一、Ceph簡介
系統設計旨在性能、可靠性和可擴充性上能夠提供優秀的存儲服務。Ceph分布式存儲能夠在一個統一的系統中同時提供了對象、塊、和檔案存儲功能,在這方面獨一無二的;同時在擴充性上又可支援數以千計的用戶端可以通路PB級到EB級甚至更多的資料。它不但适應非結構化資料,并且用戶端可以同時使用目前及傳統的對象接口進行資料存取,被稱為是存儲的未來!
二、Ceph的特點
2.1 ceph的優勢
- CRUSH算法:Ceph摒棄了傳統的集中式存儲中繼資料尋址的方案,轉而使用CRUSH算法完成資料的尋址操作。CRUSH在一緻性哈希基礎上很好的考慮了容災域的隔離,能夠實作各類負載的副本放置規則,例如跨機房、機架感覺等。Ceph會将CRUSH規則集配置設定給存儲池。當Ceph用戶端存儲或檢索存儲池中的資料時,Ceph會自動識别CRUSH規則集、以及存儲和檢索資料這一規則中的頂級bucket。當Ceph處理CRUSH規則時,它會識别出包含某個PG的主OSD,這樣就可以使用戶端直接與主OSD進行連接配接進行資料的讀寫。
- 高可用:Ceph中的資料副本數量可以由管理者自行定義,并可以通過CRUSH算法指定副本的實體存儲位置以分隔故障域, 可以忍受多種故障場景并自動嘗試并行修複。同時支援強一緻副本,而副本又能夠垮主機、機架、機房、資料中心存放。是以安全可靠。存儲節點可以自管理、自動修複。無單點故障,有很強的容錯性;
- 高擴充性:Ceph不同于swift,用戶端所有的讀寫操作都要經過代理節點。一旦叢集并發量增大時,代理節點很容易成為單點瓶頸。Ceph本身并沒有主要節點,擴充起來比較容易,并且理論上,它的性能會随着磁盤數量的增加而線性增長;
- 特性豐富:Ceph支援三種調用接口:對象存儲,塊存儲,檔案系統挂載。三種方式可以一同使用。Ceph統一存儲,雖然Ceph底層是一個分布式檔案系統,但由于在上層開發了支援對象和塊的接口;
- 統一的存儲:能同時提供對象存儲、檔案存儲和塊存儲;
三、架構與元件
3.1 ceph的架構示意圖:
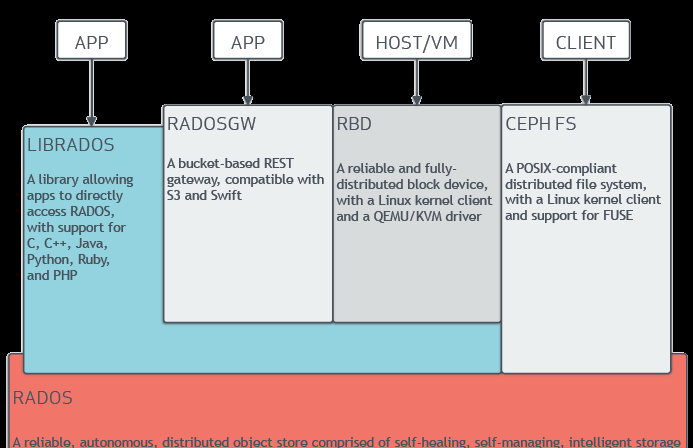
- Ceph的底層是RADOS,RADOS本身也是分布式存儲系統,CEPH所有的存儲功能都是基于RADOS實作。RADOS采用C++開發,所提供的原生Librados API包括C和C++兩種。Ceph的上層應用調用本機上的librados API,再由後者通過socket與RADOS叢集中的其他節點通信并完成各種操作。
- RADOS向外界暴露了調用接口,即LibRADOS,應用程式隻需要調用LibRADOS的接口,就可以操縱Ceph了。這其中,RADOS GW用于對象存儲,RBD用于塊存儲,它們都屬于LibRADOS;CephFS是核心态程式,向外界提供了POSIX接口,使用者可以通過用戶端直接挂載使用。
- RADOS GateWay、RBD其作用是在librados庫的基礎上提供抽象層次更高、更便于應用或用戶端使用的上層接口。其中,RADOS GW是一個提供與Amazon S3和Swift相容的RESTful API的gateway,以供相應的對象存儲應用開發使用。RBD則提供了一個标準的塊裝置接口,常用于在虛拟化的場景下為虛拟機建立volume。目前,Red Hat已經将RBD驅動內建在KVM/QEMU中,以提高虛拟機通路性能。這兩種方式目前在雲計算中應用的比較多。
- CEPHFS則提供了POSIX接口,使用者可直接通過用戶端挂載使用。它是核心态的程式,是以無需調用使用者空間的librados庫。它通過核心中的net子產品來與Rados進行互動。
- RBD塊裝置。對外提供塊存儲。可以像磁盤一樣被映射、格式化已經挂載到伺服器上。支援snapshot。
ceph 的設計思想:
1. 每一元件皆可擴充
2. 無單點故障
3. 基于軟體(而非專業裝置)并且開源(無供應商鎖定)
4. 在現有的廉價硬體上運作
5. 盡可能自動管理,減少使用者幹預
ceph版本:
第一個版本是0.1,釋出時間2008年1月,直到2015年4月0.941釋出之後,為了避免0.99,命名規定如下:
x.0.z 開發版(給早期測試者和勇士們)
x.1.z 候選版(用于測試叢集,高手們)
x.2.z 穩定,修正版(給使用者們)
ceph核心元件以及概念介紹
- Monitors:Ceph Monitor (
ceph-mon
- Managers:Ceph 管理器守護程序 (
ceph-mgr
- Ceph OSD:Ceph OSD(對象存儲守護程序
ceph-osd
- MDS:Ceph 中繼資料伺服器(MDS,
ceph-mds
ls
find
- Libradio:Librados是Rados提供庫,因為RADOS是協定很難直接通路,是以上層的RBD、RGW和CephFS都是通過librados通路的,目前提供PHP、Ruby、Java、Python、C和C++支援。
- CRUSH:CRUSH是Ceph使用的資料分布算法,類似一緻性哈希,讓資料配置設定到預期的地方。
- RBD:RBD全稱RADOS block device,是Ceph對外提供的塊裝置服務。
- PG:PG全稱PlacementGrouops,是一個邏輯的概念,一個PG包含多個OSD。引入PG這一層其實是為了更好的配置設定資料和定位資料。
- RADOS cluster:由多台 host 存儲伺服器組成的 ceph 叢集。
- Object:Ceph最底層的存儲單元是Object對象,每個Object包含中繼資料和原始資料。
- Ceph 将資料作為對象存儲在邏輯存儲池中。使用 CRUSH算法,Ceph 計算出哪個歸置組應該包含該對象,并進一步計算出哪個 Ceph OSD Daemon 應該存儲該歸置組。CRUSH 算法使 Ceph 存儲叢集能夠動态擴充、重新平衡和恢複。
ceph的管理節點:
1.ceph的常用管理接口是一組指令行工具程式,例如rados,ceph,rdb等指令,ceph管理者可以從某個特定的ceph-mon節點執行管理操作。
2.推薦使用部署專用的管理節點對ceph進行配置管理,更新與後期維護,友善後期權限管理,管理節點的權限隻對管理人員開放,可以避免一些不必要的誤操作的發生。
邏輯組織架構:
Pool:存儲池、分區,存儲池的大小取決于底層的存儲空間。 PG(placement group):一個 pool 内部可以有多個 PG 存在,pool 和 PG 都是抽象的邏輯概 念,一個 pool 中有多少個 PG 可以通過公式計算。 OSD(Object Storage Daemon,對象儲存設備):每一塊磁盤都是一個 osd,一個主機由一個或 多個 osd 組成.
ceph 叢集部署好之後,要先建立存儲池才能向 ceph 寫入資料,檔案在向 ceph 儲存之前要 先進行一緻性 hash 計算,計算後會把檔案儲存在某個對應的 PG 的,此檔案一定屬于某個 pool 的一個 PG,在通過 PG 儲存在 OSD 上。 資料對象在寫到主 OSD 之後再同步對從 OSD 以實作資料的高可用。
ceph的資料讀寫流程:
1. 正常IO流程圖:

步驟:
- client 建立cluster handler。
- client 讀取配置檔案。
- client 連接配接上monitor,擷取叢集map資訊。
- client 讀寫io 根據crshmap 算法請求對應的主osd資料節點。
