說明
- 最近工作需要調研資料搜尋相關技術,可選的隻有Elasticsearch和solr,比較發現Elasticsearch更加符合場景需要。
介紹
- Elasticsearch 基于Apache Lucene開發的開源分布式、高擴充、高實時的搜尋與資料分析引擎。基于RESTful web接口,提供一個分布式多使用者能力的全文搜尋引擎。
- Elasticsearch是用Java語言開發的,是一種流行的企業級搜尋引擎,應用于搜尋各種文檔,提供擴充功能,具有接近實時的搜尋效率,支援多租戶。可以擴充到上百台伺服器,處理PB級别的資料,能夠達到實時搜尋,穩定,可靠,快速,安裝使用友善。
- 用戶端支援Java、.NET(C#)、PHP、Python、Apache Groovy、Ruby等語言開發。
- 同類型産品solor(同樣基于Apache Lucene)
發展史
- Elasticsearch BV成立于2012年,主要圍繞Elasticsearch及相關軟體提供商業服務和産品。2014年6月,在成立公司18個月後,該公司宣布通過C輪融資籌集7000萬美元。這輪融資由新企業協會(NEA)牽頭。其他投資者包括Benchmark Capital和Index Ventures。這一輪融資總計1.04億美元
- 2015年3月,Elasticsearch公司更名為Elastic。
- 2018年6月,Elastic送出了首次公開募股申請,估值在15億到30億美元之間。公司于2018年10月5日在紐約證券交易所挂牌上市。一些組織将Elasticsearch作為托管服務提供。這些托管服務提供托管、部署、備份和其他支援。大多數托管服務還包括對Kibana的支援。
産品應用
- 2013年初,GitHub抛棄了Solr,采取ElasticSearch 來做PB級的搜尋。 “GitHub使用ElasticSearch搜尋20TB的資料,包括13億檔案和1300億行代碼”
- 維基百科:啟動以elasticsearch為基礎的核心搜尋架構
- SoundCloud:“SoundCloud使用ElasticSearch為1.8億使用者提供即時而精準的音樂搜尋服務”
- 百度:百度目前廣泛使用ElasticSearch作為文本資料分析,采集百度所有伺服器上的各類名額資料及使用者自定義資料,通過對各種資料進行多元分析展示,輔助定位分析執行個體異常或業務層面異常。目前覆寫百度内部20多個業務線(包括casio、雲分析、網盟、預測、文庫、直達号、錢包、風控等),單叢集最大100台機器,200個ES節點,每天導入30TB+資料
- 新浪使用ES 分析處理32億條實時日志
- 阿裡使用ES 建構挖财自己的日志采集和分析體系
資料
官方
- Elasticsearch 官網 報價,示範版本7.10.1
- 軟體下載下傳官方提供多種版本普通版、Elastic版(ecctl)、No Jdk版、OSS版、OSS No Jdk版
- alpha 預覽版bug較多
- Beta 修複重大bug,有少量小問題
- Legacy 遺留老版本穩定版
- Kibana 收費可視化工具,檢視和管理Elasticsearch 版本與安裝包一緻
- 官方安裝文檔
- 中文文檔 部分内容老舊,建議查閱官方文檔
插件
- head插件,與Kibana功能類似,git位址需要nodejs環境
- 經測試,目前版本支援
- cerebro 類kibanna功能軟體,警惕相容問題。
- ik分詞器 git位址版本與安裝包一緻
端口說明
- 9300 tcp通信端口
- 9200 http協定端口
基本概念
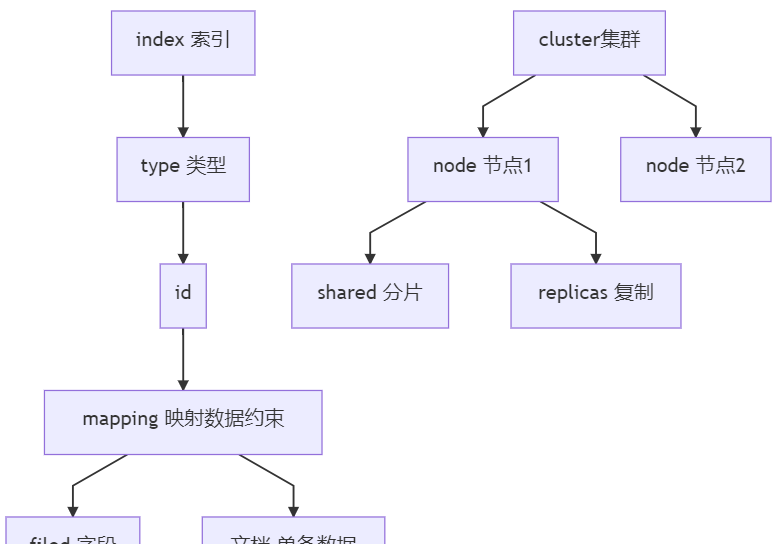
index索引
- index是資料管理的頂層機關,Elasticsearch會索引所有所有字段,索引、搜尋、更新、删除資料的時候,都會用到索引,索引名:必須全部是<span style="color:red;font-weight:bold">小寫</span>字母,它是單個資料庫,可類比mysql中的資料庫
