我每天隻能在twitter上看到她發的推“啊,我前天公園散步、昨天購物、今天清理房間了!”,那麼我可以【根據她發的推特推斷東京這三天的天氣】。在這個例子裡,顯狀态是活動,隐狀态是天氣。
任何一個HMM都可以通過下列五元組來描述::param obs:【觀測序列】、:param states:【隐狀态】、:param start_p:【初始機率(隐狀态)】、:param trans_p:【轉移機率(隐狀态)】、:param emit_p: 【發射機率 (隐狀态表現為顯狀态的機率)】
求解最可能的隐狀态序列是HMM的三個典型問題之一,通常用【維特比算法】解決。維特比算法就是【求解HMM上的最短路徑(-log(prob),也即是最大機率)的算法】。
9、維特比算法 算天晴下雨的例子?
1、【定義V[時間][今天天氣] = 機率】,注意今天天氣指的是,前幾天的天氣都确定下來了(機率最大)今天天氣是X的機率,這裡的機率就是一個累乘的機率了。
2、因為第一天我的朋友去散步了,是以【第一天下雨的機率V[第一天][下雨] = 初始機率[下雨] * 發射機率[下雨][散步] = 0.6 * 0.1 = 0.06】,同理可得【V[第一天][天晴] = 0.24】 。從直覺上來看,因為第一天朋友出門了,她一般喜歡在天晴的時候散步,是以第一天天晴的機率比較大,數字與直覺統一了。
3、從第二天開始,對于每種天氣Y,都有【前一天天氣是【X的機率 * X轉移到Y的機率】 * Y天氣下朋友進行這天這種活動的機率】。因為前一天天氣X有兩種可能,是以Y的機率有兩個,選取其中較大一個作為V[第二天][天氣Y]的機率,同時将今天的天氣加入到結果序列中
4、【比較V[最後一天][下雨]和[最後一天][天晴]的機率】,找出較大的哪一個對應的序列,就是最終結果。
二、一文搞懂HMM(隐馬爾可夫模型)(轉)
轉自:一文搞懂HMM(隐馬爾可夫模型)
https://www.cnblogs.com/skyme/p/4651331.html
什麼是熵(Entropy)
簡單來說,熵是表示物質系統狀态的一種度量,用它老表征系統的無序程度。熵越大,系統越無序,意味着系統結構和運動的不确定和無規則;反之,,熵越小,系統越有序,意味着具有确定和有規則的運動狀态。熵的中文意思是熱量被溫度除的商。負熵是物質系統有序化,組織化,複雜化狀态的一種度量。
熵最早來原于實體學. 德國實體學家魯道夫·克勞修斯首次提出熵的概念,用來表示任何一種能量在空間中分布的均勻程度,能量分布得越均勻,熵就越大。
- 一滴墨水滴在清水中,部成了一杯淡藍色溶液
- 熱水晾在空氣中,熱量會傳到空氣中,最後使得溫度一緻
更多的一些生活中的例子:
- 熵力的一個例子是耳機線,我們将耳機線整理好放進口袋,下次再拿出來已經亂了。讓耳機線亂掉的看不見的“力”就是熵力,耳機線喜歡變成更混亂。
- 熵力另一個具體的例子是彈性力。一根彈簧的力,就是熵力。 胡克定律其實也是一種熵力的表現。
- 萬有引力也是熵力的一種(熱烈讨論的話題)。
- 渾水澄清[1]
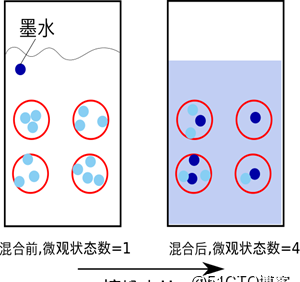
于是從微觀看,熵就表現了這個系統所處狀态的不确定性程度。香農,描述一個資訊系統的時候就借用了熵的概念,這裡熵表示的是這個資訊系統的平均資訊量(平均不确定程度)。
最大熵模型
我們在投資時常常講不要把所有的雞蛋放在一個籃子裡,這樣可以降低風險。在資訊進行中,這個原理同樣适用。在數學上,這個原理稱為最大熵原理(the maximum entropy principle)。