- 主osd資料節點同時寫入另外兩個副本節點資料。
- 等待主節點以及另外兩個副本節點寫完資料狀态。
- 主節點及副本節點寫入狀态都成功後,傳回給client,io寫入完成。
2. 新主IO流程圖:
說明:如果新加入的OSD1取代了原有的 OSD4成為 Primary OSD, 由于 OSD1 上未建立 PG , 不存在資料,那麼 PG 上的 I/O 無法進行,怎樣工作的呢?
步驟:
- client連接配接monitor擷取叢集map資訊。
- 同時新主osd1由于沒有pg資料會主動上報monitor告知讓osd2臨時接替為主。
- 臨時主osd2會把資料全量同步給新主osd1。
- client IO讀寫直接連接配接臨時主osd2進行讀寫。
- osd2收到讀寫io,同時寫入另外兩副本節點。
- 等待osd2以及另外兩副本寫入成功。
- osd2三份資料都寫入成功傳回給client, 此時client io讀寫完畢。
- 如果osd1資料同步完畢,臨時主osd2會交出主角色。
- osd1成為主節點,osd2變成副本。
Ceph IO算法流程:
注:存儲檔案過程:
第一步: 計算檔案到對象的映射:
計算檔案到對象的映射,假如 file 為用戶端要讀寫的檔案,得到 oid(object id) = ino + ono
ino:inode number (INO),File 的中繼資料序列号,File 的唯一 id。
ono:object number (ONO),File 切分産生的某個 object 的序号,預設以 4M 切分一個塊大小。
第二步:通過hash算法計算出檔案對應的pool中的PG:
通過一緻性HASH計算Object 到 PG,Object->PG映射 hash(oid) & mask-> pgid
第三步: 通過CRUSH把對象映射到 PG 中的 OSD
通過 CRUSH 算法計算 PG 到 OSD,PG -> OSD 映射: [CRUSH(pgid)->(osd1,osd2,osd3)]
第四步:PG 中的主 OSD 将對象寫入到硬碟 第五步: 主 OSD 将資料同步給備份 OSD,并等待備份 OSD 傳回确認 第六步: 主 OSD 将寫入完成傳回給用戶端
三、部署ceph叢集:
# 使用ceph-deploy安裝一個最少三個節點的ceph叢集
3台機器:
系統版本:| Ubuntu 18.04.5 LTS
機器配置:| 1核CPU 2G記憶體 系統盤40G + 3塊50G資料磁盤
IP位址以及角色規劃:
公網:121.41.15.24 | 内網:172.16.13.198 ceph-deploy ceph-node1 ceph-mon1 ceph-mgr1
公網:121.41.109.168 | 内網:172.16.13.199 ceph-node2 ceph-mgr2
公網: 121.41.104.188 | 内網:172.16.13.200 ceph-node3 ceph-mon3
1. 添加同步伺服器時間計劃任務,三台機器都需要操作。
*/5 * * * * /usr/sbin/ntpdate time1.aliyun.com &> /dev/null
2.修改三台主機主機名
修改主機名,三台主機都操作:
root@ceph_node1:~# hostname
ceph_node1
root@ceph-node2:~# hostname
ceph-node2
root@ceph-node3:~# hostname
ceph-node3
3.三台機器添加内網主機hosts檔案
root@ceph-node1:~# cat /etc/hosts
172.16.13.198 ceph-node1
172.16.13.199 ceph-node2
172.16.13.200 ceph-node3
root@ceph-node2:~# cat /etc/hosts
172.16.13.194 ceph-node1
172.16.13.196 ceph-node3
172.16.13.195 ceph-node2
root@ceph-node3:~# cat /etc/hosts
4. 修改下載下傳源,三台機器上都操作:
root@ceph-node1:~# wget -q -O- 'https://mirror.tuna.tsinghua.edu.cn/ceph/keys/release.asc' | sudo apt-key add -
OK
root@ceph-node2:~# wget -q -O- 'https://mirror.tuna.tsinghua.edu.cn/ceph/keys/release.asc' | sudo apt-key add -
root@ceph-node3:~# wget -q -O- 'https://mirror.tuna.tsinghua.edu.cn/ceph/keys/release.asc' | sudo apt-key add -
root@ceph-node1:~# echo "deb https://mirrors.tuna.tsinghua.edu.cn/ceph/debian-pacific bionic main" >>/etc/apt/sources.list
root@ceph-node2:~# echo "deb https://mirrors.tuna.tsinghua.edu.cn/ceph/debian-pacific bionic main" >>/etc/apt/sources.list
root@ceph-node3:~# echo "deb https://mirrors.tuna.tsinghua.edu.cn/ceph/debian-pacific bionic main" >>/etc/apt/sources.list
然後,執行一下更新:
root@ceph-node1:~# apt update
root@ceph-node2:~# apt update
root@ceph-node3:~# apt update
5. 建立ceph使用者,三個機器都操作:
root@ceph-node1:~# groupadd -r -g 2022 dev && useradd -r -m -s /bin/bash -u 2022 -g 2022 dev && echo dev:123456 | chpasswd
root@ceph-node2:~# groupadd -r -g 2022 dev && useradd -r -m -s /bin/bash -u 2022 -g 2022 dev && echo dev:123456 | chpasswd
root@ceph-node3:~# groupadd -r -g 2022 dev && useradd -r -m -s /bin/bash -u 2022 -g 2022 dev && echo dev:123456 | chpasswd
6. 三個node節點允許ceph使用者以sudo執行特權指令:
root@ceph-node1:~# echo "dev ALL=(ALL) NOPASSWD: ALL" >> /etc/sudoers
root@ceph-node2:~# echo "dev ALL=(ALL) NOPASSWD: ALL" >> /etc/sudoers
