采取什麼辦法可以讓一個Web服務可大規模可擴充?相信你會對這個問題感興趣。
克隆
通常來說,公共伺服器上的一個可伸縮的web服務總是隐藏在一個Load Balancer(負載均衡器)之後。這個負載均衡器會将負載(來自使用者的請求)均勻的配置設定到一組伺服器或者伺服器叢集。那意味着什麼?舉個例子:某個使用者通路你的服務,他第一次的請求可能會由第二台伺服器提供,第二次請求由第9台伺服器提供,第3次請求又再次由第二台伺服器提供。
對于該使用者而言,他每次得到的結果應該是一樣的,不依賴服務到底是哪台伺服器提供的。這個正是可伸縮性的第一個黃金法則:每個伺服器都包含完全相同的代碼庫,不在本地磁盤或記憶體存儲任何與使用者相關的資料,如session或使用者資訊。Session需要集中存儲,使得每一台伺服器都可以通路到它。它可以是一個外部資料庫或外部持久緩存,比如Redis。相比外部資料庫,在持久化的緩存中存放session将會有更好的性能。這裡提到的“外部”指的是資料存儲不放置在這些應用伺服器上,而是在接近您的應用程式伺服器的資料中心。
但是這要怎麼部署呢?你如何确定當應用代碼發生了改變能夠發送到所有的伺服器而沒有一台伺服器依舊使用之前的代碼?幸運的是,這個棘手的問題已經被一個很好的工具capistrano解決了,你需要稍微學習了解下。
在解決了session和多台伺服器上新版本的同步更新問題之後,你需要做的就是克隆你的機器鏡像了,然後将你最新的代碼部署上去。可以參考Amazon提供的AMI服務(Amazon Machine Image)
現在你的伺服器可以水準擴充,并且處理成千上萬的并發請求了。
資料庫
但是你發現應用程式變得越來越來最終崩潰。問題的原因:是MySql,不是嗎?
現在不是增加更多的機器可以解決的問題了,你有兩種辦法:
- 1,堅持使用MySql,并且讓它運作良好。做主從複制(從伺服器負責讀取,主伺服器負責寫入),并且更新主伺服器,不斷加入更多的記憶體。随着不斷優化,你會使用資料庫分片、反規模化、SQL調優等常用手段。這時,對于資料庫的任何一個操作成本都會變得相當昂貴。
- 2,切換到一個更加容易擴充的NoSQL資料庫,比如 MongoDB或CouchDB,連接配接查詢現在需要在應用代碼層裡去進行了。
現在,你的資料庫有了一個可擴充的解決方案了,你再也不用擔心存儲TB級的資料,世界看起來那麼的美好。
緩存
當大量的資料請求發往到資料庫,你發現又變慢了,解決辦法是增加緩存。
這裡說的緩存指的是記憶體緩存,比如常見的記憶體資料庫Memcached或者Redis ,千萬不要使用檔案緩存,它會讓你伺服器的克隆和自動伸縮很痛苦。
但是回到記憶體緩存,緩存是一個簡單的鍵值存儲并且應該介于應用程式和資料存儲。任何時候當你的應用程式需要去讀取資料時,它首先應該嘗試從緩存裡面擷取資料,新航道教育訓練隻有無法從緩存中讀取資料時,才會嘗試從資料庫中讀到。為什麼要這麼做呢?因為緩存快如閃電,它将資料集存放在記憶體中,并且可以快速的被處理。舉個例子:Redis沒秒鐘可以處理成千上萬的讀操作。
通路流程:第一次通路綠色,第二次和之後的藍色:
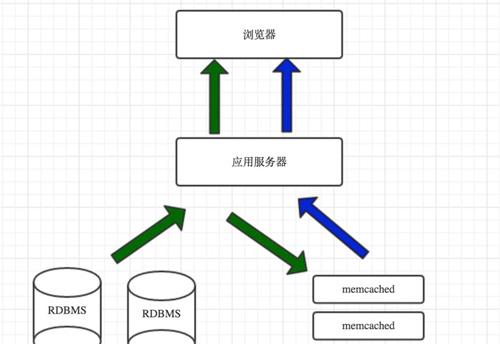
有兩種緩存資料的模式,一種是老的方式,一種是新的方式:
- 1,緩存資料庫查詢,這個仍然是最普遍的緩存方式,當你做一次查詢時,将資料集進行緩存,通過哈希後查詢串作為鍵。下一次查詢時,檢查緩存中是否有結果。這種方式存在一些問題,最主要的問題就是過期。當資料表中的一塊資料發生變化時,你需要删除所有包含這個資料塊的查詢串的緩存。
- 2,緩存對象,我強烈推薦使用這種方式,這也是我經常使用的。
一些适合緩存的對象:
- 使用者Session(永遠不存放在資料庫中)
- 完全呈現的部落格文章
- 活動流
- 使用者<- -> 朋友 之類的關系
異步
請想象一下,你想在你最喜歡的面包店買面包,是以你走進面包店,向一個店員詢問購買面包,但是面包都賣光了。你被告知2個小時之後你訂的面包可以好,這個很惱人,不是嗎?
為了避免這種“請等片刻”的場景,需要采取異步。比如什麼時候有面包了,店員會将面包派送給你的家裡。通常來說,有兩種異步的範例:
- 1,讓我們回到普通的買面包的場景,第一種異步處理流程是:“晚上把面包都烹制好,第二天早上賣”,這個對于顧客來說不需要等待。對于一個web應用程式,這意味着提前做耗時的工作,這樣就可以在短時間處理完工作。通常這種模式用來将動态的内容轉換為靜态内容。比如提前渲染好CMS裡面的一些網頁,并且本地存儲這些HTML檔案。采用定時任務,可能是通過腳本叫做每小時的計劃。這種對通用資料預先計算可以極大的提升網站和web app的可伸縮性和性能。可以通過腳本将這些預先渲染好的HTML頁面釋出至CDN。你的網站将能做到響應超快并且每小時可以處理成千上萬的遊客!
![元宇宙落地年,為什麼元美科技創始人張鶴認為,最先把VisionPro價值挖掘出來的是B端而非C端?在與“中國元宇宙未來産[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)