讓我們看一個拼音轉漢字的簡單的例子。假如輸入的拼音是"wang-xiao-bo",利用語言模型,根據有限的上下文(比如前兩個詞),我們能給出兩個最常見的名字“王小波”和“王曉波 ”。至于要唯一确定是哪個名字就難了,即使利用較長的上下文也做不到。當然,我們知道如果通篇文章是介紹文學的,作家王小波的可能性就較大;而在讨論兩岸關系時,台灣學者王曉波的可能性會較大。在上面的例子中,我們隻需要綜合兩類不同的資訊,即主題資訊和上下文資訊。雖然有不少湊合的辦法,比如:分成成千上萬種的不同的主題單獨處理,或者對每種資訊的作用權重平均等等,但都不能準确而圓滿地解決問題,這樣好比以前我們談到的行星運動模型中的小圓套大圓打更新檔的方法。在很多應用中,我們需要綜合幾十甚至上百種不同的資訊,這種小圓套大圓的方法顯然行不通。
數學上最漂亮的辦法是最大熵(maximum entropy)模型,它相當于行星運動的橢圓模型。“最大熵”這個名詞聽起來很深奧,但是它的原理很簡單,我們每天都在用。說白了,就是要保留全部的不确定性,将風險降到最小。
回到我們剛才談到的拼音轉漢字的例子,我們已知兩種資訊,第一,根據語言模型,wangxiao-bo可以被轉換成王曉波和王小波;第二,根據主題,王小波是作家,《黃金時代》的作者等等,而王曉波是台灣研究兩岸關系的學者。是以,我們就可以建立一個最大熵模型,同時滿足這兩種資訊。現在的問題是,這樣一個模型是否存在。匈牙利著名數學家、資訊論最高獎香農獎得主希薩(Csiszar)證明,對任何一組不自相沖突的資訊,這個最大熵模型不僅存在,而且是唯一的。而且它們都有同一個非常簡單的形式 -- 指數函數。下面公式是根據上下文(前兩個詞)和主題預測下一個詞的最大熵模型,其中 w3 是要預測的詞(王曉波或者王小波)w1 和 w2 是它的前兩個字(比如說它們分别是“出版”,和“”),也就是其上下文的一個大緻估計,subject 表示主題。

我們看到,在上面的公式中,有幾個參數 lambda 和 Z ,他們需要通過觀測資料訓練出來。最大熵模型在形式上是最漂亮的統計模型,而在實作上是最複雜的模型之一。
我們上次談到用最大熵模型可以将各種資訊綜合在一起。我們留下一個問題沒有回答,就是如何構造最大熵模型。我們已經所有的最大熵模型都是指數函數的形式,現在隻需要确定指數函數的參數就可以了,這個過程稱為模型的訓練。
最原始的最大熵模型的訓練方法是一種稱為通用疊代算法 GIS(generalized iterative scaling) 的疊代 算法。GIS 的原理并不複雜,大緻可以概括為以下幾個步驟:
1. 假定第零次疊代的初始模型為等機率的均勻分布。
2. 用第 N 次疊代的模型來估算每種資訊特征在訓練資料中的分布,如果超過了實際的,就把相應的模型參數變小;否則,将它們便大。
3. 重複步驟 2 直到收斂。
GIS 最早是由 Darroch 和 Ratcliff 在七十年代提出的。但是,這兩人沒有能對這種算法的實體含義進行很好地解釋。後來是由數學家希薩(Csiszar)解釋清楚的,是以,人們在談到這個算法時,總是同時引用 Darroch 和Ratcliff 以及希薩的兩篇論文。GIS 算法每次疊代的時間都很長,需要疊代很多次才能收斂,而且不太穩定,即使在 64 位計算機上都會出現溢出。是以,在實際應用中很少有人真正使用 GIS。大家隻是通過它來了解最大熵模型的算法。
八十年代,很有天才的孿生兄弟的達拉皮垂(Della Pietra)在 IBM 對 GIS 算法進行了兩方面的改進,提出了改進疊代算法 IIS(improved iterative scaling)。這使得最大熵模型的訓練時間縮短了一到兩個數量級。這樣最大熵模型才有可能變得實用。即使如此,在當時也隻有 IBM 有條件是用最大熵模型。