root@ceph-node3:~# echo "dev ALL=(ALL) NOPASSWD: ALL" >> /etc/sudoers
7. ceph-node1機器上,生成秘鑰 # 隻需在ceph-node1 172.16.13.194 這台機器上操作
# 切換到ecph,生成秘鑰
root@ceph-node1:~# su - dev
dev@ceph-node1:~$ ssh-keygen
8. 配置免秘鑰登入,隻需要在 ceph-node1 172.16.13.198 上操作
在 ceph-deploy 節點配置允許以非互動的方式登入到各 ceph node/mon/mgr 節點, 即在 ceph-deploy 節點生成秘鑰對,然後分發公鑰到各被管理節點:
dev@ceph-node1:~$ ssh-copy-id [email protected]
dev@ceph-node1:~$ ssh-copy-id [email protected]
9. ceph-node1機器上,安裝ceph-deploy部署工具:
在 ceph 部署伺服器安裝部署工具 ceph-deploy
dev@ceph-node1:~$ apt-cache madison ceph-deploy
ceph-deploy | 2.0.1 | https://mirrors.tuna.tsinghua.edu.cn/ceph/debian-pacific bionic/main amd64 Packages
ceph-deploy | 2.0.1 | https://mirrors.tuna.tsinghua.edu.cn/ceph/debian-pacific bionic/main i386 Packages
ceph-deploy | 1.5.38-0ubuntu1 | http://mirrors.cloud.aliyuncs.com/ubuntu bionic/universe amd64 Packages
ceph-deploy | 1.5.38-0ubuntu1 | http://mirrors.cloud.aliyuncs.com/ubuntu bionic/universe i386 Packages
ceph-deploy | 1.5.38-0ubuntu1 | http://mirrors.cloud.aliyuncs.com/ubuntu bionic/universe Sources
dev@ceph-node1:~$ mkdir ceph-cluster && cd ceph-cluster # 儲存目前叢集的初始化配置資訊
dev@ceph-node1:~$ sudo apt install ceph-deploy
10. 初始化 mon 節點過程如下:
# 所有mon節點機器,都需要單獨安裝Python2 ,root下安裝
root@ceph-node1:~# apt install python2.7 -y
root@ceph-node2:~# apt install python2.7 -y
root@ceph-node3:~# apt install python2.7 -y
做軟連接配接, # 如果存在python2,會提示已存在
root@ceph-node1:~# ln -sv /usr/bin/python2.7 /usr/bin/python2
ln: failed to create symbolic link '/usr/bin/python2': File exists
11. 叢集初始化(第一個mon節點——ceph-node01): # ceph-node1 其實就是 ceph-mon1
驗證初始化:# 因為我的機器是阿裡雲,外網是彈性IP,隻有一個沒網網卡,兩個網絡我都寫成了内網
dev@ceph-node1:~$ cd ceph-cluster/
dev@ceph-node1:~/ceph-cluster$ ceph-deploy new --cluster-network 172.16.0.0/20 --public-network 172.16.0.0/20 ceph-node1
dev@ceph-node1:~/ceph-cluster$ ls -ll
total 12
-rw-rw-r-- 1 dev dev 264 Sep 6 00:23 ceph.conf # 自動生成的配置檔案
-rw-rw-r-- 1 dev dev 3148 Sep 6 00:23 ceph-deploy-ceph.log # 初始化日志
-rw------- 1 dev dev 73 Sep 6 00:23 ceph.mon.keyring # 用于ceph mon 節點内部通訊認證的秘鑰環檔案
dev@ceph-node1:~/ceph-cluster$ cat ceph.conf
[global]
fsid = 34d1e4ee-f5cc-438b-9465-03bb1e7653fe
public_network = 172.16.0.0/20
cluster_network = 172.16.0.0/20
mon_initial_members = ceph-node1
mon_host = 172.16.13.198
auth_cluster_required = cephx
auth_service_required = cephx
auth_client_required = cephx
12. 到mon-1節點伺服器上,裝一個ceph-mon的包
dev@ceph-node1:~$ cd /home/dev/ceph-cluster/
dev@ceph-node1:~/ceph-cluster$ sudo apt install ceph-mon
13. 初始化mon節點:
dev@ceph-node1:~/ceph-cluster$ ceph-deploy mon create-initial
14. 初始化mon伺服器
ssh root@localhost
root@ceph-node1:~# apt install ceph-common -y
dev@ceph-node1:~$ ceph -s
2021-09-06T00:44:41.938+0800 7f2bb7cd0700 -1 auth: unable to find a keyring on /etc/ceph/ceph.client.admin.keyring,/etc/ceph/ceph.keyring,/etc/ceph/keyring,/etc/ceph/keyring.bin,: (2) No such file or directory
2021-09-06T00:44:41.938+0800 7f2bb7cd0700 -1 AuthRegistry(0x7f2bb005b2a8) no keyring found at /etc/ceph/ceph.client.admin.keyring,/etc/ceph/ceph.keyring,/etc/ceph/keyring,/etc/ceph/keyring.bin,, disabling cephx
2021-09-06T00:44:41.938+0800 7f2bb7cd0700 -1 AuthRegistry(0x7f2bb005eef0) no keyring found at /etc/ceph/ceph.client.admin.keyring,/etc/ceph/ceph.keyring,/etc/ceph/keyring,/etc/ceph/keyring.bin,, disabling cephx