type類型
- 一個索引中,你可以定義一種或多種類型。該屬性在新版本中被删除了。一個類型是你的索引的一個邏輯上的分類/分區。通常,會為具有一組共同字段的文檔定義一個類型。比如說,我們假設你營運一個部落格平台并且将你所有的資料存儲到一個索引中。在這個索引中,你可以為使用者資料定義一個類型,為部落格資料定義另一個類型,可類比mysql中的表。
id
- 和type對應,字元串類型,是id的唯一辨別。
mapping 定義資料結構
- mapping是限制處理資料的方式和規則,如某個字段的資料類型、預設值、分析器、是否被索引等,都是可以通過映射設定,另外處理esearch裡面資料的一些使用規則設定也叫做映射。因為按最優規則處理資料對性能提高很大,是以才需要建立映射,并且需要思考如何建立映射才能對性能更好。相當于mysql中,設定表的主鍵外鍵等,類比表結構
filed字段
- 相當于mysql 資料表的字段,對文檔資料根據不同屬性進行的分類辨別 。
document文檔
- 一個文檔是一個可被索引的基礎資訊單元,文檔以JSON(Javascript Object Notation)格式來表示,在一個index/type裡面,你可以存儲任意多的文檔。插入索引庫以文檔為機關,類比與資料庫中的一行資料
分布式
cluster 叢集
- 一個叢集就是由一個或多個節點組織在一起,它們共同持有所有資料,并提供索引和搜尋功能。一個叢集由一個唯一的名字辨別預設“elasticsearch”。一個節點隻能通過指定某個集 群的名字,來加入這個叢集。
node 節點
- 節點是叢集中的一個伺服器,作為叢集的一部分,它存儲資料,參與叢集的索引和搜尋功能。一個節點由一個名字來辨別,預設情況下,名字是一個随機的漫威漫畫角色的名字,這個名字會在啟動時賦予節點,該名字在叢集中唯一,以便cluster管理。預設情況下,隻啟動一個節點,預設建立并加入一個叫做“elasticsearch”的叢集。
shared 分片
- 一個索引可以存儲超出單個結點硬體限制的大量資料。比如,一個具有10億文檔的索引占據1TB的磁盤空間,而任一節點都沒有這樣大的磁盤空間;或者單個節點處理搜尋請求,響應太慢。為了解決這個問題,Elasticsearch提供了将索引劃分成多份的能力,這個過程叫做分片。當你建立一個索引的時候,你可以指定你想要的分片的數量。每個分片本身也是一個功能完善并且獨立的“索引”,這個“索引”可以被放置到叢集中的任何節點上。分片很重要,主要有兩方面的原因: *
- 允許你水準分割/擴充你的内容容量。
- 允許你在分片(潛在地,位于多個節點上)之上進行分布式的、并行的操作,進而提高性能/吞吐量。
replicas 複制
- 在一個網絡/雲的環境裡,失敗随時都可能發生,在某個分片/節點因未知原因處于離線狀态或消失,這種情況下,有一個故障轉移機制是非常有用并且是強烈推薦的。Elasticsearch為此允許建立分片的一份或多份拷貝,這些拷貝叫做複制分片,原有分片為主分片。有了複制分片既可以防止單節點故障,也可以并行計算單元增強搜尋和吞吐量。
- 預設情況下,Elasticsearch中的每個索引被分片5個主分片和1個複制,這意味着,如果你的叢集中至少有兩個節點,你的索引将會有5個主分片和另外5個複制分片(1個完全拷貝),這樣的話每個索引總共就有10個分片。
使用方法
- 使用者将資料送出到Elasticsearch 資料庫中,再通過分詞控制器去将對應的語句分詞,将其權重和分詞結果一并存入資料
- 使用者搜尋資料時候,再根據權重将結果排名,打分,再将傳回結果呈現給使用者。
安裝步驟
下載下傳安裝包
-
- linux wget -c https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.10.1-linux-x86_64.tar.gz