由于最大熵模型在數學上十分完美,對科學家們有很大的誘惑力,是以不少研究者試圖把自己的問題用一個類似最大熵的近似模型去套。誰知這一近似,最大熵模型就變得不完美了,結果可想而知,比打更新檔的湊合的方法也好不了多少。于是,不少熱心人又放棄了這種方法。第一個在實際資訊處理應用中驗證了最大熵模型的優勢的,是賓夕法尼亞大學馬庫斯的另一個高徒原 IBM 現微軟的研究員拉納帕提(Adwait Ratnaparkhi)。拉納帕提的聰明之處在于他沒有對最大熵模型進行近似,而是找到了幾個最适合用最大熵模型、而計算量相對不太大的自然語言處理問題,比如詞性标注和句法分析。拉納帕提成功地将上下文資訊、詞性(名詞、動詞和形容詞等)、句子成分(主謂賓)通過最大熵模型結合起來,做出了當時世界上最好的詞性辨別系統和句法分析器。拉納帕提的論文發表後讓人們耳目一新。拉納帕提的詞性标注系統,至今仍然是使用單一方法最好的系統。科學家們從拉納帕提的成就中,又看到了用最大熵模型解決複雜的文字資訊處理的希望。
但是,最大熵模型的計算量仍然是個攔路虎。我在學校時花了很長時間考慮如何簡化最大熵模型的計算量。終于有一天,我對我的導師說,我發現一種數學變換,可以将大部分最大熵模型的訓練時間在 IIS 的基礎上減少兩個數量級。我在黑闆上推導了一個多小時,他沒有找出我的推導中的任何破綻,接着他又回去想了兩天,然後告訴我我的算法是對的。從此,我們就建造了一些很大的最大熵模型。這些模型比修修補補的湊合的方法好不少。即使在我找到了快速訓練算法以後,為了訓練一個包含上下文資訊,主題資訊和文法資訊的文法模型(language model),我并行使用了20 台當時最快的 SUN 工作站,仍然計算了三個月。由此可見最大熵模型的複雜的一面。
最大熵模型,可以說是集簡與繁于一體,形式簡單,實作複雜。值得一提的是,在Google的很多産品中,比如機器翻譯,都直接或間接地用到了最大熵模型。
講到這裡,讀者也許會問,當年最早改進最大熵模型算法的達拉皮垂兄弟這些年難道沒有做任何事嗎?他們在九十年代初賈裡尼克離開 IBM 後,也退出了學術界,而到在金融界大顯身手。他們兩人和很多 IBM 語音識别的同僚一同到了一家當時還不大,但現在是世界上最成功對沖基金(hedge fund)公司----文藝複興技術公司 (Renaissance Technologies)。我們知道,決定股票漲落的因素可能有幾十甚至上百種,而最大熵方法恰恰能找到一個同時滿足成千上萬種不同條件的模型。達拉皮垂兄弟等科學家在那裡,用于最大熵模型和其他一些先進的數學工具對股票預測,獲得了巨大的成功。從該基金 1988 年創立至今,它的淨回報率高達平均每年 34%。也就是說,如果 1988 年你在該基金投入一塊錢,今天你能得到 200 塊錢。這個業績,遠遠超過股神巴菲特的旗艦公司伯克夏哈撒韋(Berkshire Hathaway)。同期,伯克夏哈撒韋的總回報是 16 倍。
值得一提的是,資訊處理的很多數學手段,包括隐含馬爾可夫模型、子波變換、貝葉斯網絡等等,在華爾街多有直接的應用。由此可見,數學模型的作用。
HMM(隐馬爾可夫模型)
隐馬爾可夫模型(Hidden Markov Model,HMM)是統計模型,它用來描述一個含有隐含未知參數的馬爾可夫過程。其難點是從可觀察的參數中确定該過程的隐含參數。然後利用這些參數來作進一步的分析,例如模式識别。
是在被模組化的系統被認為是一個馬爾可夫過程與未觀測到的(隐藏的)的狀态的統計馬爾可夫模型。
下面用一個簡單的例子來闡述:
假設我手裡有三個不同的骰子。第一個骰子是我們平常見的骰子(稱這個骰子為D6),6個面,每個面(1,2,3,4,5,6)出現的機率是1/6。第二個骰子是個四面體(稱這個骰子為D4),每個面(1,2,3,4)出現的機率是1/4。第三個骰子有八個面(稱這個骰子為D8),每個面(1,2,3,4,5,6,7,8)出現的機率是1/8。