2021-09-06T00:44:41.938+0800 7f2bb7cd0700 -1 AuthRegistry(0x7f2bb7ccf000) no keyring found at /etc/ceph/ceph.client.admin.keyring,/etc/ceph/ceph.keyring,/etc/ceph/keyring,/etc/ceph/keyring.bin,, disabling cephx
[errno 2] RADOS object not found (error connecting to the cluster)
配置認證: 推送配置檔案和認證的key到需要認證的用戶端(在ceph-deploy節點執行)
15. 推送/etc/ceph/ceph.client.admin.keyring檔案到node1上;
dev@ceph-node1:~/ceph-cluster$ sudo ceph-deploy admin ceph-node1
dev@ceph-node1:~/ceph-cluster$ sudo setfacl -m u:dev:rw /etc/ceph/ceph.client.admin.keyring
sudo: setfacl: command not found
dev@ceph-node1:~/ceph-cluster$ sudo apt-get install acl
重新推送配置檔案到ceph-node1機器上;
檢查ceph指令:
dev@ceph-node1:~/ceph-cluster$ ceph -s
cluster:
id: 34d1e4ee-f5cc-438b-9465-03bb1e7653fe
health: HEALTH_WARN
mon is allowing insecure global_id reclaim
services:
mon: 1 daemons, quorum ceph-node1 (age 19m)
mgr: no daemons active
osd: 0 osds: 0 up, 0 in
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 0 B used, 0 B / 0 B avail
pgs:
18. 安裝配置mgr高可用(一主兩備)
dev@ceph-node1:~/ceph-cluster$ ceph-deploy mgr create ceph-node1
檢查mgr服務是否啟動,預設是開機自啟動
dev@ceph-node1:~/ceph-cluster$ ps -ef|grep mgr|grep -v grep
ceph 19974 1 9 00:53 ? 00:00:07 /usr/bin/ceph-mgr -f --cluster ceph --id ceph-node1 --setuser ceph --setgroup ceph
19. 初始化ceph存儲節點:
在添加 osd之前,對node節點安裝基本環境:
# 注意 ceph-node2和ceph-node3機器的ssh要設定成允許root登入。
dev@ceph-node1:~/ceph-cluster$ sudo ceph-deploy install --no-adjust-repos --nogpgcheck ceph-node1 ceph-node2 ceph-node3
20. 禁用不安全模式:
dev@ceph-node1:~/ceph-cluster$ ceph config set mon auth_allow_insecure_global_id_reclaim false
OSD count 0 < osd_pool_default_size 3
mon: 1 daemons, quorum ceph-node1 (age 28m)
mgr: ceph-node1(active, since 5m)
21. 準備OSD節點
osd節點安裝運作環境:
dev@ceph-node1:~/ceph-cluster$ sudo ceph-deploy install --release pacific ceph-node1 ceph-node2 ceph-node3
22. 列出ceph node節點磁盤:
dev@ceph-node1:~/ceph-cluster$ ceph-deploy disk list ceph-node1 ceph-node2 ceph-node3
[ceph_deploy.conf][DEBUG ] found configuration file at: /home/dev/.cephdeploy.conf
[ceph_deploy.cli][INFO ] Invoked (2.0.1): /usr/bin/ceph-deploy disk list ceph-node1 ceph-node2 ceph-node3
[ceph_deploy.cli][INFO ] ceph-deploy options:
[ceph_deploy.cli][INFO ] username : None
[ceph_deploy.cli][INFO ] verbose : False
[ceph_deploy.cli][INFO ] debug : False
[ceph_deploy.cli][INFO ] overwrite_conf : False
[ceph_deploy.cli][INFO ] subcommand : list
[ceph_deploy.cli][INFO ] quiet : False
[ceph_deploy.cli][INFO ] cd_conf : <ceph_deploy.conf.cephdeploy.Conf instance at 0x7f935faff460>
[ceph_deploy.cli][INFO ] cluster : ceph
[ceph_deploy.cli][INFO ] host : ['ceph-node1', 'ceph-node2', 'ceph-node3']
[ceph_deploy.cli][INFO ] func : <function disk at 0x7f935fad62d0>
[ceph_deploy.cli][INFO ] ceph_conf : None
[ceph_deploy.cli][INFO ] default_release : False
[ceph-node1][DEBUG ] connection detected need for sudo
[ceph-node1][DEBUG ] connected to host: ceph-node1
[ceph-node1][DEBUG ] detect platform information from remote host
[ceph-node1][DEBUG ] detect machine type
[ceph-node1][DEBUG ] find the location of an executable
