LevelDB是Google傳奇工程師Jeff Dean和Sanjay Ghemawat開源的KV存儲引擎,無論從設計還是代碼上都可以用精緻優雅來形容,非常值得細細品味。接下來就将用幾篇部落格來由表及裡的介紹LevelDB的設計和代碼細節。本文将從設計思路、整體結構、讀寫流程、壓縮流程幾個方面來進行介紹,進而能夠對LevelDB有一個整體的感覺。
設計思路
LevelDB的資料是存儲在磁盤上的,采用LSM-Tree的結構實作。LSM-Tree将磁盤的随機寫轉化為順序寫,進而大大提高了寫速度。為了做到這一點LSM-Tree的思路是将索引樹結構拆成一大一小兩顆樹,較小的一個常駐記憶體,較大的一個持久化到磁盤,他們共同維護一個有序的key空間。寫入操作會首先操作記憶體中的樹,随着記憶體中樹的不斷變大,會觸發與磁盤中樹的歸并操作,而歸并操作本身僅有順序寫。如下圖所示:
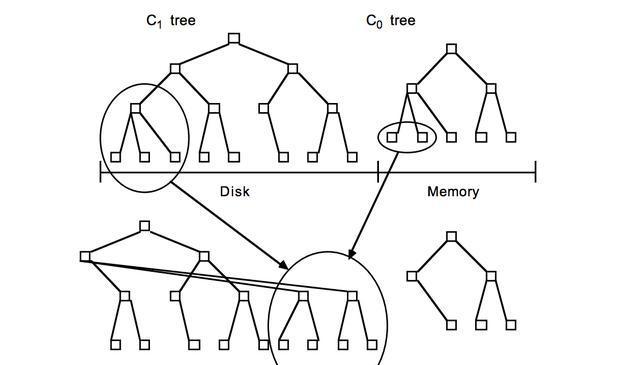
随着資料的不斷寫入,磁盤中的樹會不斷膨脹,為了避免每次參與歸并操作的資料量過大,以及優化讀操作的考慮,LevelDB将磁盤中的資料又拆分成多層,每一層的資料達到一定容量後會觸發向下一層的歸并操作,每一層的資料量比其上一層成倍增長。這也就是LevelDB的名稱來源。
整體結構
具體到代碼實作上,LevelDB有幾個重要的角色,包括對應于上文提到的記憶體資料的Memtable,分層資料存儲的SST檔案,版本控制的Manifest、Current檔案,以及寫Memtable前的WAL。這裡簡單介紹各個元件的作用和在整個結構中的位置,更詳細的介紹将在之後的部落格中進行。
- Memtable:記憶體資料結構,跳表實作,新的資料會首先寫入這裡;
- Log檔案:寫Memtable前會先寫Log檔案,Log通過append的方式順序寫入。Log的存在使得機器當機導緻的記憶體資料丢失得以恢複;
- Immutable Memtable:達到Memtable設定的容量上限後,Memtable會變為Immutable為之後向SST檔案的歸并做準備,顧名思義,Immutable Mumtable不再接受使用者寫入,同時會有新的Memtable生成;
- SST檔案:磁盤資料存儲檔案。分為Level 0到Level N多層,每一層包含多個SST檔案;單層SST檔案總量随層次增加成倍增長;檔案内資料有序;其中Level0的SST檔案由Immutable直接Dump産生,其他Level的SST檔案由其上一層的檔案和本層檔案歸并産生;SST檔案在歸并過程中順序寫生成,生成後僅可能在之後的歸并中被删除,而不會有任何的修改操作。
- Manifest檔案: Manifest檔案中記錄SST檔案在不同Level的分布,單個SST檔案的最大最小key,以及其他一些LevelDB需要的元資訊。
- Current檔案: 從上面的介紹可以看出,LevelDB啟動時的首要任務就是找到目前的Manifest,而Manifest可能有多個。Current檔案簡單的記錄了目前Manifest的檔案名,進而讓這個過程變得非常簡單。

讀寫操作
作為KV資料存儲引擎,基本的讀寫操作是必不可少的,通過對讀寫操作流程的了解,也能讓我們更直覺的窺探其内部實作。
1,寫流程
LevelDB的寫操作包括設定key-value和删除key兩種。需要指出的是這兩種情況在LevelDB的處理上是一緻的,删除操作其實是向LevelDB插入一條辨別為删除的資料。下面就一起看看LevelDB插入值的過程。
LevelDB對外暴露的寫接口包括Put,Delete和Write,其中Write需要WriteBatch作為參數,而Put和Delete首先就是将目前的操作封裝到一個WriteBatch對象,并調用Write接口。這裡的WriteBatch是一批寫操作的集合,其存在的意義在于提高寫入效率,并提供Batch内所有寫入的原子性。
在Write函數中會首先用目前的WriteBatch封裝一個Writer,代表一個完整的寫入請求。LevelDB加鎖保證同一時刻隻能有一個Writer工作。其他Writer挂起等待,直到前一個Writer執行完畢後喚醒。單個Writer執行過程如下:
Status status = MakeRoomForWrite(my_batch == NULL);
uint64_t last_sequence = versions_->LastSequence();
Writer* last_writer = &w;
if (status.ok() && my_batch != NULL) {
WriteBatch* updates = BuildBatchGroup(&last_writer);
WriteBatchInternal::SetSequence(updates, last_sequence + 1);
last_sequence += WriteBatchInternal::Count(updates);
// 将目前的WriteBatch内容寫入Binlog以及Memtable
......