- windows:https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.10.1-no-jdk-windows-x86_64.zip
安裝
- 解壓到安裝目錄即可
分詞器ik
- 下載下傳安裝包位址和安裝版本對應
- 解壓,将解壓後的elasticsearch檔案夾拷貝到elasticsearch-7.10.1\plugins下,并重命名檔案夾為analysis-ik (避免重名)
-
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd"> <properties> <comment>IK Analyzer 擴充配置</comment> <!--使用者可以在這裡配置自己的擴充字典 --> <entry key="ext_dict"></entry> <!--使用者可以在這裡配置自己的擴充停止詞字典--> <entry key="ext_stopwords"></entry> <!--使用者可以在這裡配置遠端擴充字典 --> <!-- <entry key="remote_ext_dict">words_location</entry> --> <!--使用者可以在這裡配置遠端擴充停止詞字典--> <!-- <entry key="remote_ext_stopwords">words_location</entry> --> </properties>- 分詞檔案plugins\elasticsearch-analysis-ik\config*.dic
- 分詞配置檔案:plugins\elasticsearch-analysis-ik\config\IKAnalyzer.cfg.xml
-
- 請求:http://127.0.0.1:9200/_analyze
- 請求體:{"analyzer":"ik_smart","text":"我是程式員"
- 請求體:{"analyzer":"ik_max_word","text":"我是程式員"
kibana
- 下載下傳 與elasticSearch版本一緻,node開發實作
-
- 解壓到安裝目錄
- config/kibana.yml 設定服務啟動端口和esearch位址
- 啟動
- bin/kibana.bat 啟動即可
- 驗證
- 首頁
- 狀态檢視
配置
- 指定jdk,修改bin/elasticsearch-env.bat檔案,指定安裝包自帶jdkset JAVA_HOME=D:\test\elasticsearch-7.8.0\jdk,路徑不要有中文
- 修改jvm,conf\jvm.option
- 修改conf\elasticsearch.yml檔案末尾添加,目的是使ES支援跨域請求
http.cors.enabled: true
http.cors.allow-origin: "*"
network.host: 127.0.0.1 - 解壓即可安裝使用,bin目錄運作elasticsearch.bat檔案即可
- 啟動後本地驗證http://localhost:9200/
Elasticsearch和solr對比
| 對比項 | ElasticSearch | solr |
|---|---|---|
| 分布式管理 | 自帶分布式管理功能 | zookeeper |
| 資料格式 | 僅支援json | 多種資料格式 |
| 官方功能 | 注重核心功能,進階功能第三方插件提供 | 官方提供功能多 |
| 搜尋應用 | 實時搜尋應用 | 傳統搜尋應用 |
總結
- Elasticsearch本質上還是資料庫,相比普通的關系型資料,功能更加靈活,資料量更大,支援比sql更複雜的規則查詢,在搜尋引擎或實時資料處理分析方面有很好的應用場景。
![k8s部署es叢集和kibana[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)