[ceph-node1][INFO ] Running command: sudo fdisk -l
[ceph-node1][INFO ] Disk /dev/vda: 40 GiB, 42949672960 bytes, 83886080 sectors
[ceph-node1][INFO ] Disk /dev/vdb: 50 GiB, 53687091200 bytes, 104857600 sectors
[ceph-node1][INFO ] Disk /dev/vdc: 50 GiB, 53687091200 bytes, 104857600 sectors
[ceph-node1][INFO ] Disk /dev/vdd: 50 GiB, 53687091200 bytes, 104857600 sectors
[ceph-node2][DEBUG ] connection detected need for sudo
[ceph-node2][DEBUG ] connected to host: ceph-node2
[ceph-node2][DEBUG ] detect platform information from remote host
[ceph-node2][DEBUG ] detect machine type
[ceph-node2][DEBUG ] find the location of an executable
[ceph-node2][INFO ] Running command: sudo fdisk -l
[ceph-node2][INFO ] Disk /dev/vda: 40 GiB, 42949672960 bytes, 83886080 sectors
[ceph-node2][INFO ] Disk /dev/vdb: 50 GiB, 53687091200 bytes, 104857600 sectors
[ceph-node2][INFO ] Disk /dev/vdc: 50 GiB, 53687091200 bytes, 104857600 sectors
[ceph-node2][INFO ] Disk /dev/vdd: 50 GiB, 53687091200 bytes, 104857600 sectors
[ceph-node3][DEBUG ] connection detected need for sudo
[ceph-node3][DEBUG ] connected to host: ceph-node3
[ceph-node3][DEBUG ] detect platform information from remote host
[ceph-node3][DEBUG ] detect machine type
[ceph-node3][DEBUG ] find the location of an executable
[ceph-node3][INFO ] Running command: sudo fdisk -l
[ceph-node3][INFO ] Disk /dev/vda: 40 GiB, 42949672960 bytes, 83886080 sectors
[ceph-node3][INFO ] Disk /dev/vdb: 50 GiB, 53687091200 bytes, 104857600 sectors
[ceph-node3][INFO ] Disk /dev/vdc: 50 GiB, 53687091200 bytes, 104857600 sectors
[ceph-node3][INFO ] Disk /dev/vdd: 50 GiB, 53687091200 bytes, 104857600 sectors
23. 擦除磁盤:
dev@ceph-node1:~/ceph-cluster$ sudo ceph-deploy disk zap ceph-node1 /dev/vdb
dev@ceph-node1:~/ceph-cluster$ sudo ceph-deploy disk zap ceph-node1 /dev/vdc
dev@ceph-node1:~/ceph-cluster$ sudo ceph-deploy disk zap ceph-node1 /dev/vdd
dev@ceph-node1:~/ceph-cluster$ sudo ceph-deploy disk zap ceph-node2 /dev/vdb
dev@ceph-node1:~/ceph-cluster$ sudo ceph-deploy disk zap ceph-node2 /dev/vdc
dev@ceph-node1:~/ceph-cluster$ sudo ceph-deploy disk zap ceph-node2 /dev/vdd
dev@ceph-node1:~/ceph-cluster$ sudo ceph-deploy disk zap ceph-node3 /dev/vdb
dev@ceph-node1:~/ceph-cluster$ sudo ceph-deploy disk zap ceph-node3 /dev/vdc
dev@ceph-node1:~/ceph-cluster$ sudo ceph-deploy disk zap ceph-node3 /dev/vdd
24. 添加主機的磁盤
dev@ceph-node1:~/ceph-cluster$ sudo ceph-deploy osd create ceph-node1 --data /dev/vdb
dev@ceph-node1:~/ceph-cluster$ sudo ceph-deploy osd create ceph-node1 --data /dev/vdc
dev@ceph-node1:~/ceph-cluster$ sudo ceph-deploy osd create ceph-node1 --data /dev/vdd
dev@ceph-node1:~/ceph-cluster$ sudo ceph-deploy osd create ceph-node2 --data /dev/vdb
dev@ceph-node1:~/ceph-cluster$ sudo ceph-deploy osd create ceph-node2 --data /dev/vdc
dev@ceph-node1:~/ceph-cluster$ sudo ceph-deploy osd create ceph-node2 --data /dev/vdd
dev@ceph-node1:~/ceph-cluster$ sudo ceph-deploy osd create ceph-node3 --data /dev/vdb
dev@ceph-node1:~/ceph-cluster$ sudo ceph-deploy osd create ceph-node3 --data /dev/vdc
dev@ceph-node1:~/ceph-cluster$ sudo ceph-deploy osd create ceph-node3 --data /dev/vdd
25. 檢查node1上的osd
dev@ceph-node1:~/ceph-cluster$ ps -ef|grep osd|grep -v grep