假設我們開始擲骰子,我們先從三個骰子裡挑一個,挑到每一個骰子的機率都是1/3。然後我們擲骰子,得到一個數字,1,2,3,4,5,6,7,8中的一個。不停的重複上述過程,我們會得到一串數字,每個數字都是1,2,3,4,5,6,7,8中的一個。例如我們可能得到這麼一串數字(擲骰子10次):1 6 3 5 2 7 3 5 2 4
這串數字叫做可見狀态鍊。但是在隐馬爾可夫模型中,我們不僅僅有這麼一串可見狀态鍊,還有一串隐含狀态鍊。在這個例子裡,這串隐含狀态鍊就是你用的骰子的序列。比如,隐含狀态鍊有可能是:D6 D8 D8 D6 D4 D8 D6 D6 D4 D8
一般來說,HMM中說到的馬爾可夫鍊其實是指隐含狀态鍊,因為隐含狀态(骰子)之間存在轉換機率(transition probability)。在我們這個例子裡,D6的下一個狀态是D4,D6,D8的機率都是1/3。D4,D8的下一個狀态是D4,D6,D8的轉換機率也都一樣是1/3。這樣設定是為了最開始容易說清楚,但是我們其實是可以随意設定轉換機率的。比如,我們可以這樣定義,D6後面不能接D4,D6後面是D6的機率是0.9,是D8的機率是0.1。這樣就是一個新的HMM。
同樣的,盡管可見狀态之間沒有轉換機率,但是隐含狀态和可見狀态之間有一個機率叫做輸出機率(emission probability)。就我們的例子來說,六面骰(D6)産生1的輸出機率是1/6。産生2,3,4,5,6的機率也都是1/6。我們同樣可以對輸出機率進行其他定義。比如,我有一個被賭場動過手腳的六面骰子,擲出來是1的機率更大,是1/2,擲出來是2,3,4,5,6的機率是1/10。
其實對于HMM來說,如果提前知道所有隐含狀态之間的轉換機率和所有隐含狀态到所有可見狀态之間的輸出機率,做模拟是相當容易的。但是應用HMM模型時候呢,往往是缺失了一部分資訊的,有時候你知道骰子有幾種,每種骰子是什麼,但是不知道擲出來的骰子序列;有時候你隻是看到了很多次擲骰子的結果,剩下的什麼都不知道。如果應用算法去估計這些缺失的資訊,就成了一個很重要的問題。這些算法我會在下面詳細講。
×××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××
如果你隻想看一個簡單易懂的例子,就不需要往下看了。
×××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××
說兩句廢話,答主認為呢,要了解一個算法,要做到以下兩點:會其意,知其形。答主回答的,其實主要是第一點。但是這一點呢,恰恰是最重要,而且很多書上不會講的。正如你在追一個姑娘,姑娘對你說“你什麼都沒做錯!”你要是隻看姑娘的表達形式呢,認為自己什麼都沒做錯,顯然就了解錯了。你要理會姑娘的意思,“你趕緊給我道歉!”這樣當你看到對應的表達形式呢,趕緊認錯,跪地求饒就對了。數學也是一樣,你要是不了解意思,光看公式,往往一頭霧水。不過呢,數學的表達頂多也就是晦澀了點,姑娘的表達呢,有的時候就完全和本意相反。是以答主一直認為了解姑娘比了解數學難多了。
回到正題,和HMM模型相關的算法主要分為三類,分别解決三種問題:
1)知道骰子有幾種(隐含狀态數量),每種骰子是什麼(轉換機率),根據擲骰子擲出的結果(可見狀态鍊),我想知道每次擲出來的都是哪種骰子(隐含狀态鍊)。
這個問題呢,在語音識别領域呢,叫做解碼問題。這個問題其實有兩種解法,會給出兩個不同的答案。每個答案都對,隻不過這些答案的意義不一樣。第一種解法求最大似然狀态路徑,說通俗點呢,就是我求一串骰子序列,這串骰子序列産生觀測結果的機率最大。第二種解法呢,就不是求一組骰子序列了,而是求每次擲出的骰子分别是某種骰子的機率。比如說我看到結果後,我可以求得第一次擲骰子是D4的機率是0.5,D6的機率是0.3,D8的機率是0.2.第一種解法我會在下面說到,但是第二種解法我就不寫在這裡了,如果大家有興趣,我們另開一個問題繼續寫吧。