versions_->SetLastSequence(last_sequence);
} - 在MakeRoomForWrite中為目前的寫入準備Memtable空間:Level0層有過多的檔案時,會延緩或挂起目前寫操作;Memtable已經寫滿則嘗試切換到Immutable Memtable,生成新的Memtable供寫入,并觸發背景的Immutable Memtable向Level0 SST檔案的Dump。Immutable Memtable Dump不及時也會挂起目前寫操作。
- BuildBatchGroup中會嘗試将目前等待的所有其他Writer中的寫入合并到目前的WriteBatch中,以提高寫入效率。
- 之後将WriteBatch中内容寫入Binlog并循環寫入Memtable。
- 關注上述代碼的最後一行,在所有的值寫入完成後才将Sequence真正更新,而LevelDB的讀請求又是基于Sequence的。這樣就保證了在WriteBatch寫入過程中,不會被讀請求部分看到,進而提供了原子性。
2,讀流程
- 首先,生成内部查詢所用的Key,該Key是由使用者請求的UserKey拼接上Sequence生成的。其中Sequence可以使用者提供或使用目前最新的Sequence,LevelDB可以保證僅查詢在這個Sequence之前的寫入。
- 用生成的Key,依次嘗試從 Memtable,Immtable以及SST檔案中讀取,直到找到。
- 從SST檔案中查找需要依次嘗試在每一層中讀取,得益于Manifest中記錄的每個檔案的key區間,我們可以很友善的知道某個key是否在檔案中。Level0的檔案由于直接由Immutable Dump 産生,不可避免的會互相重疊,是以需要對每個檔案依次查找。對于其他層次,由于歸并過程保證了其互相不重疊且有序,二分查找的方式提供了更好的查詢效率。
- 可以看出同一個Key出現在上層的操作會屏蔽下層的。也是以删除Key時隻需要在Memtable壓入一條标記為删除的條目即可。被其屏蔽的所有條目會在之後的歸并過程中清除。
-
壓縮操作
資料壓縮是LevelDB中重要的部分,即上文提到的歸并。冷資料會随着Compaction不斷的下移,同時過期的資料也會在合并過程中被删除。LevelDB的壓縮操作由單獨的背景線程負責。這裡的Compaction包括兩個部分,Memtable向Level0 SST檔案的Compaction,以及SST檔案向下層的Compaction,對應于兩個比較重要的函數:
1,CompactMemTable
CompactMemTable會将Immutable中的資料整體Dump為Level 0的一個檔案,這個過程會在Immutable Memtable存在時被Compaction背景線程排程。過程比較簡單,首先會獲得一個Immutable的Iterator用來周遊其中的所有内容,建立一個新的Level 0 SST檔案,并将Iterator讀出的内容依次順序寫入該檔案。之後更新元資訊并删除Immutable Memtable。
2,BackgroundCompaction
- 首先根據觸發Compaction的原因以及維護的相關資訊找到本次要Compact的一個SST檔案。對于Level0的檔案比較特殊,由于Level0的SST檔案由Memtable在不同時間Dump而成,是以可能有Key重疊。是以除該檔案外還需要獲得所有與之重疊的Level0檔案。這時我們得到一個包含一個或多個檔案的檔案集合,處于同一Level。
- SetupOtherInputs: 在Level+1層擷取所有與目前的檔案集合有Key重合的檔案。
- DoCompactionWork:對得到的包含相鄰兩層多個檔案的檔案集合,進行歸并操作并将結果輸出到Level + 1層的一個新的SST檔案,歸并的過程中删除所有過期的資料。
- 删除之前的檔案集合裡的所有檔案。通過上述過程我們可以看到,這個新生成的檔案在其所在Level不會跟任何檔案有Key的重疊。
總結