ceph 26422 1 0 20:11 ? 00:00:06 /usr/bin/ceph-osd -f --cluster ceph --id 0 --setuser ceph --setgroup ceph
ceph 27936 1 0 20:12 ? 00:00:05 /usr/bin/ceph-osd -f --cluster ceph --id 1 --setuser ceph --setgroup ceph
ceph 29450 1 0 20:13 ? 00:00:05 /usr/bin/ceph-osd -f --cluster ceph --id 2 --setuser ceph --setgroup ceph
26. 設定開機自啟動,在ceph-node1上操作。
dev@ceph-node1:~/ceph-cluster$ systemctl enable ceph-osd@0 ceph-osd@1 ceph-osd@2 ceph-osd@3 ceph-osd@4 ceph-osd@5 ceph-osd@6 ceph-osd@7 ceph-osd@8
health: HEALTH_OK
mon: 1 daemons, quorum ceph-node1 (age 87m)
mgr: ceph-node1(active, since 100m)
osd: 9 osds: 9 up (since 24m), 9 in (since 24m)
pools: 1 pools, 1 pgs
usage: 53 MiB used, 450 GiB / 450 GiB avail
pgs: 1 active+clean
27. 從RADOS移除OSD:
1).停用裝置0:
dev@ceph-node1:~/ceph-cluster$ ceph osd out 0
marked out osd.0.
2)停止程序:sudo systemctl stop ceph-osd@{osd-num}
dev@ceph-node1:~/ceph-cluster$ sudo systemctl stop ceph-osd@0
3)移除裝置:# ceph osd purge {id} --yes-i-really-mean-it
dev@ceph-node1:~/ceph-cluster$ ceph osd purge 0 --yes-i-really-mean-it
purged osd.0
檢查ceph叢集的狀态
mon: 1 daemons, quorum ceph-node1 (age 90m)
mgr: ceph-node1(active, since 103m)
osd: 8 osds: 8 up (since 64s), 8 in (since 91s)
usage: 48 MiB used, 400 GiB / 400 GiB avail
28. 測試上傳于下載下傳資料。
dev@ceph-node1:~/ceph-cluster$ ceph osd pool create mypool 32 32
pool 'mypool' created
dev@ceph-node1:~/ceph-cluster$ ceph pg ls-by-pool mypool | awk '{print $1,$2,$15}'
PG OBJECTS ACTING
2.0 0 [3,6,1]p3
2.1 0 [3,1,6]p3
2.2 0 [5,1,8]p5
2.3 0 [5,7,1]p5
2.4 0 [1,3,7]p1
2.5 0 [8,2,4]p8
2.6 0 [1,6,3]p1
2.7 0 [3,7,2]p3
2.8 0 [3,7,1]p3
2.9 0 [1,4,8]p1
2.a 0 [6,1,5]p6
2.b 0 [8,5,2]p8
2.c 0 [6,1,5]p6
2.d 0 [6,3,2]p6
2.e 0 [2,8,3]p2
2.f 0 [8,4,2]p8
2.10 0 [8,1,5]p8
2.11 0 [4,1,8]p4
2.12 0 [7,1,3]p7
2.13 0 [7,4,1]p7
2.14 0 [3,7,1]p3
2.15 0 [7,1,3]p7
2.16 0 [5,7,1]p5
2.17 0 [5,6,2]p5
2.18 0 [8,4,2]p8
2.19 0 [2,4,7]p2
2.1a 0 [3,8,2]p3
2.1b 0 [6,5,2]p6
2.1c 0 [8,4,1]p8
2.1d 0 [7,3,2]p7
2.1e 0 [2,7,5]p2
2.1f 0 [2,3,8]p2
* NOTE: afterwards
dev@ceph-node1:~/ceph-cluster$ ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.39038 root default
-3 0.09760 host ceph-node1
1 hdd 0.04880 osd.1 up 1.00000 1.00000
2 hdd 0.04880 osd.2 up 1.00000 1.00000
-5 0.14639 host ceph-node2
3 hdd 0.04880 osd.3 up 1.00000 1.00000
4 hdd 0.04880 osd.4 up 1.00000 1.00000
5 hdd 0.04880 osd.5 up 1.00000 1.00000
-7 0.14639 host ceph-node3
6 hdd 0.04880 osd.6 up 1.00000 1.00000
7 hdd 0.04880 osd.7 up 1.00000 1.00000
8 hdd 0.04880 osd.8 up 1.00000 1.00000
29. 檢視存儲池數量
dev@ceph-node1:~/ceph-cluster$ ceph osd pool ls
device_health_metrics
mypool
dev@ceph-node1:~$ sudo rados put message /var/log/ceph/ceph-mon.ceph-node1.log --pool=mypool
dev@ceph-node1:~$ rados ls --pool=mypool
message
dev@ceph-node1:~$ ceph osd map mypool message
osdmap e64 pool 'mypool' (2) object 'message' -> pg 2.9de550b3 (2.13) -> up ([7,4,1], p7) acting ([7,4,1], p7)
30.上傳檔案
dev@ceph-node1:~$ sudo rados put msg1 /etc/passwd --pool=mypool
31.下載下傳檔案
dev@ceph-node1:~$ sudo rados get msg1 --pool=mypool /opt/taokey.txt
32.檢視下載下傳之後的檔案
dev@ceph-node1:~$ tail -3 /opt/taokey.txt
ceph:x:64045:64045:Ceph storage service:/var/lib/ceph:/usr/sbin/nologin