2)還是知道骰子有幾種(隐含狀态數量),每種骰子是什麼(轉換機率),根據擲骰子擲出的結果(可見狀态鍊),我想知道擲出這個結果的機率。
看似這個問題意義不大,因為你擲出來的結果很多時候都對應了一個比較大的機率。問這個問題的目的呢,其實是檢測觀察到的結果和已知的模型是否吻合。如果很多次結果都對應了比較小的機率,那麼就說明我們已知的模型很有可能是錯的,有人偷偷把我們的骰子給換了。
3)知道骰子有幾種(隐含狀态數量),不知道每種骰子是什麼(轉換機率),觀測到很多次擲骰子的結果(可見狀态鍊),我想反推出每種骰子是什麼(轉換機率)。
這個問題很重要,因為這是最常見的情況。很多時候我們隻有可見結果,不知道HMM模型裡的參數,我們需要從可見結果估計出這些參數,這是模組化的一個必要步驟。
問題闡述完了,下面就開始說解法。(0号問題在上面沒有提,隻是作為解決上述問題的一個輔助)
0.一個簡單問題
其實這個問題實用價值不高。由于對下面較難的問題有幫助,是以先在這裡提一下。
知道骰子有幾種,每種骰子是什麼,每次擲的都是什麼骰子,根據擲骰子擲出的結果,求産生這個結果的機率。
解法無非就是機率相乘:
1.看見不可見的,破解骰子序列
這裡我說的是第一種解法,解最大似然路徑問題。
舉例來說,我知道我有三個骰子,六面骰,四面骰,八面骰。我也知道我擲了十次的結果(1 6 3 5 2 7 3 5 2 4),我不知道每次用了那種骰子,我想知道最有可能的骰子序列。
其實最簡單而暴力的方法就是窮舉所有可能的骰子序列,然後依照第零個問題的解法把每個序列對應的機率算出來。然後我們從裡面把對應最大機率的序列挑出來就行了。如果馬爾可夫鍊不長,當然可行。如果長的話,窮舉的數量太大,就很難完成了。
另外一種很有名的算法叫做Viterbi algorithm. 要了解這個算法,我們先看幾個簡單的列子。
首先,如果我們隻擲一次骰子:
看到結果為1.對應的最大機率骰子序列就是D4,因為D4産生1的機率是1/4,高于1/6和1/8.
把這個情況拓展,我們擲兩次骰子:
結果為1,6.這時問題變得複雜起來,我們要計算三個值,分别是第二個骰子是D6,D4,D8的最大機率。顯然,要取到最大機率,第一個骰子必須為D4。這時,第二個骰子取到D6的最大機率是
同樣的,我們可以計算第二個骰子是D4或D8時的最大機率。我們發現,第二個骰子取到D6的機率最大。而使這個機率最大時,第一個骰子為D4。是以最大機率骰子序列就是D4 D6。
繼續拓展,我們擲三次骰子:
同樣,我們計算第三個骰子分别是D6,D4,D8的最大機率。我們再次發現,要取到最大機率,第二個骰子必須為D6。這時,第三個骰子取到D4的最大機率是
同上,我們可以計算第三個骰子是D6或D8時的最大機率。我們發現,第三個骰子取到D4的機率最大。而使這個機率最大時,第二個骰子為D6,第一個骰子為D4。是以最大機率骰子序列就是D4 D6 D4。
寫到這裡,大家應該看出點規律了。既然擲骰子一二三次可以算,擲多少次都可以以此類推。我們發現,我們要求最大機率骰子序列時要做這麼幾件事情。首先,不管序列多長,要從序列長度為1算起,算序列長度為1時取到每個骰子的最大機率。然後,逐漸增加長度,每增加一次長度,重新算一遍在這個長度下最後一個位置取到每個骰子的最大機率。因為上一個長度下的取到每個骰子的最大機率都算過了,重新計算的話其實不難。當我們算到最後一位時,就知道最後一位是哪個骰子的機率最大了。然後,我們要把對應這個最大機率的序列從後往前推出來。
2.誰動了我的骰子?