dnsmasq:x:109:65534:dnsmasq,,,:/var/lib/misc:/usr/sbin/nologin
cephadm:x:110:65534:cephadm user for mgr/cephadm,,,:/home/cephadm:/bin/bash
33. 删除檔案:
msg1
dev@ceph-node1:~$ sudo rados rm msg1 --pool=mypool
dev@ceph-node1:~$ sudo rados rm message --pool=mypool
34. mon高可用:# 在ceph-node2和ceph-node3上安裝ceph-mon,然後在deploy部署機器上添加ceph-node2和ceph-node3 mon節點
root@ceph-node2:~# apt install ceph-mon
root@ceph-node3:~# apt install ceph-mon
dev@ceph-node1:~/ceph-cluster$ sudo ceph-deploy mon add ceph-node2
dev@ceph-node1:~/ceph-cluster$ sudo ceph-deploy mon add ceph-node3
檢視mon節點,已經變成了三個mon服務
mon: 3 daemons, quorum ceph-node1,ceph-node2,ceph-node3 (age 13s)
mgr: ceph-node1(active, since 118m)
osd: 8 osds: 8 up (since 15m), 8 in (since 15m)
pools: 2 pools, 33 pgs
usage: 96 MiB used, 400 GiB / 400 GiB avail
pgs: 33 active+clean
36. 部署mgr高可用,擴容2個mgr節點,在ceph-node2和ceph-node3上安裝ceph-mgr。
root@ceph-node2:~# apt install ceph-mgr
root@ceph-node3:~# apt install ceph-mgr
在ceph-deploy部署機器上,添加ceph-node2和ceph-node3 兩個mgr節點。
dev@ceph-node1:~/ceph-cluster$ ceph-deploy mgr create ceph-node2
dev@ceph-node1:~/ceph-cluster$ ceph-deploy mgr create ceph-node3
此時檢視mgr個數,看到一主兩備的mgr,ceph-node1是主節點, ceph-node2, ceph-node3是備節點
mon: 3 daemons, quorum ceph-node1,ceph-node2,ceph-node3 (age 5m)
mgr: ceph-node1(active, since 2h), standbys: ceph-node2, ceph-node3
osd: 8 osds: 8 up (since 20m), 8 in (since 21m)
塊裝置RBD:
RDB是塊存儲的一種,RBD通過librbd庫于OSD進行互動,RBD為KVM等虛拟化技術和服務提供高性能和無限可擴充性的存儲後端,這些系統
依賴于libvirt和QEMU使用程式與RBD進行內建,用戶端基于librbd庫即可将RADOS存儲叢集用作塊裝置,不過,用于rbd的存儲池需要事先
啟用rbd功能并進行初始化,例如下面的指令建立一個名為myrbd1的存儲池,并在啟用rbd功能後對其進行初始化:
1. 建立RBD:
# 建立存儲池,指定pg和pgp的數量,pgp是對存在于PG的資料進行組合存儲,pgp通常等于pg的值。
dev@ceph-node1:~/ceph-cluster$ ceph osd pool create myrbd1 64 64
pool 'myrbd1' created
2. 對存儲池啟用RBD功能
dev@ceph-node1:~/ceph-cluster$ ceph osd pool application enable myrbd1 rbd
enabled application 'rbd' on pool 'myrbd1'
3. 通過RBD指令對存儲池初始化
dev@ceph-node1:~/ceph-cluster$ rbd pool init -p myrbd1
4. 建立并驗證img
dev@ceph-node1:~/ceph-cluster$ rbd create myimg1 --size 5G --pool myrbd1
dev@ceph-node1:~/ceph-cluster$ rbd create myimg2 --size 3G --pool myrbd1 --image-format 2 --image-feature layering
dev@ceph-node1:~/ceph-cluster$ rbd ls --pool myrbd1
myimg1
myimg2
dev@ceph-node1:~/ceph-cluster$ rbd --image myimg1 --pool myrbd1 info
rbd image 'myimg1':
size 5 GiB in 1280 objects
order 22 (4 MiB objects)
snapshot_count: 0
id: d3f587783739
block_name_prefix: rbd_data.d3f587783739
format: 2
features: layering, exclusive-lock, object-map, fast-diff, deep-flatten
op_features:
flags:
create_timestamp: Mon Sep 6 21:17:01 2021
access_timestamp: Mon Sep 6 21:17:01 2021
modify_timestamp: Mon Sep 6 21:17:01 2021
5. 檢視ceph資源的使用情況
dev@ceph-node1:~/ceph-cluster$ ceph df
--- RAW STORAGE ---
CLASS SIZE AVAIL USED RAW USED %RAW USED
hdd 400 GiB 400 GiB 81 MiB 81 MiB 0.02
TOTAL 400 GiB 400 GiB 81 MiB 81 MiB 0.02
--- POOLS ---
POOL ID PGS STORED OBJECTS USED %USED MAX AVAIL
device_health_metrics 1 1 0 B 0 0 B 0 127 GiB
mypool 2 32 0 B 0 0 B 0 127 GiB
myrbd1 3 64 405 B 7 48 KiB 0 127 GiB
6. 用戶端通路塊裝置
[root@ceph-client ~]# yum install epel-release -y
[root@ceph-client ~]# wget https://mirror.tuna.tsinghua.edu.cn/ceph/rpm-15.2.9/el7/noarch/ceph-release-1-1.el7.noarch.rpm
[root@ceph-client ~]# rpm -ivh ceph-release-1-1.el7.noarch.rpm
[root@ceph-client ~]# yum install -y ceph-common
dev@ceph-node1:~/ceph-cluster$ scp ceph.conf ceph.client.admin.keyring [email protected]:/etc/ceph/
[root@ceph-client ~]# ceph -s
mon: 3 daemons, quorum ceph-node1,ceph-node2,ceph-node3 (age 27m)
osd: 8 osds: 8 up (since 42m), 8 in (since 42m)
pools: 3 pools, 97 pgs
objects: 7 objects, 405 B
usage: 81 MiB used, 400 GiB / 400 GiB avail
pgs: 97 active+clean
8. 用戶端映射img:
[root@ceph-client ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
vda 253:0 0 40G 0 disk
└─vda1 253:1 0 40G 0 part /
[root@ceph-client ~]# rbd -p myrbd1 map myimg2
/dev/rbd0
rbd0 252:0 0 3G 0 disk
特性太多了,但是核心版本太低,不支援映射myimg1,報錯如下所示:
[root@ceph-client ~]# rbd -p myrbd1 map myimg1
rbd: sysfs write failed
RBD image feature set mismatch. You can disable features unsupported by the kernel with "rbd feature disable myrbd1/myimg1 object-map fast-diff deep-flatten".
In some cases useful info is found in syslog - try "dmesg | tail".
rbd: map failed: (6) No such device or address
9. 按照提示關閉特性:
[root@ceph-client ~]# rbd feature disable myrbd1/myimg1 object-map fast-diff deep-flatten
10. 關完之後再映射:
[root@ceph-client ~]# rbd -p myrbd1 map myimg1
/dev/rbd1
11. 然後再檢視,會有兩個映射:
rbd1 252:16 0 5G 0 disk
12. 格式化磁盤:
[root@ceph-client ~]# mkfs.ext4 /dev/rbd0
mke2fs 1.42.9 (28-Dec-2013)
Discarding device blocks: 完成
檔案系統标簽=
OS type: Linux
塊大小=4096 (log=2)
分塊大小=4096 (log=2)
Stride=1024 blocks, Stripe width=1024 blocks
196608 inodes, 786432 blocks
39321 blocks (5.00%) reserved for the super user
第一個資料塊=0
Maximum filesystem blocks=805306368
24 block groups
32768 blocks per group, 32768 fragments per group
8192 inodes per group
Superblock backups stored on blocks:
32768, 98304, 163840, 229376, 294912
Allocating group tables: 完成
正在寫入inode表: 完成
Creating journal (16384 blocks): 完成
Writing superblocks and filesystem accounting information: 完成
[root@ceph-client ~]# mkfs.xfs /dev/rbd1
meta-data=/dev/rbd1 isize=512 agcount=8, agsize=163840 blks
= sectsz=512 attr=2, projid32bit=1
= crc=1 finobt=0, sparse=0
data = bsize=4096 blocks=1310720, imaxpct=25
= sunit=1024 swidth=1024 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=1
log =internal log bsize=4096 blocks=2560, version=2
= sectsz=512 sunit=8 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
[root@ceph-client ~]# mount /dev/rbd0 /mnt
[root@ceph-client ~]# mkdir /data/mysql -p
[root@ceph-client ~]# mount /dev/rbd1 /data/mysql
[root@ceph-client ~]# df -Th
檔案系統 類型 容量 已用 可用 已用% 挂載點
devtmpfs devtmpfs 234M 0 234M 0% /dev
tmpfs tmpfs 244M 0 244M 0% /dev/shm
tmpfs tmpfs 244M 456K 244M 1% /run
tmpfs tmpfs 244M 0 244M 0% /sys/fs/cgroup
/dev/vda1 ext4 40G 2.2G 36G 6% /
tmpfs tmpfs 49M 0 49M 0% /run/user/0
/dev/rbd0 ext4 2.9G 9.0M 2.8G 1% /mnt
/dev/rbd1 xfs 5.0G 33M 5.0G 1% /data/mysql
14. 檢查ceph的磁盤空間
[root@ceph-client ~]# ceph df
CLASS SIZE AVAIL USED RAW USED %RAW USED
hdd 400 GiB 399 GiB 548 MiB 548 MiB 0.13
TOTAL 400 GiB 399 GiB 548 MiB 548 MiB 0.13
POOL ID PGS STORED OBJECTS USED %USED MAX AVAIL
device_health_metrics 1 1 0 B 0 0 B 0 126 GiB
mypool 2 32 0 B 0 0 B 0 126 GiB
myrbd1 3 64 76 MiB 43 228 MiB 0.06 126 GiB
到此為止,實驗結束!