比如說你懷疑自己的六面骰被賭場動過手腳了,有可能被換成另一種六面骰,這種六面骰擲出來是1的機率更大,是1/2,擲出來是2,3,4,5,6的機率是1/10。你怎麼辦麼?答案很簡單,算一算正常的三個骰子擲出一段序列的機率,再算一算不正常的六面骰和另外兩個正常骰子擲出這段序列的機率。如果前者比後者小,你就要小心了。
比如說擲骰子的結果是:
要算用正常的三個骰子擲出這個結果的機率,其實就是将所有可能情況的機率進行加和計算。同樣,簡單而暴力的方法就是把窮舉所有的骰子序列,還是計算每個骰子序列對應的機率,但是這回,我們不挑最大值了,而是把所有算出來的機率相加,得到的總機率就是我們要求的結果。這個方法依然不能應用于太長的骰子序列(馬爾可夫鍊)。
我們會應用一個和前一個問題類似的解法,隻不過前一個問題關心的是機率最大值,這個問題關心的是機率之和。解決這個問題的算法叫做前向算法(forward algorithm)。
首先,如果我們隻擲一次骰子:
看到結果為1.産生這個結果的總機率可以按照如下計算,總機率為0.18:
把這個情況拓展,我們擲兩次骰子:
看到結果為1,6.産生這個結果的總機率可以按照如下計算,總機率為0.05:
看到結果為1,6,3.産生這個結果的總機率可以按照如下計算,總機率為0.03:
同樣的,我們一步一步的算,有多長算多長,再長的馬爾可夫鍊總能算出來的。用同樣的方法,也可以算出不正常的六面骰和另外兩個正常骰子擲出這段序列的機率,然後我們比較一下這兩個機率大小,就能知道你的骰子是不是被人換了。
Viterbi algorithm
HMM(隐馬爾可夫模型)是用來描述隐含未知參數的統計模型,舉一個經典的例子:一個東京的朋友每天根據天氣{下雨,天晴}決定當天的活動{公園散步,購物,清理房間}中的一種,我每天隻能在twitter上看到她發的推“啊,我前天公園散步、昨天購物、今天清理房間了!”,那麼我可以根據她發的推特推斷東京這三天的天氣。在這個例子裡,顯狀态是活動,隐狀态是天氣。
任何一個HMM都可以通過下列五元組來描述:
:param obs:觀測序列
:param states:隐狀态
:param start_p:初始機率(隐狀态)
:param trans_p:轉移機率(隐狀态)
:param emit_p: 發射機率 (隐狀态表現為顯狀态的機率) 僞碼如下:
states = ('Rainy', 'Sunny')
observations = ('walk', 'shop', 'clean')
start_probability = {'Rainy': 0.6, 'Sunny': 0.4}
transition_probability = {
'Rainy' : {'Rainy': 0.7, 'Sunny': 0.3},
'Sunny' : {'Rainy': 0.4, 'Sunny': 0.6},
}
emission_probability = {
'Rainy' : {'walk': 0.1, 'shop': 0.4, 'clean': 0.5},
'Sunny' : {'walk': 0.6, 'shop': 0.3, 'clean': 0.1},
} 求解最可能的天氣
求解最可能的隐狀态序列是HMM的三個典型問題之一,通常用維特比算法解決。維特比算法就是求解HMM上的最短路徑(-log(prob),也即是最大機率)的算法。
稍微用中文講講思路,很明顯,第一天天晴還是下雨可以算出來:
- 定義V[時間][今天天氣] = 機率,注意今天天氣指的是,前幾天的天氣都确定下來了(機率最大)今天天氣是X的機率,這裡的機率就是一個累乘的機率了。
- 因為第一天我的朋友去散步了,是以第一天下雨的機率V[第一天][下雨] = 初始機率[下雨] * 發射機率[下雨][散步] = 0.6 * 0.1 = 0.06,同理可得V[第一天][天晴] = 0.24 。從直覺上來看,因為第一天朋友出門了,她一般喜歡在天晴的時候散步,是以第一天天晴的機率比較大,數字與直覺統一了。
- 從第二天開始,對于每種天氣Y,都有前一天天氣是X的機率 * X轉移到Y的機率 * Y天氣下朋友進行這天這種活動的機率。因為前一天天氣X有兩種可能,是以Y的機率有兩個,選取其中較大一個作為V[第二天][天氣Y]的機率,同時将今天的天氣加入到結果序列中
- 比較V[最後一天][下雨]和[最後一天][天晴]的機率,找出較大的哪一個對應的序列,就是最終結果。
算法的代碼可以在github上看到,位址為:
https://github.com/hankcs/Viterbi
運作完成後根據Viterbi得到結果:
Sunny Rainy Rainy Viterbi被廣泛應用到分詞,詞性标注等應用場景。